Los investigadores de ByteDance lanzan InfiMM-WebMath-40: un conjunto de datos multimodales abierto diseñado para el razonamiento matemático complejo

La inteligencia artificial ha mejorado significativamente las tareas de razonamiento complejo, en particular en dominios especializados como las matemáticas. Los modelos de lenguaje de gran tamaño (LLM, por sus siglas en inglés) han ganado atención por su capacidad para procesar grandes conjuntos de datos y resolver problemas intrincados. Las capacidades de razonamiento matemático de estos modelos han mejorado enormemente con el paso de los años. Este progreso ha sido impulsado por los avances en las técnicas de entrenamiento, como la incitación por cadena de pensamiento (CoT, por sus siglas en inglés), y los diversos conjuntos de datos, lo que permite que estos modelos resuelvan diversos problemas matemáticos, desde aritmética simple hasta tareas complejas de nivel de competencia de secundaria. La creciente sofisticación de los LLM los ha convertido en herramientas indispensables en campos donde se requiere razonamiento avanzado. Aun así, la calidad y la escala de los conjuntos de datos de preentrenamiento disponibles han limitado su potencial total, especialmente para proyectos de código abierto.
Un problema clave que obstaculiza el desarrollo del razonamiento matemático en los LLM es la falta de conjuntos de datos multimodales completos que integren texto y datos visuales, como diagramas, ecuaciones y figuras geométricas. La mayor parte del conocimiento matemático se expresa a través de explicaciones textuales y elementos visuales. Si bien los modelos propietarios como GPT-4 y Claude 3.5 Sonnet han aprovechado amplios conjuntos de datos privados para el entrenamiento previo, la comunidad de código abierto ha tenido dificultades para mantenerse al día debido a la escasez de conjuntos de datos de alta calidad y disponibles públicamente. Sin estos recursos, es difícil que los modelos de código abierto avancen en el manejo de las tareas de razonamiento complejas que abordan los modelos propietarios. Esta brecha en los conjuntos de datos multimodales ha dificultado que los investigadores entrenen modelos que puedan manejar tareas de razonamiento visual y basado en texto.
Se han utilizado varios enfoques para entrenar a los LLM para el razonamiento matemático, pero la mayoría se centra en conjuntos de datos que solo contienen texto. Por ejemplo, los conjuntos de datos propietarios como WebMath y MathMix han proporcionado miles de millones de tokens de texto para entrenar modelos como GPT-4, pero no abordan los elementos visuales de las matemáticas. También se han introducido conjuntos de datos de código abierto como OpenWebMath y DeepSeekMath, pero se centran principalmente en el texto matemático en lugar de integrar datos visuales y textuales. Si bien estos conjuntos de datos han hecho avanzar a los LLM en áreas específicas de las matemáticas, como la aritmética y el álgebra, se quedan cortos cuando se trata de tareas complejas de razonamiento multimodal que requieren la integración de elementos visuales con texto. Esta limitación ha llevado al desarrollo de modelos que funcionan bien en tareas basadas en texto, pero tienen dificultades con problemas multimodales que combinan explicaciones escritas con diagramas o ecuaciones.
Investigadores de ByteDance y la Academia China de Ciencias presentaron InfiMM-WebMath-40Bun conjunto de datos completo que ofrece un recurso multimodal a gran escala diseñado específicamente para el razonamiento matemático. Este conjunto de datos incluye 24 millones de páginas web, 85 millones de URL de imágenes asociadas y aproximadamente 40 mil millones de tokens de texto extraídos y filtrados del repositorio CommonCrawl. El equipo de investigación filtró meticulosamente los datos para garantizar la inclusión de contenido relevante y de alta calidad, lo que lo convierte en el primero de su tipo en la comunidad de código abierto. Al combinar datos matemáticos textuales y visuales, InfiMM-WebMath-40B ofrece un recurso sin precedentes para entrenar modelos de lenguaje multimodales grandes (MLLM), lo que les permite procesar y razonar con conceptos matemáticos más complejos que nunca.
