¿Podemos optimizar modelos de lenguaje grandes más rápido que Adam? Este artículo sobre IA de Harvard revela cómo SOAP mejorará y estabilizará Shampoo en el aprendizaje profundo

La optimización eficiente de modelos de aprendizaje profundo a gran escala sigue siendo un desafío importante a medida que el costo de entrenamiento de modelos de lenguaje grandes (LLM) continúa aumentando. A medida que los modelos se hacen más grandes, la carga computacional y el tiempo requerido para el entrenamiento aumentan sustancialmente, lo que crea una demanda de optimizadores más eficientes que puedan reducir tanto el tiempo de entrenamiento como los recursos. Este desafío es particularmente importante para reducir la sobrecarga en aplicaciones de IA del mundo real y hacer que el entrenamiento de modelos a gran escala sea más factible.
Los métodos de optimización actuales incluyen optimizadores de primer orden como Adán y métodos de segundo orden como Champú. Mientras Adán se utiliza ampliamente por su eficiencia computacional, a menudo converge más lentamente, especialmente en regímenes de lotes grandes. Por el contrario, Champú ofrece un rendimiento superior al utilizar preacondicionadores factorizados por Kronecker en capas, pero presenta una gran complejidad computacional, ya que requiere una frecuente descomposición de características propias e introduce varios hiperparámetros adicionales. Esto limita la escalabilidad y la eficiencia de Shampoo, en particular en aplicaciones a gran escala y en tiempo real.
Los investigadores de la Universidad de Harvard proponen JABÓN (ShampoO con Adam en la base propia del preacondicionador) para superar las limitaciones del champú. SOAP integra las fortalezas de Adán y Champú Al correr Adán sobre la base de los preacondicionadores de Shampoo, lo que reduce la sobrecarga computacional. Este enfoque minimiza la necesidad de operaciones de matriz frecuentes y reduce la cantidad de hiperparámetros, ya que SOAP introduce solo un hiperparámetro adicional (frecuencia de preacondicionamiento) en comparación con Adam. Este nuevo método mejora tanto la eficiencia como el rendimiento del entrenamiento sin comprometer la precisión.
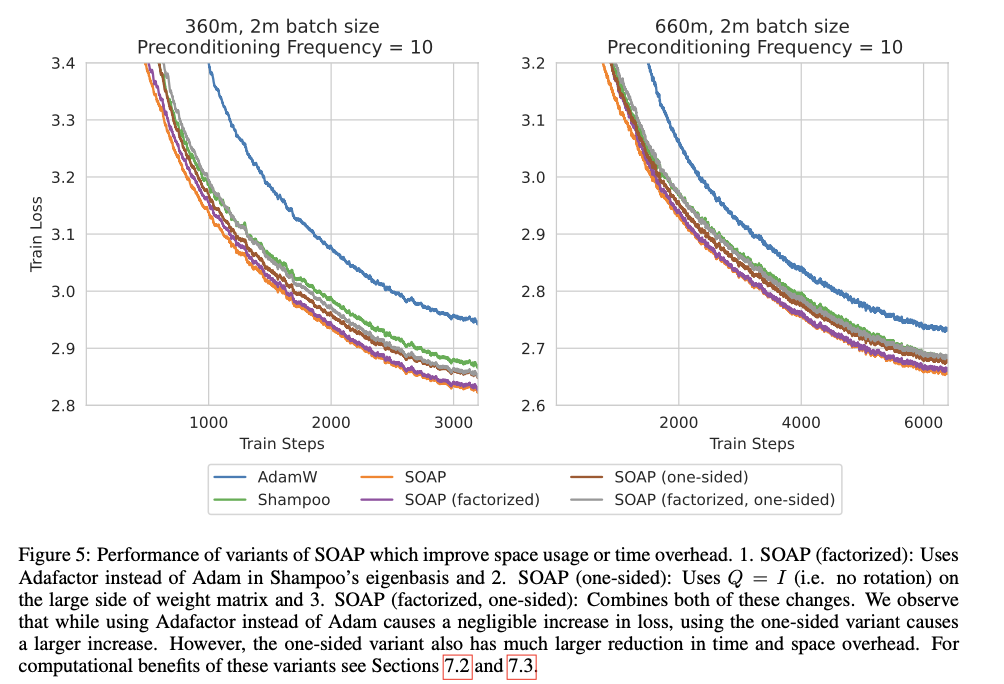
SOAP modifica el optimizador tradicional de Shampoo actualizando los preacondicionadores con menor frecuencia y ejecutando las actualizaciones de Adam en un espacio rotado definido por los preacondicionadores de Shampoo. Mantiene dos preacondicionadores para la matriz de peso de cada capa y los actualiza en función de una frecuencia de preacondicionamiento optimizada. En la configuración experimental, SOAP se probó en modelos con parámetros de 360M y 660M en tareas de entrenamiento de lotes grandes. La frecuencia de preacondicionamiento y otros hiperparámetros se optimizaron para garantizar que SOAP maximizara tanto el rendimiento como la eficiencia, manteniendo una alta precisión y reduciendo significativamente la sobrecarga computacional.

SOAP demostró mejoras sustanciales en el rendimiento y la eficiencia, reduciendo las iteraciones de entrenamiento en un 40 % y el tiempo de respuesta en un 35 % en comparación con AdamW. Además, logró un rendimiento un 20 % mejor que Shampoo en ambas métricas. Estas mejoras fueron consistentes en diferentes tamaños de modelo, y SOAP mantuvo o superó los puntajes de pérdida de prueba de AdamW y Shampoo. Esto resalta la capacidad de SOAP para equilibrar la eficiencia del entrenamiento con el rendimiento del modelo, lo que lo convierte en una herramienta poderosa para la optimización del aprendizaje profundo a gran escala.
En conclusión, JABÓN presenta un avance significativo en la optimización del aprendizaje profundo al combinar la eficiencia computacional de Adán con los beneficios de segundo orden de ChampúAl reducir la sobrecarga computacional y minimizar la complejidad de los hiperparámetros, SOAP ofrece una solución altamente escalable y eficiente para entrenar modelos grandes. La capacidad del método para reducir tanto las iteraciones de entrenamiento como el tiempo de respuesta sin sacrificar el rendimiento subraya su potencial para convertirse en un estándar práctico para optimizar modelos de IA a gran escala, lo que contribuye a un entrenamiento de aprendizaje profundo más eficiente y factible.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasionan la ciencia de datos y el aprendizaje automático, y cuenta con una sólida formación académica y experiencia práctica en la resolución de desafíos reales interdisciplinarios.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)