LASR: Un nuevo enfoque de aprendizaje automático para la regresión simbólica utilizando modelos de lenguaje de gran tamaño

La regresión simbólica es un método computacional avanzado para encontrar ecuaciones matemáticas que expliquen mejor un conjunto de datos. A diferencia de la regresión tradicional, que ajusta los datos a modelos predefinidos, la regresión simbólica busca las estructuras matemáticas subyacentes desde cero. Este enfoque ha ganado prominencia en campos científicos como la física, la química y la biología, donde los investigadores buscan descubrir leyes fundamentales que rigen los fenómenos naturales. Al producir ecuaciones interpretables, la regresión simbólica permite a los científicos explicar patrones en los datos de manera más intuitiva, lo que la convierte en una herramienta valiosa en la búsqueda más amplia del descubrimiento científico automatizado.
Un desafío clave en la regresión simbólica es el enorme espacio de búsqueda de hipótesis potenciales. A medida que aumenta la complejidad de los datos, el número de soluciones posibles crece exponencialmente, lo que hace que sea computacionalmente prohibitivo realizar una búsqueda eficaz. Los enfoques tradicionales, como los algoritmos genéticos, se basan en mutaciones aleatorias y cruces para desarrollar soluciones, pero a menudo necesitan ayuda con la escalabilidad y la eficiencia. Como resultado, existe una necesidad urgente de métodos más eficientes para manejar conjuntos de datos más grandes sin comprometer la precisión o la interpretabilidad, impulsando así los avances en el descubrimiento científico.
Existen varios métodos que intentan abordar este problema, cada uno con sus limitaciones. Los algoritmos genéticos, que utilizan procesos que imitan la evolución natural para explorar el espacio de búsqueda, siguen siendo los más comunes. Sin embargo, estas técnicas suelen ser aleatorias y no pueden incorporar conocimientos específicos del dominio, lo que ralentiza la búsqueda de soluciones útiles. Se han empleado otros métodos, como la búsqueda guiada por neuronas o el aprendizaje de refuerzo profundo, pero aún necesitan escalabilidad. Estos enfoques suelen requerir amplios recursos computacionales y pueden no ser prácticos para aplicaciones científicas del mundo real.
Investigadores de la Universidad de Texas en Austin, el MIT, Foundry Technologies y la Universidad de Cambridge desarrollaron un nuevo método llamado LASR (regresión simbólica abstracta aprendida). Este enfoque innovador combina la regresión simbólica tradicional con grandes modelos de lenguaje (LLM) para introducir un nuevo nivel de eficiencia y precisión. Los investigadores diseñaron LASR para construir una biblioteca de conceptos abstractos y reutilizables que sirvan de guía para el proceso de generación de hipótesis. Al aprovechar los LLM, el método reduce la dependencia de pasos evolutivos aleatorios e introduce un mecanismo impulsado por el conocimiento que dirige la búsqueda hacia soluciones más relevantes.
La metodología LASR está estructurada en tres fases clave. En la primera fase, la evolución de la hipótesis, se aplican operaciones genéticas como mutación y cruce al conjunto de hipótesis. Sin embargo, a diferencia de los métodos tradicionales, estas operaciones están condicionadas a conceptos abstractos generados por LLM. En la segunda fase, las hipótesis de mayor rendimiento se resumen en conceptos textuales. Estos conceptos se almacenan en una biblioteca para sesgar la búsqueda de hipótesis en iteraciones posteriores. En la fase final, la evolución del concepto, los conceptos almacenados se refinan y evolucionan utilizando operaciones adicionales guiadas por LLM. Este bucle iterativo entre la abstracción del concepto y la evolución de la hipótesis acelera la búsqueda de soluciones precisas e interpretables. El método garantiza que se utilice el conocimiento previo y evolucione junto con las hipótesis que se están probando.