El conjunto de datos se construyó utilizando un riguroso proceso de procesamiento de datos. Los investigadores comenzaron con 122 mil millones de páginas web, filtradas a 24 millones de documentos web, asegurándose de que el contenido se centrara en las matemáticas y la ciencia. FastText, una herramienta de identificación de idiomas, filtró el contenido que no estaba en inglés ni en chino. La naturaleza multimodal del conjunto de datos requirió una atención especial a la extracción de imágenes y la alineación de las imágenes con su texto correspondiente. En total, se extrajeron, filtraron y emparejaron 85 millones de URL de imágenes con contenido matemático relevante, creando un conjunto de datos que integra elementos visuales y textuales para mejorar las capacidades de razonamiento matemático de los LLM.
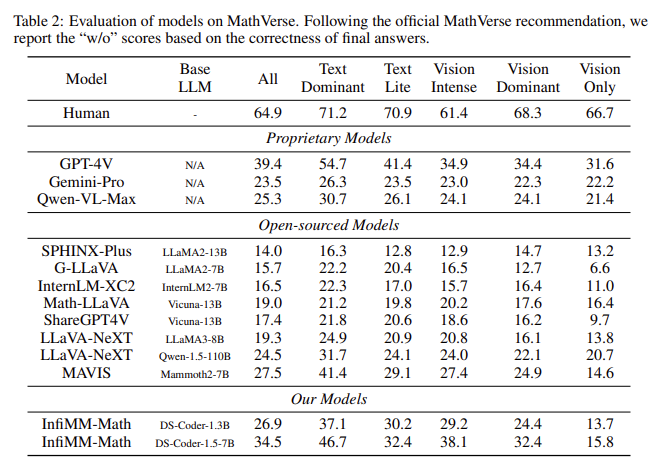
El rendimiento de los modelos entrenados con InfiMM-WebMath-40B ha mejorado significativamente en comparación con conjuntos de datos de código abierto anteriores. En evaluaciones realizadas en puntos de referencia como MathVerse y We-Math, los modelos entrenados con este conjunto de datos superaron a otros en su capacidad para procesar tanto texto como información visual. Por ejemplo, a pesar de utilizar solo 40 mil millones de tokens, el modelo de los investigadores, InfiMM-Math, tuvo un rendimiento comparable al de los modelos propietarios que utilizaron 120 mil millones de tokens. En el punto de referencia MathVerse, InfiMM-Math demostró un rendimiento superior en las categorías de texto dominante, texto ligero y visión intensiva, superando a muchos modelos de código abierto con conjuntos de datos mucho más grandes. De manera similar, en el punto de referencia We-Math, el modelo logró resultados notables, demostrando su capacidad para manejar tareas multimodales y estableciendo un nuevo estándar para los LLM de código abierto.

En conclusión, InfiMM-WebMath-40B, que ofrece un conjunto de datos multimodales a gran escala, debe abordar más datos para entrenar modelos de código abierto para manejar tareas de razonamiento complejas que involucran texto y datos visuales. La construcción meticulosa del conjunto de datos y la combinación de 40 mil millones de tokens de texto con 85 millones de URL de imágenes proporcionan una base sólida para la próxima generación de modelos de lenguaje multimodales de gran tamaño. El rendimiento de los modelos entrenados en InfiMM-WebMath-40B destaca la importancia de integrar elementos visuales con datos textuales para mejorar las capacidades de razonamiento matemático. Este conjunto de datos cierra la brecha entre los modelos propietarios y de código abierto y allana el camino para futuras investigaciones destinadas a mejorar la capacidad de la IA para resolver problemas matemáticos complejos.
Echa un vistazo a la Papel y Conjunto de datosTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc. Como ingeniero y emprendedor visionario, Asif está comprometido con aprovechar el potencial de la inteligencia artificial para el bien social. Su iniciativa más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad de noticias sobre aprendizaje automático y aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)