HARP (Reagrupamiento asistido por humanos con crítico invariante de permutación): un marco de aprendizaje de refuerzo de múltiples agentes para mejorar el agrupamiento dinámico y el rendimiento con una mínima intervención humana

El aprendizaje por refuerzo multiagente (MARL, por sus siglas en inglés) es un campo centrado en el desarrollo de sistemas en los que múltiples agentes cooperan para resolver tareas que exceden las capacidades de los agentes individuales. Esta área ha ganado una atención significativa debido a su relevancia en vehículos autónomos, robótica y entornos de juegos complejos. El objetivo es permitir que los agentes trabajen juntos de manera eficiente, se adapten a entornos dinámicos y resuelvan tareas complejas que requieren coordinación y colaboración. Para ello, los investigadores desarrollan modelos que facilitan la interacción entre agentes para garantizar una resolución de problemas efectiva. Esta rama de la inteligencia artificial ha crecido rápidamente debido a su potencial para aplicaciones del mundo real, lo que requiere mejoras constantes en la cooperación de los agentes y los algoritmos de toma de decisiones.
Uno de los principales desafíos de MARL es que resulta notoriamente difícil coordinar a múltiples agentes, en particular en entornos que presentan desafíos dinámicos y complejos. Los agentes suelen necesitar ayuda con dos problemas principales: baja eficiencia de muestreo y mala generalización. La eficiencia de muestreo se refiere a la capacidad del agente de aprender de manera efectiva a partir de un número limitado de experiencias, mientras que la generalización es su capacidad de aplicar comportamientos aprendidos a entornos nuevos e invisibles. A menudo se necesita la experiencia humana para guiar la toma de decisiones del agente en escenarios complejos, pero es costosa, escasa y requiere mucho tiempo. El desafío se ve agravado por el hecho de que la mayoría de los marcos de aprendizaje de refuerzo dependen en gran medida de la intervención humana durante la fase de entrenamiento, lo que genera importantes limitaciones de escalabilidad.
Varios métodos existentes intentan mejorar la colaboración y la toma de decisiones de los agentes mediante la introducción de marcos y algoritmos específicos. Algunos métodos se centran en agrupaciones basadas en roles, como el método RODE, que descompone el espacio de acción en roles para crear políticas más eficientes. Otros, como GACG, utilizan modelos basados en gráficos para representar las interacciones de los agentes y optimizar su cooperación. Estos métodos existentes, si bien son útiles, aún dejan lagunas en la adaptabilidad de los agentes y no abordan las limitaciones de la intervención humana. Dependen demasiado de roles predefinidos o requieren un modelado matemático complejo que limita su flexibilidad en aplicaciones del mundo real. Esta ineficiencia subraya la necesidad de marcos más adaptables que requieran una participación humana menos continua durante el entrenamiento.
Investigadores de la Universidad Politécnica Northwestern y la Universidad de Georgia han presentado un nuevo marco llamado HARP (Reagrupamiento asistido por humanos con crítico invariante de permutación)Este enfoque innovador permite a los agentes reagruparse de forma dinámica, incluso durante la implementación, con una intervención humana limitada. HARP es único porque permite a los usuarios humanos no expertos proporcionar comentarios útiles durante la implementación sin necesidad de una guía continua de nivel experto. El objetivo principal de HARP es reducir la dependencia de expertos humanos durante la capacitación y, al mismo tiempo, permitir la participación humana estratégica durante la implementación, lo que reduce de manera eficaz la brecha entre la automatización y el refinamiento guiado por humanos.
La innovación clave de HARP radica en su combinación de agrupamiento automático durante la fase de entrenamiento y reagrupamiento asistido por humanos durante la implementación. Durante el entrenamiento, los agentes aprenden a formar grupos de forma autónoma, optimizando la realización de tareas colaborativas. Cuando se despliegan, buscan activamente la asistencia humana cuando es necesario, utilizando un Crítico de grupo invariante de permutación para evaluar y refinar los agrupamientos en función de las sugerencias humanas. Este método permite a los agentes adaptarse mejor a entornos complejos, ya que se integra la información humana para corregir o mejorar la dinámica del grupo cuando los agentes enfrentan desafíos. La característica única de HARP es que permite que los humanos no expertos brinden contribuciones significativas a medida que el sistema refina sus sugerencias a través de la reevaluación. El método ajusta dinámicamente las composiciones de los grupos en función de las evaluaciones del valor Q y el rendimiento del agente.
