¿La rotación descontrolada está frenando el rendimiento de su IA? Este artículo sobre IA revela CHAIN: Mejorar el aprendizaje por refuerzo profundo reduciendo el efecto de cadena de la rotación de valor y políticas

El aprendizaje por refuerzo profundo (DRL, por sus siglas en inglés) enfrenta un desafío crítico debido a la inestabilidad causada por la “rotación” durante el entrenamiento. La rotación se refiere a cambios impredecibles en el resultado de las redes neuronales para estados que no están incluidos en el lote de entrenamiento. Este problema es particularmente problemático en el aprendizaje por refuerzo (RL, por sus siglas en inglés) debido a su naturaleza inherentemente no estacionaria, donde las políticas y las funciones de valor evolucionan continuamente a medida que se introducen nuevos datos. La rotación conduce a inestabilidades significativas en el aprendizaje, lo que causa actualizaciones erráticas tanto de las estimaciones de valor como de las políticas, lo que puede resultar en un entrenamiento ineficiente, un rendimiento subóptimo e incluso fallas catastróficas. Abordar este desafío es esencial para mejorar la confiabilidad del DRL en entornos complejos, lo que permite el desarrollo de sistemas de IA más robustos en aplicaciones del mundo real como la conducción autónoma, la robótica y la atención médica.
Los métodos actuales para mitigar la inestabilidad en DRL, como los algoritmos basados en valores (por ejemplo, DoubleDQN) y los métodos basados en políticas (por ejemplo, Optimización de Políticas Proximales, PPO), apuntan a estabilizar el aprendizaje a través de técnicas como el control del sesgo de sobreestimación y la aplicación de la región de confianza. Sin embargo, estos enfoques no logran abordar la rotación de manera efectiva. Por ejemplo, DoubleDQN sufre desviaciones de acción voraces debido a cambios en las estimaciones de valores, mientras que PPO puede violar silenciosamente su región de confianza debido a la rotación de políticas. Estos métodos existentes pasan por alto el efecto compuesto de la rotación entre valores y actualizaciones de políticas, lo que resulta en una eficiencia de muestra reducida y un desempeño deficiente, especialmente en tareas de toma de decisiones a gran escala.
Investigadores de la Universidad de Montreal presentan la estrategia de reducción aproximada de la pérdida de clientes (CHAIN, por sus siglas en inglés). Esta estrategia apunta específicamente a la reducción de la pérdida de clientes por valor y por políticas mediante la introducción de pérdidas de regularización durante el entrenamiento. CHAIN reduce los cambios no deseados en las salidas de la red para los estados no incluidos en el lote actual, lo que controla de manera efectiva la pérdida de clientes en diferentes configuraciones de DRL. Al minimizar el efecto de la pérdida de clientes, este método mejora la estabilidad de los algoritmos de RL basados en valores y en políticas. La innovación radica en la simplicidad del método y su capacidad para integrarse fácilmente en la mayoría de los algoritmos de DRL existentes con modificaciones mínimas del código. La capacidad de controlar la pérdida de clientes conduce a un aprendizaje más estable y una mejor eficiencia de la muestra en una variedad de entornos de RL.
El método CHAIN introduce dos términos de regularización principales: la pérdida por reducción de abandono de valores (L_QC) y la pérdida por reducción de abandono de políticas (L_PC). Estos términos se calculan utilizando un lote de datos de referencia y reducen los cambios en los resultados de valor de la red Q y los resultados de acción de la red de políticas, respectivamente. Esta reducción se logra comparando los resultados actuales con los de la iteración anterior de la red. El método se evalúa utilizando múltiples puntos de referencia de DRL, incluidos MinAtar, OpenAI MuJoCo, DeepMind Control Suite y conjuntos de datos fuera de línea como D4RL. La regularización está diseñada para ser liviana y se aplica junto con las funciones de pérdida estándar utilizadas en el entrenamiento de DRL, lo que la hace muy versátil para una amplia gama de algoritmos, incluidos DoubleDQN, PPO y SAC.
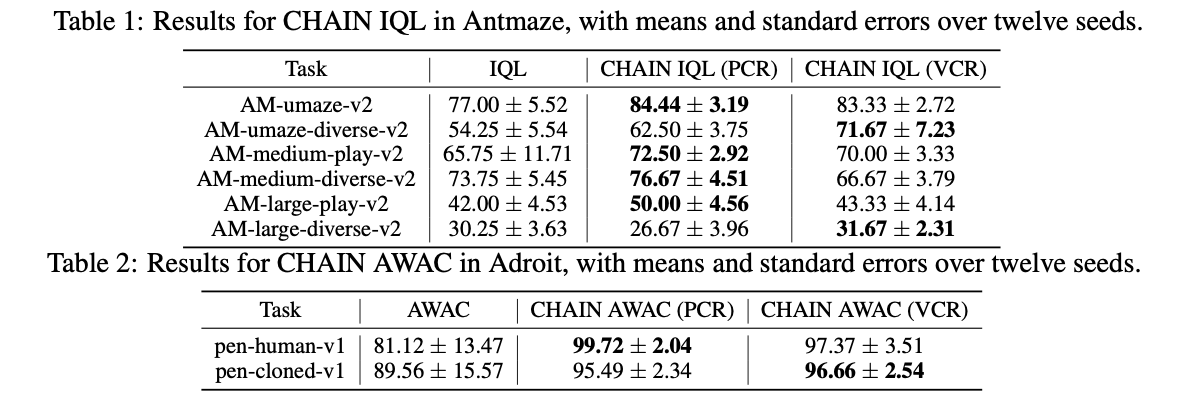
CHAIN mostró mejoras significativas tanto en la reducción de la pérdida de estudiantes como en la mejora del rendimiento del aprendizaje en varios entornos de aprendizaje por refuerzo. En tareas como Breakout de MinAtar, la integración de CHAIN con DoubleDQN condujo a una marcada reducción en la pérdida de estudiantes, lo que resultó en una mejora en la eficiencia de la muestra y un mejor rendimiento general en comparación con los métodos de referencia. De manera similar, en entornos de control continuo como Ant-v4 y HalfCheetah-v4 de MuJoCo, la aplicación de CHAIN a PPO mejoró la estabilidad y los retornos finales, superando las configuraciones de PPO estándar. Estos hallazgos demuestran que CHAIN mejora la estabilidad de la dinámica de entrenamiento, lo que conduce a un aprendizaje más confiable y eficiente en una variedad de escenarios de aprendizaje por refuerzo, con ganancias de rendimiento consistentes tanto en entornos de aprendizaje por refuerzo en línea como fuera de línea.
El método CHAIN aborda un desafío fundamental en el aprendizaje por refuerzo (RL) al reducir el efecto desestabilizador de la rotación de personal. Al controlar la rotación de personal tanto en términos de valor como de políticas, el enfoque garantiza actualizaciones más estables durante el entrenamiento, lo que conduce a una mayor eficiencia de la muestra y un mejor desempeño final en varias tareas de RL. La capacidad de CHAIN de incorporarse fácilmente a algoritmos existentes, con modificaciones mínimas, lo convierte en una solución práctica para un problema crítico en el aprendizaje por refuerzo. Esta innovación tiene el potencial de mejorar significativamente la solidez y la escalabilidad de los sistemas DRL, particularmente en entornos reales a gran escala.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasionan la ciencia de datos y el aprendizaje automático, y cuenta con una sólida formación académica y experiencia práctica en la resolución de desafíos reales interdisciplinarios.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)