HNSW, índice plano o invertido: ¿cuál debería elegir para su búsqueda? Este artículo de inteligencia artificial ofrece consejos operativos para recuperadores densos y dispersos

Un desafío importante en la recuperación de información hoy en día es determinar el método más eficiente para la búsqueda de vectores del vecino más cercano, especialmente con la creciente complejidad de los modelos de recuperación densos y dispersos. Los profesionales deben explorar una amplia gama de opciones para los métodos de indexación y recuperación, incluidos los gráficos HNSW (Hierarchical Navigable Small-World), los índices planos y los índices invertidos. Estos métodos ofrecen diferentes compensaciones en términos de velocidad, escalabilidad y calidad de los resultados de recuperación. A medida que los conjuntos de datos se vuelven más grandes y complejos, la ausencia de una guía operativa clara dificulta que los profesionales optimicen sus sistemas, en particular para aplicaciones que requieren un alto rendimiento, como los motores de búsqueda y las aplicaciones impulsadas por IA, como los sistemas de preguntas y respuestas.
Tradicionalmente, la búsqueda del vecino más próximo se maneja utilizando tres enfoques principales: índices HNSW, índices planos e índices invertidos. Los índices HNSW se utilizan comúnmente por su eficiencia y velocidad en tareas de recuperación a gran escala, particularmente con vectores densos, pero son computacionalmente intensivos y requieren un tiempo de indexación significativo. Los índices planos, si bien son exactos en sus resultados de recuperación, se vuelven poco prácticos para conjuntos de datos grandes debido a un rendimiento de consulta más lento. Los modelos de recuperación dispersa, como BM25 o SPLADE++ ED, se basan en índices invertidos y pueden ser efectivos en escenarios específicos, pero a menudo carecen de la rica comprensión semántica proporcionada por los modelos de recuperación densos. La principal limitación de estos enfoques es que ninguno es universalmente aplicable, y cada método ofrece diferentes fortalezas y debilidades según el tamaño del conjunto de datos y la recuperación.
Investigadores de la Universidad de Waterloo presentan una evaluación exhaustiva de las ventajas y desventajas entre los índices HNSW, planos e invertidos para los modelos de recuperación densos y dispersos. Esta investigación proporciona un análisis detallado del rendimiento de estos métodos, medido por el tiempo de indexación, la velocidad de consulta (QPS) y la calidad de recuperación (nDCG@10), utilizando el conjunto de datos de referencia BEIR. Los investigadores pretenden ofrecer asesoramiento práctico basado en datos sobre el uso óptimo de cada método en función del tamaño del conjunto de datos y los requisitos de recuperación. Sus hallazgos indican que HNSW es muy eficiente para conjuntos de datos a gran escala, mientras que los índices planos son más adecuados para conjuntos de datos más pequeños debido a su simplicidad y resultados exactos. Además, el estudio explora los beneficios de utilizar técnicas de cuantificación para mejorar la escalabilidad y la velocidad del proceso de recuperación, lo que ofrece una mejora significativa para los profesionales que trabajan con grandes conjuntos de datos.
La configuración experimental utiliza el parámetro de referencia BEIR, una colección de 29 conjuntos de datos diseñados para reflejar los desafíos de recuperación de información del mundo real. El modelo de recuperación densa utilizado es BGE (Base General Embeddings), con SPLADE++ ED y BM25 como líneas de base para la recuperación dispersa. La evaluación se centra en dos tipos de índices de recuperación densa: HNSW, que construye estructuras basadas en gráficos para la búsqueda del vecino más cercano, e índices planos, que se basan en la búsqueda de fuerza bruta. Los índices invertidos se utilizan para los modelos de recuperación dispersa. Las evaluaciones se llevan a cabo utilizando la biblioteca de búsqueda Lucene, con configuraciones específicas como M=16 para HNSW. El rendimiento se evalúa utilizando métricas clave como nDCG@10 y QPS, y el rendimiento de las consultas se evalúa en dos condiciones: consultas en caché (codificación de consultas precalculada) y codificación de consultas en tiempo real basada en ONNX.