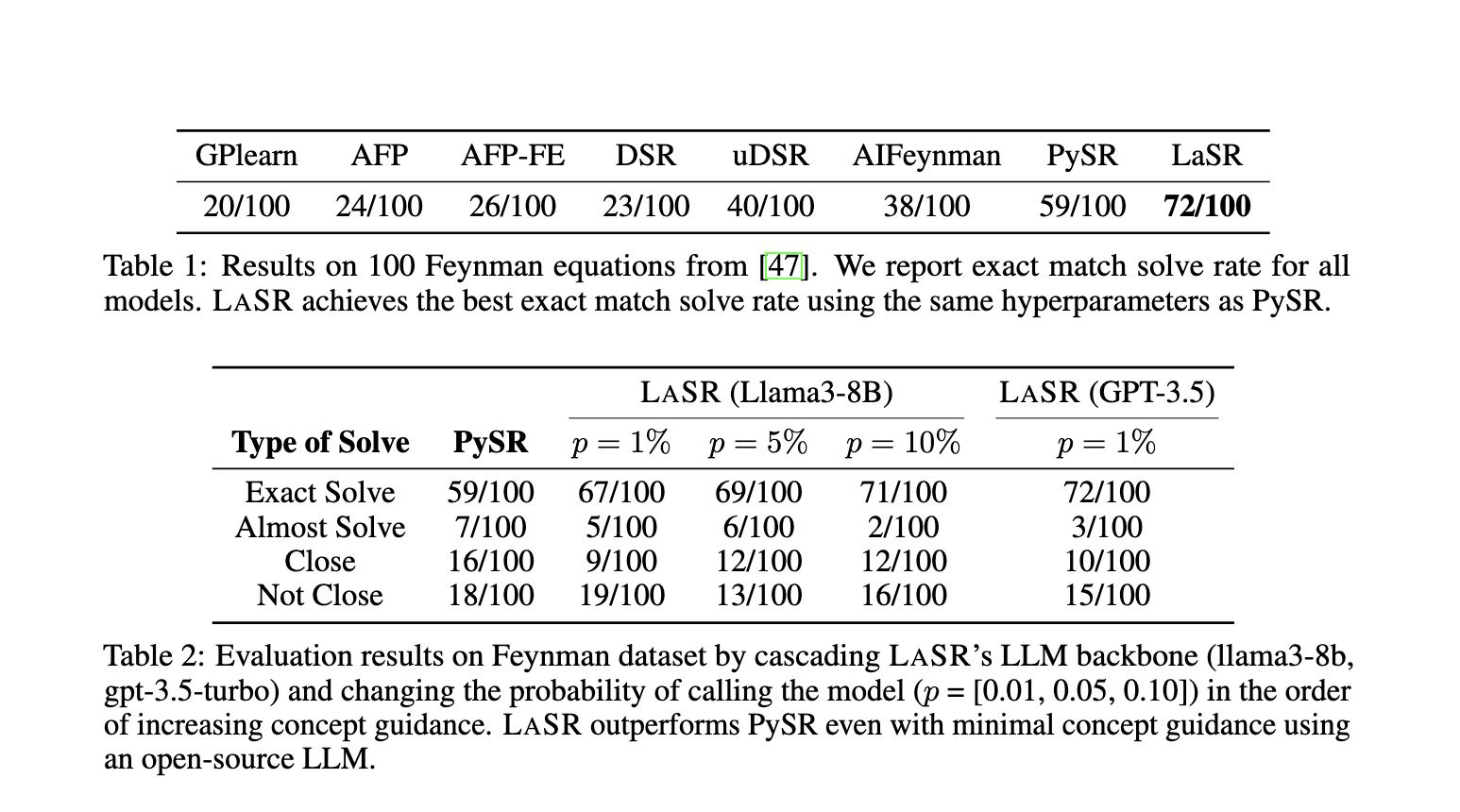
El rendimiento de LASR se probó en una variedad de puntos de referencia, incluidas las ecuaciones de Feynman, que consisten en 100 ecuaciones físicas extraídas de las famosas *Conferencias de Feynman sobre Física*. LASR superó significativamente los enfoques de regresión simbólica de última generación en estas pruebas. Mientras que los mejores métodos tradicionales resolvieron 59 de 100 ecuaciones, LASR descubrió con éxito 66. Esta es una mejora notable, en particular si se tiene en cuenta que el método se probó con los mismos hiperparámetros que sus competidores. Además, en los puntos de referencia sintéticos diseñados para simular tareas de descubrimiento científico del mundo real, LASR mostró constantemente un rendimiento superior en comparación con los métodos de referencia. Los resultados subrayan la eficiencia de combinar LLM con algoritmos evolutivos para mejorar la regresión simbólica.
Un hallazgo clave del método LASR fue su capacidad para descubrir nuevas leyes de escalamiento para modelos lingüísticos grandes, un aspecto crucial para mejorar el rendimiento de los LLM. Por ejemplo, LASR identificó una nueva ley de escalamiento al analizar datos de la suite de evaluación BIG-Bench, un punto de referencia para los LLM. El equipo de investigación descubrió que aumentar la cantidad de ejemplos en contexto durante el entrenamiento del modelo mejora exponencialmente el rendimiento de los modelos con pocos recursos, pero esta ganancia disminuye a medida que avanza el entrenamiento. Este nuevo descubrimiento demuestra la utilidad más amplia de LASR más allá de la regresión simbólica, lo que podría influir en el desarrollo futuro de los LLM.
En general, el método LASR representa un avance significativo en la regresión simbólica. Al introducir un enfoque basado en el conocimiento y guiado por conceptos, ofrece una solución a los problemas de escalabilidad que han afectado durante mucho tiempo a los métodos tradicionales. El uso de LLM para generar conceptos abstractos proporciona un nuevo nivel de eficiencia, lo que permite que el método converja más rápido en ecuaciones precisas e interpretables. El éxito de LASR al superar a los métodos existentes en las pruebas de referencia y descubrir nuevos conocimientos sobre las leyes de escalamiento de LLM destaca su potencial para impulsar avances en la regresión simbólica y el aprendizaje automático.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Nikhil es consultor en prácticas en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA y el aprendizaje automático que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de los materiales, está explorando nuevos avances y creando oportunidades para contribuir.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)