Embedić lanza un conjunto de modelos de incrustación de texto en serbio optimizados para la recuperación de información y RAG

Novak Zivanic ha hecho una contribución significativa al campo del procesamiento del lenguaje natural con el lanzamiento de Embedicun conjunto de modelos de incrustación de texto en serbio. Estos modelos están diseñados específicamente para tareas de recuperación de información y generación aumentada de recuperación (RAG). En concreto, el modelo más pequeño del conjunto ha logrado una hazaña notable, superando el rendimiento de vanguardia anterior utilizando 5 veces menos parámetros. Este avance demuestra la eficiencia y la eficacia de los modelos Embedić en el manejo de tareas de procesamiento del idioma serbio.
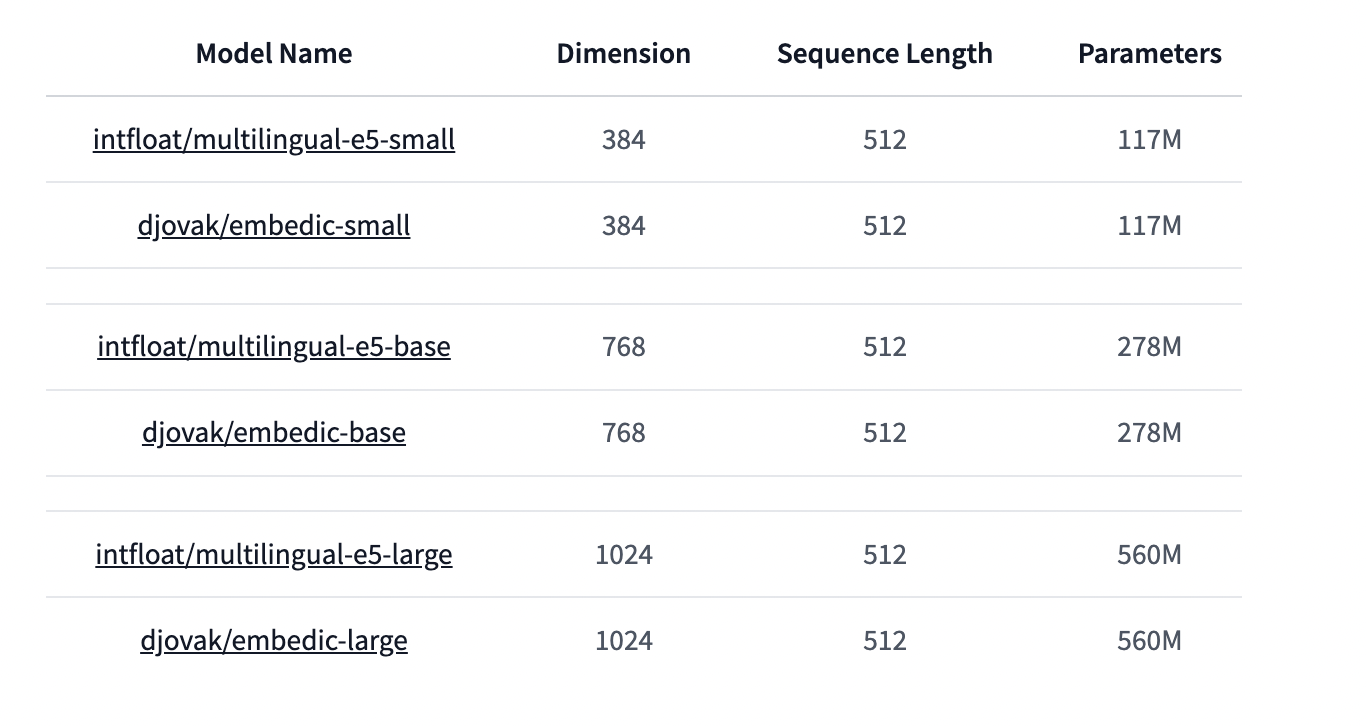
Los modelos de Embedić están optimizados a partir de modelos multilingües e5 y vienen en tres tamaños (pequeño, básico y grande).
La suite Embedić demuestra una versatilidad impresionante en sus capacidades lingüísticas. Si bien está especializada en serbio, e incluye tanto alfabetos cirílicos como latinos, estos modelos también exhiben funcionalidad multilingüe, entendiendo también el inglés. Esta característica permite a los usuarios incrustar documentos en inglés, serbio o una combinación de ambos idiomas. Utilizando el marco de trabajo de los transformadores de oraciones, Embedić asigna oraciones y párrafos a un Espacio vectorial denso de 786 dimensionesEsta representación hace que los modelos sean particularmente útiles para tareas como agrupamiento y búsqueda semántica, mejorando sus aplicaciones prácticas en diversos contextos lingüísticos.
Al utilizar Embedić, es fundamental tener en cuenta algunas pautas de uso importantes. El uso de “ošišana latinica” (escritura latina simplificada sin diacríticos) puede reducir significativamente la calidad de la búsqueda, por lo que se recomienda utilizar la ortografía serbia correcta. Además, el uso de letras mayúsculas para las entidades nombradas puede mejorar notablemente los resultados de la búsqueda.
La suite Embedić ofrece tres tamaños de modelo: pequeño, básico y grande, todos ajustados a partir de modelos multilingües e5. El proceso de entrenamiento, realizado en una única GPU 4070ti Super, implica un enfoque de tres pasos: destilación, entrenamiento en pares (consulta, texto) y ajuste final con tripletes.
