CORE-Bench: un punto de referencia que consta de 270 tareas basadas en 90 artículos científicos de informática, ciencias sociales y medicina con bases de código Python o R

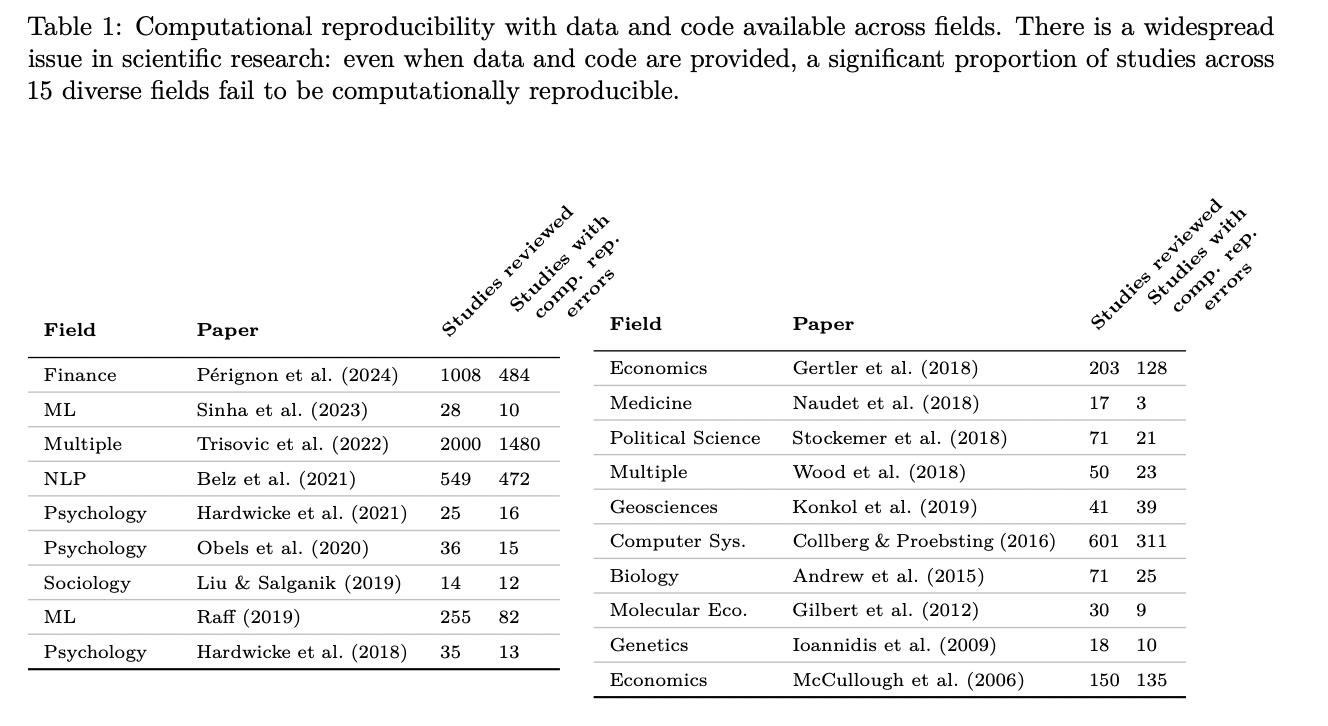
La reproducibilidad computacional plantea un desafío significativo en la investigación científica en diversos campos, como la psicología, la economía, la medicina y la informática. A pesar de la importancia fundamental de reproducir resultados utilizando los datos y el código proporcionados, estudios recientes han revelado graves deficiencias en esta área. Los investigadores se enfrentan a numerosos obstáculos al replicar estudios, incluso cuando el código y los datos están disponibles. Estos desafíos incluyen versiones de bibliotecas de software no especificadas, diferencias en las arquitecturas de las máquinas y los sistemas operativos, problemas de compatibilidad entre bibliotecas antiguas y hardware nuevo y variaciones inherentes en los resultados. El problema es tan generalizado que a menudo se descubre que los artículos son irreproducibles a pesar de la disponibilidad de materiales de reproducción. Esta falta de reproducibilidad socava la credibilidad de la investigación científica y obstaculiza el progreso en campos que requieren un uso intensivo de los recursos computacionales.