Los resultados revelan que, en el caso de conjuntos de datos más pequeños (menos de 100 000 documentos), los índices planos y HNSW muestran un rendimiento comparable en términos de velocidad de consulta y calidad de recuperación. Sin embargo, a medida que aumenta el tamaño de los conjuntos de datos, los índices HNSW comienzan a superar significativamente a los índices planos, en particular en términos de velocidad de evaluación de consultas. En el caso de conjuntos de datos grandes que superan el millón de documentos, los índices HNSW ofrecen consultas por segundo (QPS) mucho más altas, con solo una disminución marginal en la calidad de recuperación (nDCG@10). Cuando se trata de conjuntos de datos de más de 15 millones de documentos, los índices HNSW demuestran mejoras sustanciales en la velocidad, manteniendo al mismo tiempo una precisión de recuperación aceptable. Las técnicas de cuantificación mejoran aún más el rendimiento, en particular en conjuntos de datos grandes, ofreciendo aumentos notables en la velocidad de consulta sin una reducción significativa en la calidad. En general, los métodos de recuperación densos que utilizan HNSW demuestran ser mucho más efectivos y eficientes que los modelos de recuperación dispersa, en particular para aplicaciones a gran escala que requieren un alto rendimiento.
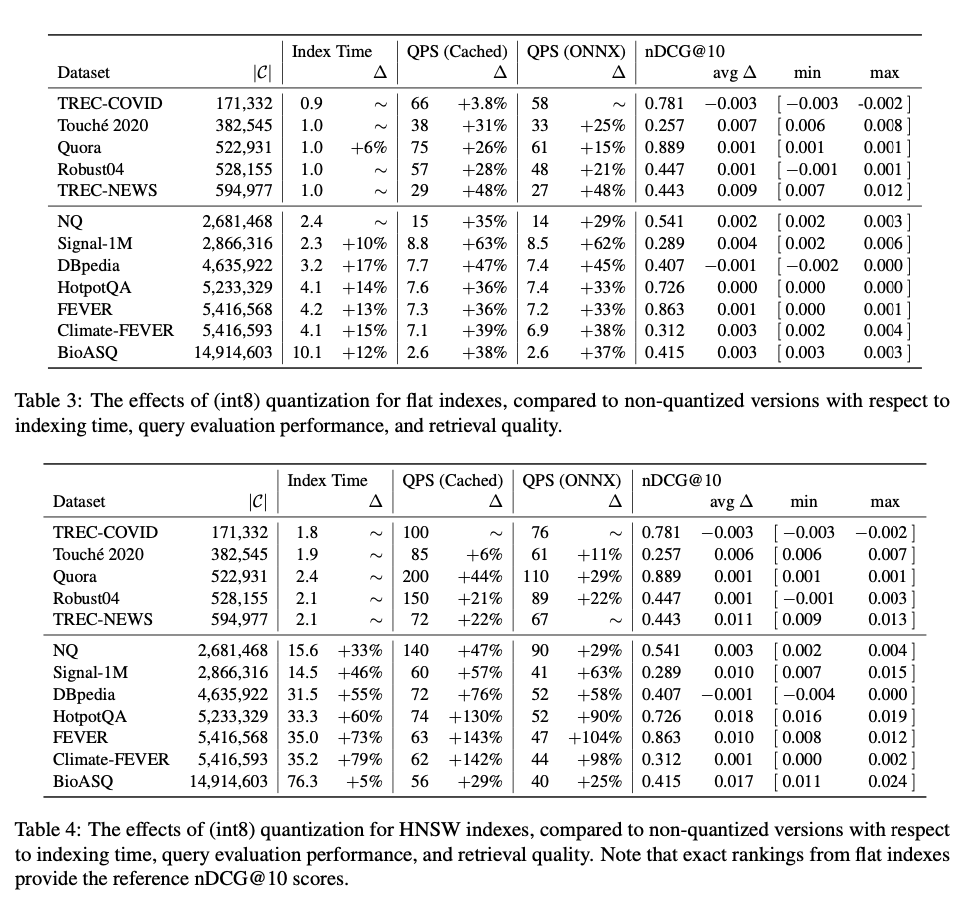
Esta investigación ofrece una guía esencial para los profesionales de la recuperación densa y dispersa, proporcionando una evaluación integral de las ventajas y desventajas entre los índices HNSW, planos e invertidos. Los hallazgos sugieren que los índices HNSW son adecuados para tareas de recuperación a gran escala debido a su eficiencia en el manejo de consultas, mientras que los índices planos son ideales para conjuntos de datos más pequeños y creación rápida de prototipos debido a su simplicidad y precisión. Al proporcionar recomendaciones con respaldo empírico, este trabajo contribuye significativamente a la comprensión y optimización de los sistemas de recuperación de información modernos, ayudando a los profesionales a tomar decisiones informadas para aplicaciones de búsqueda impulsadas por IA.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasionan la ciencia de datos y el aprendizaje automático, y cuenta con una sólida formación académica y experiencia práctica en la resolución de desafíos reales interdisciplinarios.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)