Microsoft lanza GRIN MoE: un modelo MoE basado en gradientes y basado en la combinación de expertos para un aprendizaje profundo eficiente y escalable

La investigación en inteligencia artificial (IA) se ha centrado cada vez más en mejorar la eficiencia y la escalabilidad de los modelos de aprendizaje profundo. Estos modelos han revolucionado el procesamiento del lenguaje natural, la visión artificial y el análisis de datos, pero presentan importantes desafíos computacionales. En concreto, a medida que los modelos se hacen más grandes, requieren grandes recursos computacionales para procesar conjuntos de datos inmensos. Las técnicas como la retropropagación son esenciales para entrenar estos modelos optimizando sus parámetros. Sin embargo, los métodos tradicionales tienen dificultades para escalar los modelos de aprendizaje profundo de manera eficiente sin causar cuellos de botella en el rendimiento ni requerir una potencia computacional excesiva.
Uno de los principales problemas de los modelos de aprendizaje profundo actuales es su dependencia de un cálculo denso, que activa todos los parámetros del modelo de manera uniforme durante el entrenamiento y la inferencia. Este método es ineficiente cuando se procesan datos a gran escala, lo que da como resultado la activación innecesaria de recursos que pueden no ser relevantes para la tarea en cuestión. Además, la naturaleza no diferenciable de algunos componentes de estos modelos dificulta la aplicación de la optimización basada en gradientes, lo que limita la eficacia del entrenamiento. A medida que los modelos continúan escalando, superar estos desafíos es crucial para avanzar en el campo de la IA y permitir sistemas más potentes y eficientes.
Los enfoques actuales para escalar los modelos de IA suelen incluir modelos densos y dispersos que emplean mecanismos de enrutamiento expertos. Los modelos densos, como GPT-3 y GPT-4, activan todas las capas y parámetros para cada entrada, lo que hace que requieran muchos recursos y sean difíciles de escalar. Los modelos dispersos, que apuntan a activar solo un subconjunto de parámetros en función de los requisitos de entrada, han demostrado ser prometedores para reducir las demandas computacionales. Sin embargo, los métodos existentes como GShard y Switch Transformers aún dependen en gran medida del paralelismo experto y emplean técnicas como la eliminación de tokens para administrar la distribución de recursos. Si bien son efectivos, estos métodos tienen desventajas en la eficiencia del entrenamiento y el rendimiento del modelo.
Los investigadores de Microsoft han presentado una solución innovadora para estos desafíos con GRIN (GRadient-INformed Mixture of Experts). Este enfoque tiene como objetivo abordar las limitaciones de los modelos dispersos existentes mediante la introducción de un nuevo método de estimación de gradiente para el enrutamiento de expertos. GRIN mejora el paralelismo del modelo, lo que permite un entrenamiento más eficiente sin la necesidad de eliminar tokens, un problema común en la computación dispersa. Al aplicar GRIN a los modelos de lenguaje autorregresivo, los investigadores han desarrollado un modelo de mezcla de expertos de los 2 primeros con 16 expertos por capa, conocido como el modelo GRIN MoE. Este modelo activa selectivamente a los expertos en función de la entrada, lo que reduce significativamente la cantidad de parámetros activos y, al mismo tiempo, mantiene un alto rendimiento.
El modelo GRIN MoE emplea varias técnicas avanzadas para lograr su impresionante rendimiento. La arquitectura del modelo incluye capas MoE, donde cada capa consta de 16 expertos, y solo los 2 superiores se activan para cada token de entrada, utilizando un mecanismo de enrutamiento. Cada experto se implementa como una red GLU (Gated Linear Unit), lo que permite que el modelo equilibre la eficiencia computacional y la potencia expresiva. Los investigadores introdujeron SparseMixer-v2, un componente clave que estima gradientes relacionados con el enrutamiento de expertos, reemplazando los métodos convencionales que utilizan gradientes de compuerta como indicadores. Esto permite que el modelo escale sin depender de la eliminación de tokens o el paralelismo de expertos, que es común en otros modelos dispersos.
El rendimiento del modelo GRIN MoE se ha probado rigurosamente en una amplia gama de tareas, y los resultados demuestran su eficiencia y escalabilidad superiores. En el benchmark MMLU (Massive Multitask Language Understanding), el modelo obtuvo una impresionante puntuación de 79,4, superando a varios modelos densos de tamaños similares o mayores. También logró una puntuación de 83,7 en HellaSwag, un benchmark para el razonamiento de sentido común, y 74,4 en HumanEval, que mide la capacidad del modelo para resolver problemas de codificación. Cabe destacar que el rendimiento del modelo en MATH, un benchmark para el razonamiento matemático, fue de 58,9, lo que refleja su fortaleza en tareas especializadas. El modelo GRIN MoE utiliza solo 6.6 mil millones de parámetros activados durante la inferencia, que es menos que los 7 mil millones de parámetros activados de los modelos densos de la competencia, pero iguala o supera su rendimiento. En otra comparación, GRIN MoE superó a un modelo con una densidad de parámetros de 7 mil millones e igualó el rendimiento de un modelo con una densidad de parámetros de 14 mil millones en el mismo conjunto de datos.