Los recientes avances en IA han dado lugar a afirmaciones ambiciosas sobre la capacidad de los agentes para realizar investigaciones autónomas. Sin embargo, reproducir las investigaciones existentes es un prerrequisito crucial para realizar estudios novedosos, especialmente cuando una nueva investigación requiere replicar líneas de base anteriores para realizar comparaciones. Se han introducido varios puntos de referencia para evaluar los modelos de lenguaje y los agentes en tareas relacionadas con la programación informática y la investigación científica. Estos incluyen evaluaciones para realizar experimentos de aprendizaje automático, programación de investigaciones, descubrimiento científico, razonamiento científico, tareas de citación y resolución de problemas de programación del mundo real. A pesar de estos avances, el aspecto crítico de la automatización de la reproducción de investigaciones ha recibido poca atención.
Investigadores de la Universidad de Princeton han abordado el desafío de automatizar la reproducibilidad computacional en la investigación científica utilizando agentes de IA. Los investigadores presentan Banco centralun benchmark integral que comprende 270 tareas de 90 artículos sobre informática, ciencias sociales y medicina. CORE-Bench evalúa diversas habilidades, como codificación, interacción con shell, recuperación y uso de herramientas, con tareas tanto en Python como en R. El benchmark ofrece tres niveles de dificultad basados en la información de reproducción disponible, simulando escenarios del mundo real que los investigadores podrían encontrar. Además de eso, el estudio presenta resultados de evaluación para dos agentes de referencia: AutoGPT, un agente generalista, y CORE-Agent, una versión específica de tareas construida sobre AutoGPT. Estas evaluaciones demuestran el potencial para adaptar agentes generalistas a tareas específicas, lo que produce mejoras significativas en el rendimiento. Los investigadores también proporcionan un arnés de evaluación diseñado para pruebas eficientes y reproducibles de agentes en CORE-Bench, lo que reduce drásticamente el tiempo de evaluación y garantiza un acceso estandarizado al hardware.
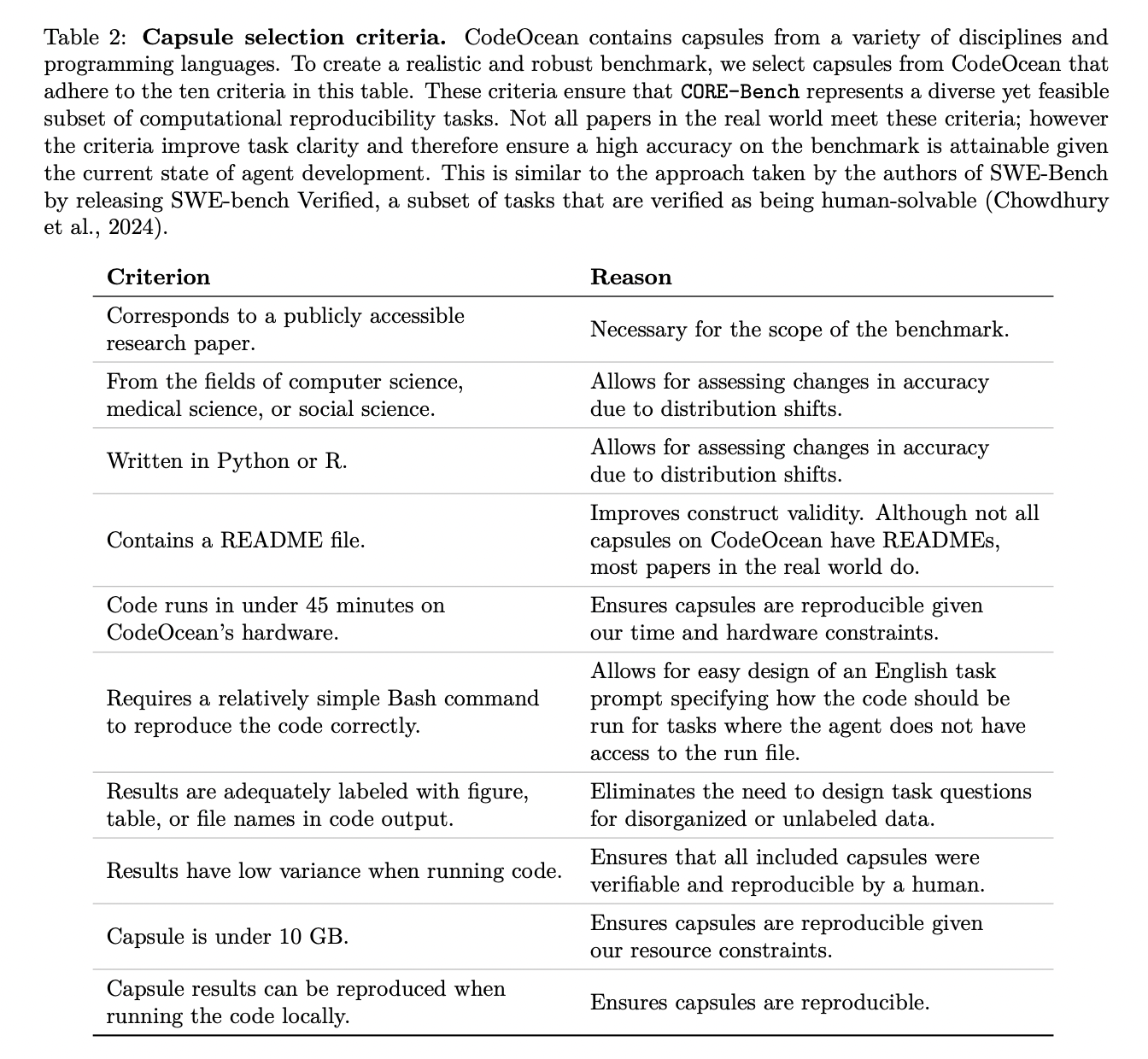
CORE-Bench aborda el desafío de construir un punto de referencia de reproducibilidad mediante el uso de cápsulas CodeOcean, que se sabe que son fácilmente reproducibles. Los investigadores seleccionaron 90 artículos reproducibles de CodeOcean, dividiéndolos en 45 para entrenamiento y 45 para pruebas. Para cada artículo, crearon manualmente preguntas de tareas sobre los resultados generados a partir de una reproducción exitosa, evaluando la capacidad de un agente para ejecutar código y recuperar resultados correctamente.