El rendimiento de HARP se probó en múltiples entornos cooperativos utilizando seis mapas en el Desafío Multiagente de StarCraft II, que abarca tres niveles de dificultad: Fácil (8 m, MMM), Difícil (8 m frente a 9 m, 5 m frente a 6 m) y Súper Difícil (MMM2, corredor). En estas pruebas, los agentes controlados por HARP superaron a los guiados por métodos tradicionales, logrando una tasa de éxito del 100 % en los seis mapas. En mapas más difíciles, como 5 m frente a 6 m, donde otros métodos lograron tasas de éxito de solo el 53,1 % frente al 71,2 %, los agentes de HARP mostraron una marcada mejora, logrando una tasa de éxito del 100 %. El método también mejoró el rendimiento de los agentes en más del 10 % en comparación con otras técnicas que no incorporan asistencia humana. La introducción de la participación humana durante la implementación y la agrupación automática durante el entrenamiento dieron como resultado mejoras significativas en los diferentes niveles de dificultad, lo que demuestra la capacidad del sistema para adaptarse y responder a situaciones complejas de manera eficiente.
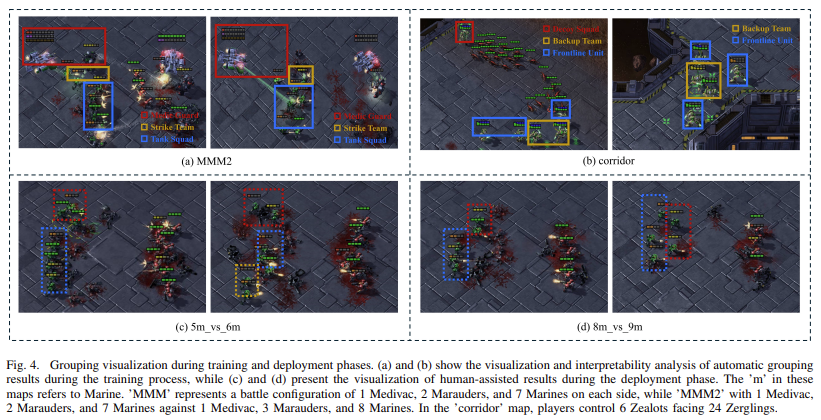
Los resultados de la implementación de HARP destacan su importante impacto en la mejora de los sistemas multiagente. Su capacidad de buscar e integrar activamente la orientación humana durante la implementación, en particular en entornos difíciles, reduce la necesidad de contar con la experiencia humana durante el entrenamiento. HARP demostró un marcado aumento en las tasas de éxito en mapas difíciles, como MMM2 y el mapa de corredores, donde el rendimiento de otros métodos flaqueó. En el mapa de corredores, los agentes controlados por HARP lograron una tasa de éxito del 100%, en comparación con el 0% de los diferentes enfoques. La flexibilidad del marco le permite adaptarse dinámicamente a los cambios ambientales, lo que lo convierte en una solución sólida para escenarios complejos de múltiples agentes.

En conclusión, HARP ofrece un gran avance en el aprendizaje de refuerzo multiagente al reducir la necesidad de una participación humana continua durante el entrenamiento y al mismo tiempo permitir la participación humana específica durante la implementación. Este sistema aborda los desafíos clave de la baja eficiencia de la muestra y la mala generalización al permitir ajustes grupales dinámicos basados en la retroalimentación humana. Al aumentar significativamente el rendimiento del agente en varios niveles de dificultad, HARP presenta una solución escalable y adaptable para la coordinación multiagente. La aplicación exitosa de este marco en el entorno de StarCraft II sugiere su potencial para un uso más amplio en escenarios del mundo real que requieren la colaboración entre humanos y máquinas, como la robótica y los sistemas autónomos.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc. Como ingeniero y emprendedor visionario, Asif está comprometido con aprovechar el potencial de la inteligencia artificial para el bien social. Su iniciativa más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad de noticias sobre aprendizaje automático y aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)