Atención por franjas horarias cerradas: avances en los modelos de atención lineal para un procesamiento del lenguaje eficiente y eficaz

Los modelos de transformadores han revolucionado las tareas de modelado de secuencias, pero su mecanismo de atención estándar enfrenta desafíos significativos cuando se trata de secuencias largas. La complejidad cuadrática de la atención estándar basada en softmax dificulta el procesamiento eficiente de datos extensos en campos como la comprensión de videos y el modelado de secuencias biológicas. Si bien esto no es una preocupación importante para el modelado de lenguaje durante el entrenamiento, se vuelve problemático durante la inferencia. La caché de clave-valor (KV) crece linealmente con la longitud de la generación, lo que causa cargas de memoria sustanciales y cuellos de botella en el rendimiento debido a los altos costos de E/S. Estas limitaciones han impulsado a los investigadores a explorar mecanismos de atención alternativos que puedan mantener el rendimiento y al mismo tiempo mejorar la eficiencia, particularmente para tareas de secuencias largas y durante la inferencia.
La atención lineal y sus variantes controladas han surgido como alternativas prometedoras a la atención softmax, demostrando un sólido desempeño en tareas de modelado y comprensión del lenguaje. Estos modelos pueden reformularse como RNN durante la inferencia, logrando una complejidad de memoria constante y mejorando significativamente la eficiencia. Sin embargo, enfrentan dos desafíos clave. En primer lugar, los modelos recurrentes lineales tienen dificultades con las tareas que requieren recuperación o aprendizaje en contexto, enfrentando un compromiso fundamental entre recuperación y memoria. En segundo lugar, entrenar estos modelos desde cero en billones de tokens sigue siendo prohibitivamente costoso, a pesar de admitir un entrenamiento por fragmentos eficiente en hardware.
En este estudio, investigadores de la Escuela de Ciencias Informáticas y Tecnología, la Universidad de Soochow, el Instituto Tecnológico de Massachusetts, la Universidad de California, el Laboratorio de Inteligencia Artificial de Tencent, LuxiTech y la Universidad de Waterloo revisan el modelo Attention with the Bounded-Memory Control (ABC), que conserva la operación softmax, reduciendo las discrepancias entre la atención estándar y lineal en escenarios de ajuste fino del entrenamiento. ABC permite una utilización más eficaz de los estados, lo que requiere tamaños de estado más pequeños para un rendimiento comparable. Sin embargo, su potencial se ha pasado por alto debido al rendimiento mediocre del modelado del lenguaje y la velocidad lenta del entrenamiento. Para abordar estas limitaciones, los investigadores reformulan ABC como atención lineal de dos pasadas vinculada a través de softmax, utilizando una implementación por fragmentos eficiente en hardware para un entrenamiento más rápido.
Sobre esta base, introducen Atención de ranuras cerradas (GSA)una versión controlada de ABC que sigue la tendencia de mejorar la atención lineal con mecanismos de control. GSA no solo iguala el desempeño en tareas de modelado y comprensión del lenguaje, sino que también supera significativamente a otros modelos lineales en tareas intensivas de recuperación en contexto sin requerir tamaños de estado grandes. En el entorno de ajuste fino T2R, GSA demuestra un desempeño superior al ajustar Mistral-7B, superando a los modelos de lenguaje recurrentes grandes y superando a otros modelos lineales y métodos T2R. En particular, GSA logra velocidades de entrenamiento similares a GLA al tiempo que ofrece una velocidad de inferencia mejorada debido a su tamaño de estado más pequeño.
GSA aborda dos limitaciones clave del modelo ABC: la falta de un mecanismo de olvido y un sesgo inductivo injustificado que favorece los tokens iniciales. GSA incorpora un mecanismo de compuerta que permite el olvido de información histórica e introduce un sesgo inductivo de actualidad, crucial para el procesamiento del lenguaje natural.
El núcleo de GSA es una regla de actualización de RNN controlada por puerta para cada ranura de memoria, que utiliza un valor de control dependiente de los datos escalares. Esto se puede representar en forma de matriz, similar a HGRN2. GSA se puede implementar como una Atención lineal cerrada de dos pasos (GLA)lo que permite un entrenamiento por fragmentos con uso eficiente del hardware.
La arquitectura GSA consta de bloques L, cada uno de los cuales comprende una capa de mezcla de tokens GSA y una Unidad lineal cerrada (GLU) Capa de mezcla de canales. Emplea atención de múltiples cabezales para capturar diferentes aspectos de entrada. Para cada cabezal, la entrada sufre transformaciones lineales con activación Swish. Se obtiene una compuerta de olvido utilizando una transformación lineal seguida de una activación sigmoidea con un factor de amortiguación. Luego, las salidas se procesan a través de la capa GSA y se combinan para producir la salida final. El modelo equilibra la eficiencia y la eficacia controlando cuidadosamente los recuentos de parámetros, generalmente estableciendo el número de ranuras de memoria en 64 y utilizando 4 cabezales de atención.
