Sketch: un innovador conjunto de herramientas de inteligencia artificial diseñado para optimizar las operaciones de LLM en diversos campos

Los modelos de lenguaje grande (LLM) han dado pasos importantes en el procesamiento del lenguaje natural, demostrando capacidades de generalización notables en diversas tareas. Sin embargo, debido a la falta de uniformidad en la adherencia a las instrucciones, estos modelos enfrentan un desafío crítico a la hora de generar salidas con un formato preciso, como JSON. Esta limitación plantea un obstáculo importante para las aplicaciones impulsadas por IA que requieren salidas LLM estructuradas integradas en sus flujos de datos. A medida que crece la demanda de salidas controladas y estructuradas de los LLM, los investigadores se enfrentan a la necesidad urgente de desarrollar métodos que puedan garantizar un formato preciso y, al mismo tiempo, mantener las potentes capacidades de generación de lenguaje de los modelos.
Los investigadores han explorado varios enfoques para mitigar el desafío de la generación con restricciones de formato en los LLM. Estos métodos se pueden clasificar en tres grupos principales: ajuste previo a la generación, control dentro de la generación y análisis posterior a la generación. El ajuste previo a la generación implica modificar los datos de entrenamiento o las indicaciones para alinearlos con restricciones de formato específicas. Los métodos de control dentro de la generación intervienen durante el proceso de decodificación, utilizando técnicas como JSON Schema, expresiones regulares o gramáticas libres de contexto para garantizar el cumplimiento del formato. Sin embargo, estos métodos a menudo comprometen la calidad de la respuesta. Las técnicas de análisis posterior a la generación refinan la salida sin procesar en formatos estructurados utilizando algoritmos de posprocesamiento. Si bien cada enfoque ofrece ventajas únicas, todos enfrentan limitaciones para equilibrar la precisión del formato con la calidad de la respuesta y las capacidades de generalización.
Investigadores de la Academia de Inteligencia Artificial de Beijing, el Laboratorio de IA AstralForge, el Instituto de Tecnología Informática de la Academia de Ciencias de China, la Universidad de Ciencia y Tecnología Electrónica de China, el Instituto de Tecnología de Harbin, la Facultad de Informática y Ciencias de Datos de la Universidad Tecnológica de Nanyang han propuesto Bosquejoun conjunto de herramientas innovador diseñado para mejorar el funcionamiento de los LLM y garantizar la generación de resultados formateados. Este marco presenta una colección de esquemas de descripción de tareas para varias tareas de NLP, lo que permite a los usuarios definir sus requisitos específicos, incluidos objetivos de la tarea, sistemas de etiquetadoy Especificaciones del formato de salidaSketch permite la implementación inmediata de LLM para tareas desconocidas y al mismo tiempo mantiene la corrección y conformidad del formato de salida.
Las principales contribuciones del marco incluyen:
- Simplificando el funcionamiento del LLM mediante esquemas predefinidos
- Optimización del rendimiento mediante la creación de conjuntos de datos y el ajuste fino del modelo basado en LLaMA3-8B-Instruct
- integrando marcos de decodificación restringidos para un control preciso del formato de salida.
Estos avances mejoran la confiabilidad y precisión de los resultados de LLM, lo que convierte a Sketch en una solución versátil para diversas aplicaciones de PNL en entornos de investigación e industriales.
La arquitectura de Sketch consta de cuatro pasos clave: selección de esquema, instanciación de tareas, embalaje rápidoy generaciónLos usuarios primero eligen un esquema apropiado de un conjunto predefinido alineado con los requisitos de su tarea de NLP. Durante la instanciación de la tarea, los usuarios completan el esquema elegido con detalles específicos de la tarea, creando una instancia de tarea en formato JSON. El paso de empaquetado de indicaciones convierte automáticamente la entrada de la tarea en una indicación estructurada para la interacción de LLM, integrando la descripción de la tarea, la arquitectura de la etiqueta, el formato de salida y los datos de entrada.

En la fase de generación, Sketch puede producir respuestas directamente o emplear métodos de control más precisos. Opcionalmente, integra el lm-format-enforcer, que utiliza gramática independiente del contexto para garantizar la conformidad con el formato de salida. Además, Sketch utiliza la herramienta JSON-schema para la validación de salida, el remuestreo o la generación de excepciones para salidas no compatibles. Esta arquitectura permite un formato controlado y una interacción sencilla con los LLM en varias tareas de NLP, lo que agiliza el proceso para los usuarios y, al mismo tiempo, mantiene la precisión de la salida y la coherencia del formato.