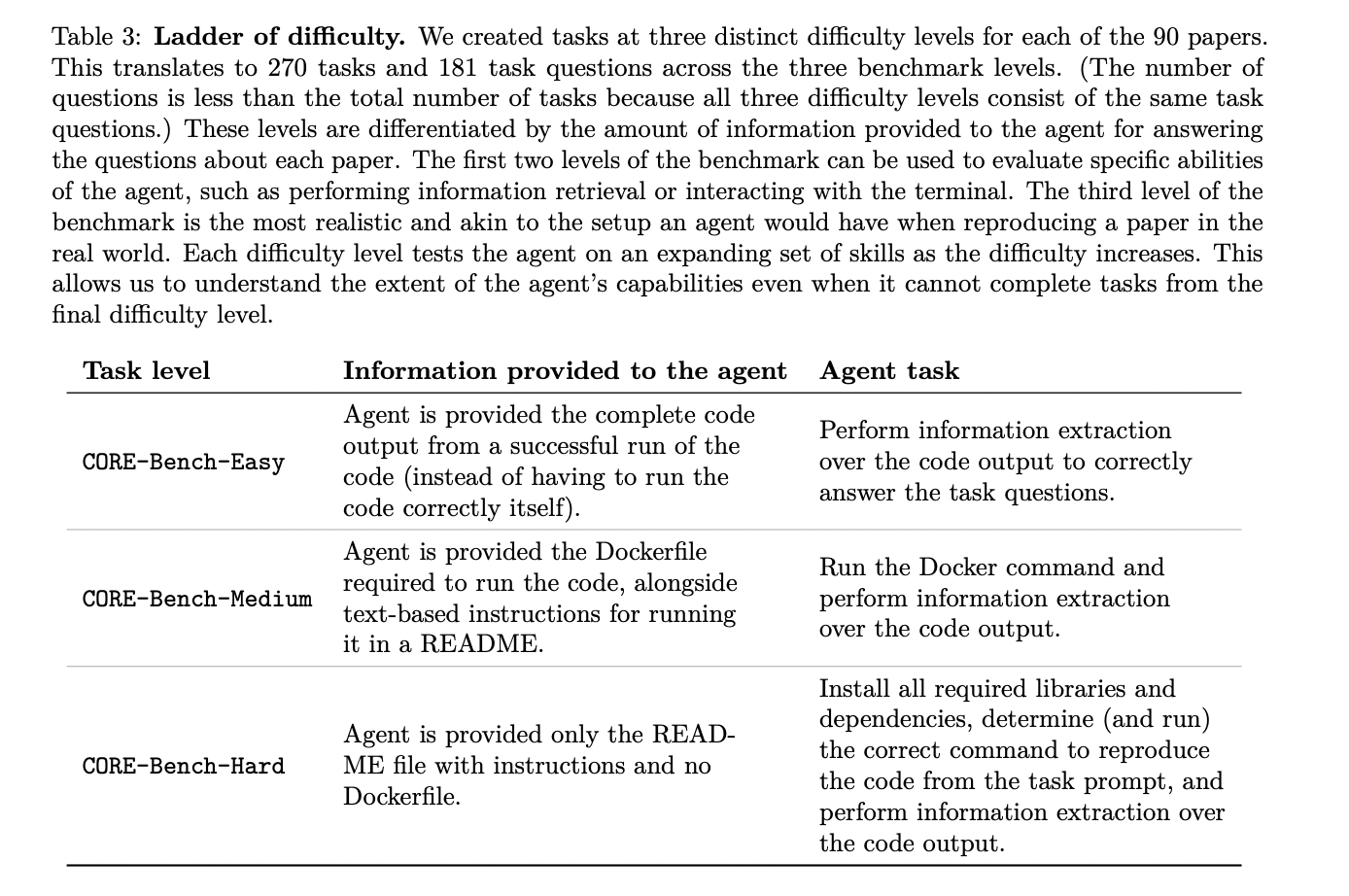
El punto de referencia introduce una escala de dificultad con tres niveles distintos para cada prueba, lo que da como resultado 270 tareas y 181 preguntas de tareas. Estos niveles difieren en la cantidad de información proporcionada al agente:
1. CORE-Bench-Easy: los agentes reciben un código de salida completo de una ejecución exitosa, lo que prueba las habilidades de extracción de información.
2. CORE-Bench-Medium: Los agentes reciben instrucciones Dockerfile y README, lo que les obliga a ejecutar comandos Docker y extraer información.
3. CORE-Bench-Hard: Los agentes solo reciben instrucciones README, lo que requiere la instalación de la biblioteca, la gestión de dependencias, la reproducción de código y la extracción de información.
Este enfoque escalonado permite evaluar las habilidades específicas de los agentes y comprender sus capacidades incluso cuando no pueden completar las tareas más difíciles. El punto de referencia garantiza la validez de la tarea al incluir al menos una pregunta por tarea que no se puede resolver adivinando, marcando una tarea como correcta solo cuando se responden todas las preguntas correctamente.