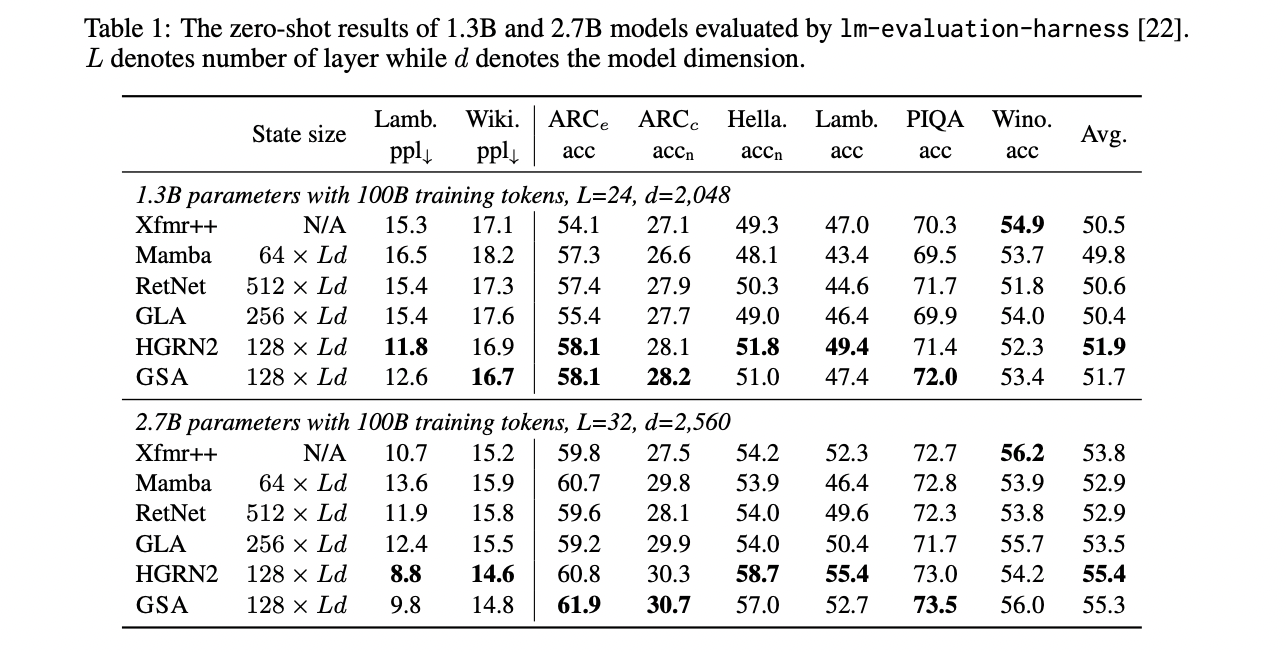
GSA demuestra un rendimiento competitivo tanto en el modelado del lenguaje como en tareas intensivas de recuperación en contexto. En experimentos de modelado del lenguaje en el corpus Slimpajama, GSA tiene un rendimiento comparable al de modelos sólidos como HGRN2 con estados ocultos de igual tamaño, mientras que supera a GLA y RetNet incluso con tamaños de estado más pequeños. Para modelos de parámetros de 1.300 millones y 2.700 millones, GSA logra resultados comparables o mejores en varias tareas de razonamiento de sentido común, incluidas ARC, Hellaswag, Lambada, PIQA y Winograde.
En tareas que requieren un uso intensivo de la memoria, GSA muestra mejoras significativas en comparación con otros modelos subcuadráticos. En la tarea sintética Multi-Query Associative Recall (MQAR), GSA supera a Mamba, GLA, RetNet y HGRN2 en diferentes dimensiones del modelo. En tareas que requieren un uso intensivo de la memoria en el mundo real, como FDA, SWDE, SQuAD, NQ, TriviaQA y Drop, GSA supera constantemente a otros modelos subcuadráticos y logra un rendimiento promedio cercano al valor de referencia de Transformer (Xfmr++).

Este estudio presenta GSA que mejora el modelo ABC con un mecanismo de compuerta inspirado en la Atención Lineal Compuerta. Al enmarcar GSA como un GLA de dos pasadas, utiliza implementaciones eficientes en hardware para un entrenamiento eficiente. Los mecanismos de lectura y olvido de memoria conscientes del contexto de GSA aumentan implícitamente la capacidad del modelo mientras mantienen un tamaño de estado pequeño, mejorando tanto la eficiencia del entrenamiento como de la inferencia. Experimentos extensos demuestran las ventajas de GSA en tareas intensivas de recuperación en contexto y escenarios de “ajuste fino de Transformers preentrenados a RNN”. Esta innovación cierra la brecha entre los modelos de atención lineal y los Transformers tradicionales, ofreciendo una dirección prometedora para tareas de modelado y comprensión del lenguaje eficientes y de alto rendimiento.
Echa un vistazo a la Papel y GitHubTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asjad es consultor en prácticas en Marktechpost. Está cursando la licenciatura en ingeniería mecánica en el Instituto Indio de Tecnología de Kharagpur. Asjad es un entusiasta del aprendizaje automático y del aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en el ámbito de la atención médica.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)