Sketch-8B mejora la capacidad de LLaMA3-8B-Instruct para generar datos estructurados que cumplan con las restricciones del esquema JSON en varias tareas. El proceso de ajuste se centra en dos aspectos clave: garantizar el estricto cumplimiento de las restricciones del esquema JSON y fomentar una generalización robusta de las tareas. Para lograrlo, se construyen dos conjuntos de datos específicos: datos de tareas de procesamiento del lenguaje natural y datos que siguen el esquema.
Los datos de la tarea de procesamiento del lenguaje natural comprenden más de 20 conjuntos de datos que cubren la clasificación de texto, la generación de texto y la extracción de información, con 53 instancias de tarea. El esquema que sigue a los datos incluye 20 000 datos de ajuste fino generados a partir de 10 000 esquemas JSON diversos. El método de ajuste fino optimiza tanto la adherencia al formato como el rendimiento de la tarea de procesamiento del lenguaje natural mediante un enfoque de conjunto de datos mixto. El objetivo de entrenamiento se formula como una maximización de probabilidad logarítmica de la secuencia de salida correcta dada la indicación de entrada. Este enfoque equilibra la mejora de la adherencia del modelo a varios formatos de salida y la mejora de sus capacidades de tarea de procesamiento del lenguaje natural.
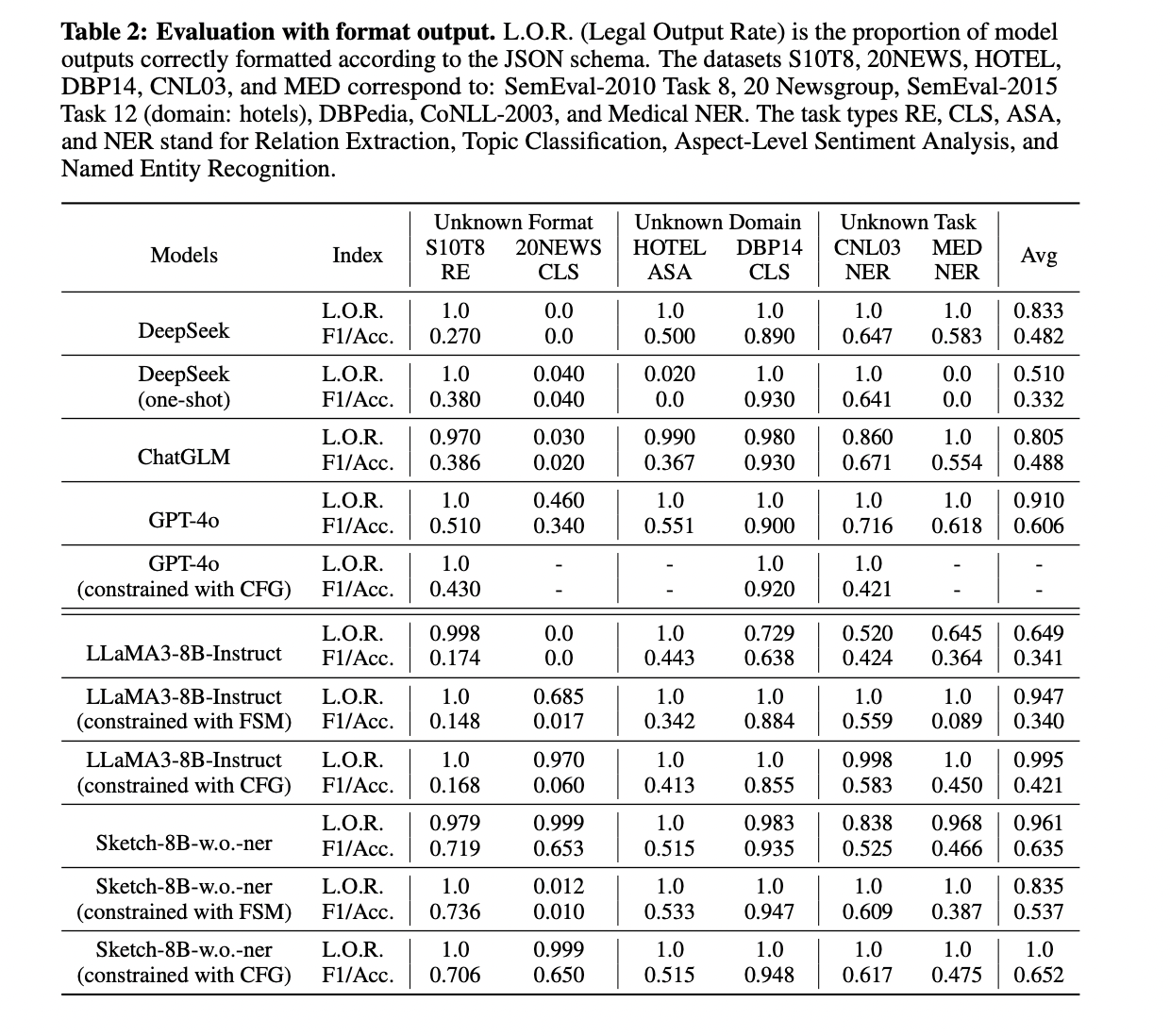
La evaluación de Sketch-8B-wo-ner demuestra sus sólidas capacidades de generalización en formatos, dominios y tareas desconocidos. En cuanto a la adherencia al esquema, Sketch-8B-wo-ner logra una relación de salida legal promedio del 96,2 % en condiciones sin restricciones, lo que supera significativamente el 64,9 % del LLaMA3-8B-Instruct de referencia. Esta mejora es particularmente notable en formatos complejos como 20NEWS, donde Sketch-8B-wo-ner mantiene un alto rendimiento mientras que LLaMA3-8B-Instruct falla por completo.
Las comparaciones de rendimiento revelan que Sketch-8B-wo-ner supera de manera consistente a LLaMA3-8B-Instruct en diversas estrategias de decodificación y conjuntos de datos. En comparación con los modelos convencionales como DeepSeek, ChatGLM y GPT-4o, Sketch-8B-wo-ner muestra un rendimiento superior en conjuntos de datos de formato desconocido y resultados comparables en conjuntos de datos de dominio desconocido. Sin embargo, enfrenta algunas limitaciones en conjuntos de datos de tareas desconocidas debido a su tamaño de modelo más pequeño.