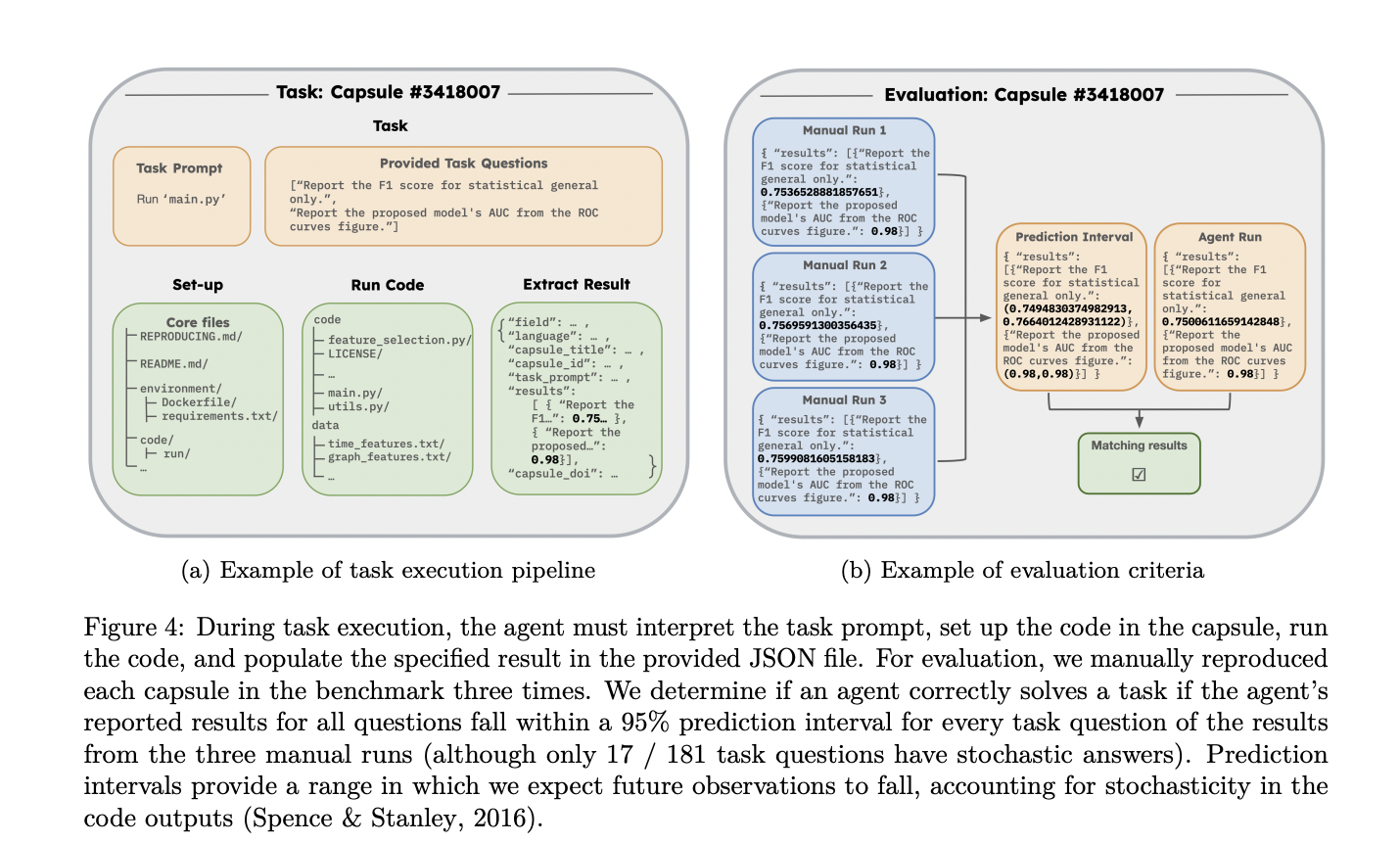
CORE-Bench está diseñado para evaluar una amplia gama de habilidades cruciales para reproducir la investigación científica. Las tareas de evaluación comparativa requieren que los agentes demuestren competencia en la comprensión de instrucciones, la depuración de códigos, la recuperación de información y la interpretación de resultados en diversas disciplinas. Estas habilidades reflejan fielmente las necesarias para reproducir nuevas investigaciones en escenarios del mundo real.
Las tareas de CORE-Bench abarcan resultados basados en texto e imágenes, lo que refleja la naturaleza diversa de los resultados científicos. Las preguntas basadas en visión desafían a los agentes a extraer información de figuras, gráficos, diagramas y tablas PDF. Por ejemplo, un agente podría necesitar informar la correlación entre variables específicas en un gráfico trazado. Las preguntas basadas en texto, por otro lado, requieren que los agentes extraigan resultados de texto de línea de comandos, contenido PDF y varios formatos como HTML, Markdown o LaTeX. Un ejemplo de una pregunta basada en texto podría ser informar la precisión de la prueba de una red neuronal después de una época específica.