Los modelos Embedić se sometieron a una evaluación rigurosa en tres tareas críticas: recuperación de información, similitud de oraciones y minería de bits. Para garantizar una evaluación integral, se invirtieron importantes esfuerzos y recursos en la creación de conjuntos de datos adecuados en idioma serbio. El desarrollador tradujo personalmente el conjunto de datos de evaluación multilingüe STS17, lo que demuestra un compromiso con la precisión. Además de esto, se realizó una inversión sustancial de $6000 en la API de traducción de Google para convertir cuatro conjuntos de datos de evaluación de recuperación de información al serbio. Este enfoque meticuloso para la preparación de los conjuntos de datos subraya la minuciosidad del proceso de evaluación y la posible eficacia de los modelos en las tareas en idioma serbio.
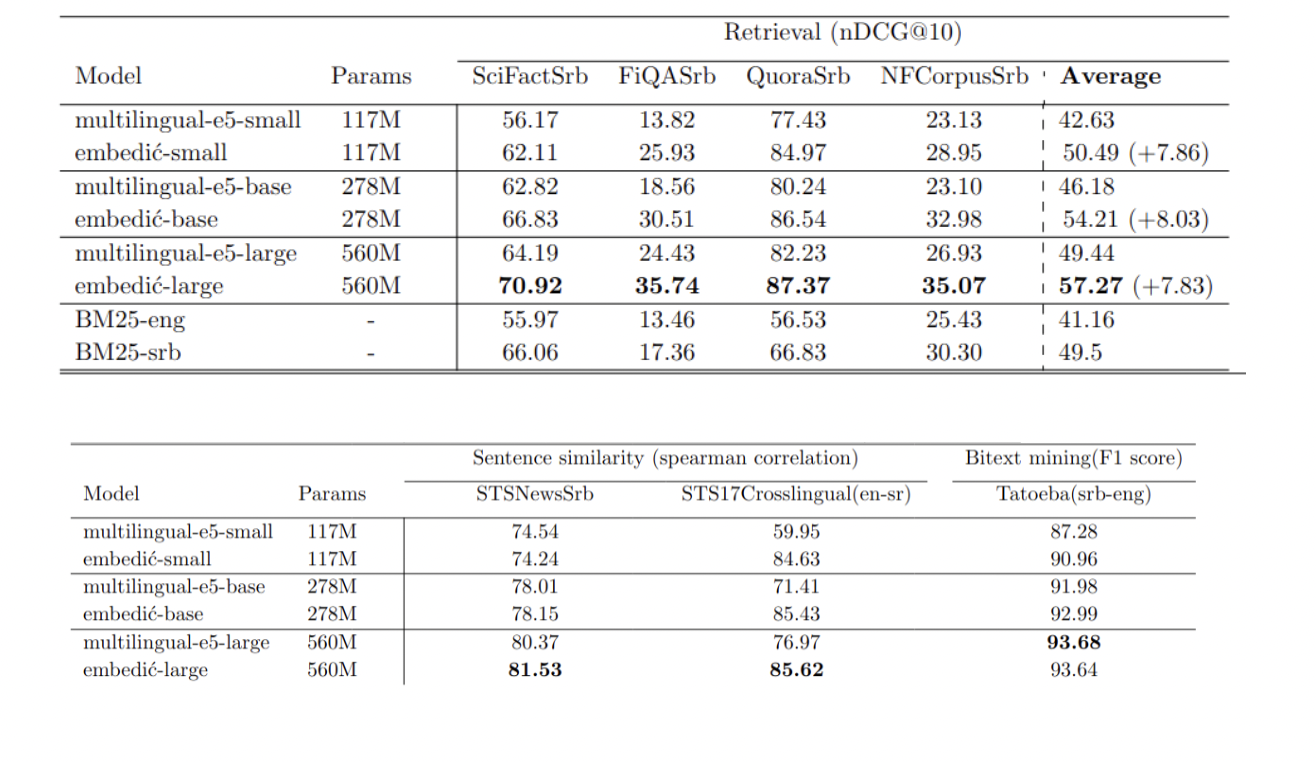
El lanzamiento de Embedić marca un avance significativo en el procesamiento del idioma serbio. Desarrollado por Novak Zivanic, este conjunto de modelos de incrustación de texto ofrece un rendimiento de vanguardia para tareas de recuperación de información y RAG, y el modelo más pequeño supera a los puntos de referencia anteriores utilizando una cantidad significativamente menor de parámetros. Los modelos, disponibles en tres tamaños, están optimizados a partir de multilingual-e5 y ofrecen capacidades multilingües, ya que comprenden tanto el serbio (escrituras cirílicas y latinas) como el inglés.
Embedić utiliza el marco de trabajo de los transformadores de oraciones, que asignan el texto a un espacio vectorial de 786 dimensiones, lo que lo hace ideal para tareas de búsqueda semántica y de agrupamiento. El proceso de desarrollo implicó una capacitación y una evaluación meticulosas, incluidos esfuerzos personales de traducción y una inversión sustancial en la creación de conjuntos de datos serbios completos.
Echa un vistazo a la Tarjeta modelo en HF.. Todo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc. Como ingeniero y emprendedor visionario, Asif está comprometido con aprovechar el potencial de la inteligencia artificial para el bien social. Su iniciativa más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad de noticias sobre aprendizaje automático y aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)