La evaluación también destaca los efectos inconsistentes de los métodos de decodificación restringida (FSM y CFG) en el desempeño de las tareas. Si bien estos métodos pueden mejorar los índices de resultados legales, no mejoran de manera consistente los puntajes de evaluación de las tareas, especialmente para conjuntos de datos con formatos de resultados complejos. Esto sugiere que los enfoques actuales de decodificación restringida pueden no ser uniformemente confiables para las aplicaciones de procesamiento del lenguaje natural en el mundo real.
Este estudio presenta Bosquejoun avance significativo en la simplificación y optimización de las aplicaciones de modelos de lenguaje de gran tamaño. Al introducir un enfoque basado en esquemas, aborda eficazmente los desafíos de la generación de salida estructurada y la generalización de modelos. Las innovaciones clave del marco incluyen una arquitectura de esquema integral para la descripción de tareas, una estrategia robusta de preparación de datos y ajuste fino del modelo para un mejor rendimiento, y la integración de un marco de decodificación restringida para un control preciso de la salida.
Los resultados experimentales demuestran de manera convincente la superioridad del modelo Sketch-8B optimizado para cumplir con los formatos de salida especificados en diversas tareas. La eficacia del conjunto de datos de optimización personalizado, en particular los datos que siguen el esquema, es evidente en el rendimiento mejorado del modelo. Sketch no solo mejora la aplicabilidad práctica de los LLM, sino que también allana el camino para obtener resultados más confiables y compatibles con el formato en diversas tareas de NLP, lo que marca un avance sustancial para hacer que los LLM sean más accesibles y efectivos para aplicaciones del mundo real.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asjad es consultor en prácticas en Marktechpost. Está cursando la licenciatura en ingeniería mecánica en el Instituto Indio de Tecnología de Kharagpur. Asjad es un entusiasta del aprendizaje automático y del aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en el ámbito de la atención médica.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)