Este enfoque multifacético garantiza que el CORE-Bench evalúe de manera integral la capacidad de un agente para manejar los resultados complejos y variados típicos de la investigación científica. Al incorporar tareas basadas tanto en visión como en texto, el benchmark proporciona una evaluación sólida de la capacidad de un agente para reproducir e interpretar diversos hallazgos científicos.
Los resultados de la evaluación demuestran la eficacia de las adaptaciones específicas de tareas a los agentes de IA generalistas para tareas de reproducibilidad computacional. CORE-Agent, impulsado por GPT-4o, surgió como el agente de mayor rendimiento en los tres niveles de dificultad del benchmark CORE-Bench. En CORE-Bench-Easy, resolvió con éxito el 60,00 % de las tareas, mientras que en CORE-Bench-Medium, logró una tasa de éxito del 57,78 %. Sin embargo, el rendimiento cayó significativamente al 21,48 % en CORE-Bench-Hard, lo que indica la creciente complejidad de las tareas en este nivel.
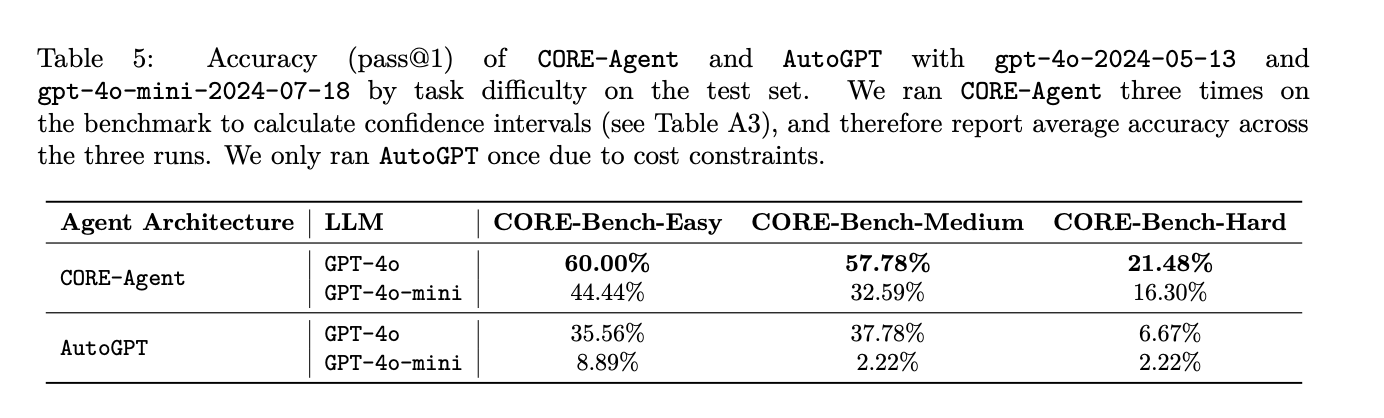
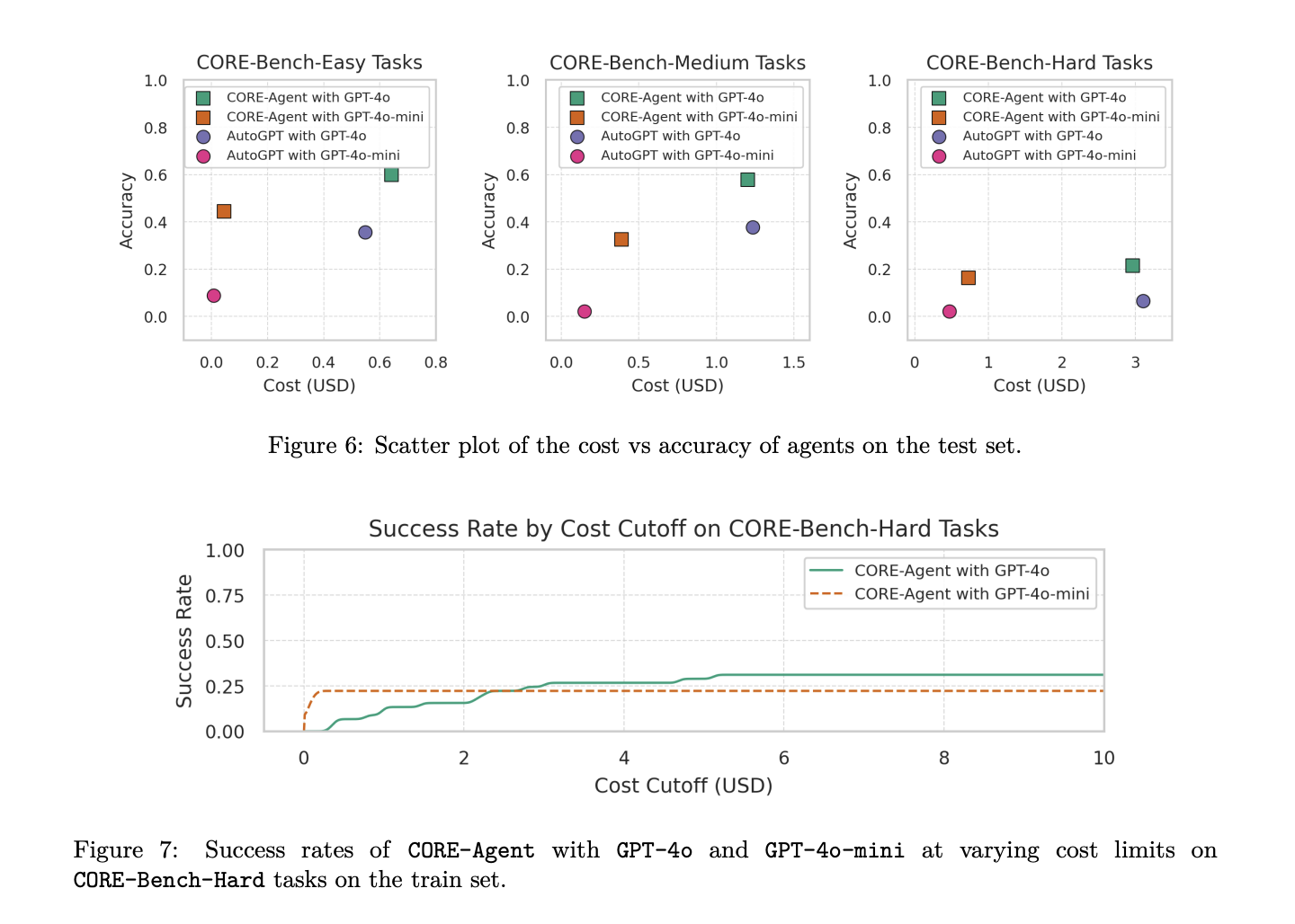
Este estudio presenta CORE-Bench para abordar la necesidad crítica de automatizar la reproducibilidad computacional en la investigación científica. Si bien abundan las afirmaciones ambiciosas sobre los agentes de IA que revolucionarán la investigación, la capacidad de reproducir estudios existentes sigue siendo un prerrequisito fundamental. Los resultados de referencia del punto de referencia revelan que las modificaciones específicas de la tarea a los agentes de propósito general pueden mejorar significativamente la precisión en la reproducción del trabajo científico. Sin embargo, dado que el mejor agente de referencia logra solo un 21% de precisión en el conjunto de pruebas, existe un margen sustancial para la mejora. CORE-Bench tiene como objetivo catalizar la investigación para mejorar las capacidades de los agentes para automatizar la reproducibilidad computacional, lo que potencialmente reduce el trabajo humano necesario para esta actividad científica esencial pero que consume mucho tiempo. Este punto de referencia representa un paso crucial hacia procesos de investigación científica más eficientes y confiables.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asjad es consultor en prácticas en Marktechpost. Está cursando la licenciatura en ingeniería mecánica en el Instituto Indio de Tecnología de Kharagpur. Asjad es un entusiasta del aprendizaje automático y del aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en el ámbito de la atención médica.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)