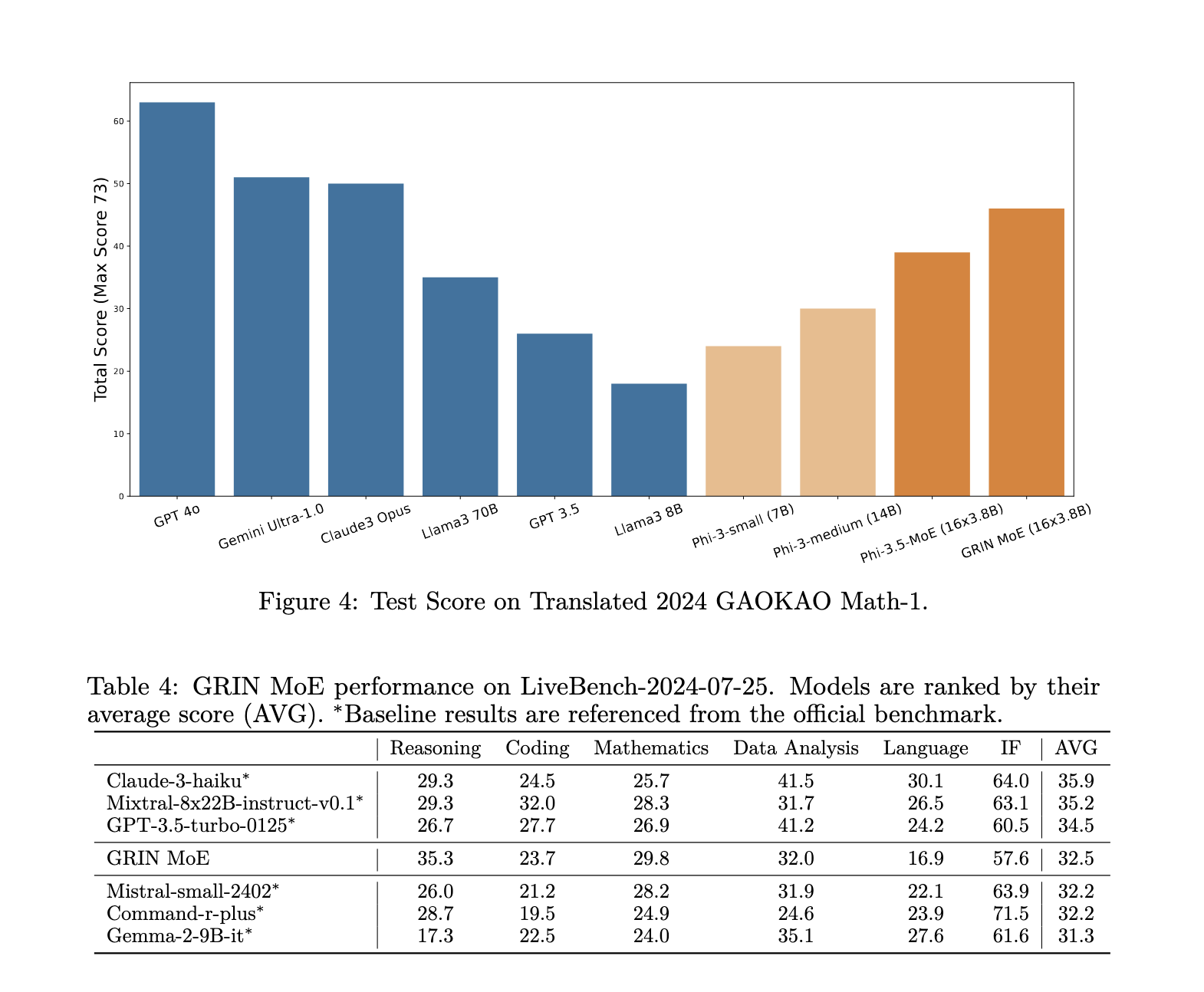
La introducción de GRIN también trae mejoras notables en la eficiencia del entrenamiento. Cuando se entrenó en 64 GPU H100, el modelo GRIN MoE alcanzó un rendimiento del 86,56 %, lo que demuestra que el cómputo disperso puede escalar de manera efectiva y al mismo tiempo mantener una alta eficiencia. Esto marca una mejora significativa con respecto a los modelos anteriores, que a menudo sufren velocidades de entrenamiento más lentas a medida que aumenta la cantidad de parámetros. Además, la capacidad del modelo para evitar la pérdida de tokens significa que mantiene un alto nivel de precisión y solidez en varias tareas, a diferencia de los modelos que pierden información durante el entrenamiento.
En general, el trabajo del equipo de investigación en GRIN presenta una solución convincente al desafío actual de escalar los modelos de IA. Al introducir un método avanzado para la estimación de gradientes y el paralelismo de modelos, han desarrollado con éxito un modelo que no solo funciona mejor, sino que también se entrena de manera más eficiente. Este avance podría conducir a aplicaciones generalizadas en el procesamiento del lenguaje natural, la codificación, las matemáticas y más. El modelo GRIN MoE representa un avance significativo en la investigación de IA, ofreciendo un camino hacia modelos más escalables, eficientes y de alto rendimiento en el futuro.
Echa un vistazo a la Papel, Tarjeta modeloy ManifestaciónTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Nikhil es consultor en prácticas en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA y el aprendizaje automático que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de los materiales, está explorando nuevos avances y creando oportunidades para contribuir.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)