Aprendizaje federado avanzado que preserva la privacidad (APPFL): un marco de IA para abordar la heterogeneidad de los datos, las disparidades computacionales y los desafíos de seguridad en el aprendizaje automático descentralizado

El aprendizaje federado (FL) es un poderoso paradigma de ML que permite que varios propietarios de datos entrenen modelos sin centralizar sus datos de manera colaborativa. Este enfoque es particularmente valioso en dominios donde la privacidad de los datos es fundamental, como la atención médica, las finanzas y el sector energético. El núcleo del aprendizaje federado radica en entrenar modelos en datos descentralizados almacenados en el dispositivo de cada cliente. Sin embargo, esta naturaleza distribuida plantea desafíos importantes, incluida la heterogeneidad de los datos, las disparidades de computación en los dispositivos y los riesgos de seguridad, como la posible exposición de información confidencial a través de actualizaciones de modelos. A pesar de estos problemas, el aprendizaje federado representa un camino prometedor para aprovechar grandes conjuntos de datos distribuidos para crear modelos altamente precisos y, al mismo tiempo, mantener la privacidad del usuario.
Un problema importante al que se enfrenta el aprendizaje federado es la variabilidad en la calidad y distribución de los datos entre los dispositivos cliente. En el aprendizaje automático tradicional, se supone que los datos se distribuyen de manera uniforme y se recopilan de forma independiente. Sin embargo, los datos de los clientes suelen estar desequilibrados y no son independientes en un entorno federado. Por ejemplo, un dispositivo puede contener datos muy diferentes a los de otro, lo que genera objetivos de entrenamiento que difieren entre los clientes. Esta variación puede generar un rendimiento del modelo subóptimo cuando se agregan actualizaciones locales en un modelo global. La potencia computacional de los dispositivos cliente varía ampliamente, lo que hace que los dispositivos más lentos retrasen el progreso del entrenamiento. Estas disparidades dificultan la sincronización eficaz del proceso de entrenamiento, lo que genera ineficiencias y una reducción de la precisión del modelo.
Los enfoques anteriores para abordar estos problemas han incluido marcos como FedAvg, que agrega modelos de clientes en un servidor central promediando sus actualizaciones locales. Sin embargo, estos métodos han demostrado ser inadecuados para lidiar con la heterogeneidad de los datos y la varianza computacional. Se han introducido técnicas de agregación asincrónica, que permiten que los dispositivos más rápidos contribuyan con actualizaciones sin esperar a los más lentos, para mitigar los retrasos. Sin embargo, estos métodos tienden a degradar la precisión del modelo debido al desequilibrio en la frecuencia de las contribuciones de diferentes clientes. Las medidas de seguridad como la privacidad diferencial y el cifrado homomórfico a menudo son demasiado costosas desde el punto de vista computacional o no logran evitar por completo la fuga de datos a través de los gradientes del modelo, lo que pone en riesgo la información confidencial.
Investigadores del Laboratorio Nacional Argonne, la Universidad de Illinois y la Universidad Estatal de Arizona han desarrollado el Aprendizaje federado avanzado que preserva la privacidad (APPFL) marco de trabajo en respuesta a estas limitaciones. Este nuevo marco ofrece una solución integral y flexible que aborda los desafíos técnicos y de seguridad de los modelos FL actuales. APPFL mejora la eficiencia, la seguridad y la escalabilidad de los sistemas de aprendizaje federado. Admite estrategias de agregación sincrónicas y asincrónicas, lo que le permite adaptarse a varios escenarios de implementación. Incluye mecanismos robustos de preservación de la privacidad para proteger contra ataques de reconstrucción de datos al tiempo que permite un entrenamiento de modelos de alta calidad en clientes distribuidos.
La innovación principal de APPFL reside en su arquitectura modular, que permite a los desarrolladores incorporar fácilmente nuevos algoritmos y estrategias de agregación adaptados a necesidades específicas. El marco integra técnicas de agregación avanzadas, como FedAsync y FedCompass, que sincronizan las actualizaciones del modelo de manera más eficaz al ajustar dinámicamente el proceso de entrenamiento en función de la potencia informática de cada cliente. Este enfoque reduce la desviación del cliente, en la que los dispositivos más rápidos influyen desproporcionadamente en el modelo global, lo que genera actualizaciones del modelo más equilibradas y precisas. APPFL también cuenta con protocolos de comunicación eficientes y técnicas de compresión, como SZ2 y ZFP, que reducen la carga de comunicación durante las actualizaciones del modelo hasta en un 50 %. Estos protocolos garantizan que, incluso con un ancho de banda limitado, los procesos de aprendizaje federado puedan seguir siendo eficientes sin comprometer el rendimiento.
Los investigadores realizaron evaluaciones exhaustivas del rendimiento de APPFL en varios escenarios del mundo real. En un experimento que involucró a 128 clientes, el marco redujo el tiempo de comunicación en un 40% en comparación con las soluciones existentes, manteniendo al mismo tiempo una precisión del modelo de más del 90%. Además, sus estrategias de preservación de la privacidad, incluidas las técnicas criptográficas y de privacidad diferencial, protegieron con éxito los datos confidenciales de los ataques sin afectar significativamente la precisión del modelo. APPFL demostró una reducción del 30% en el tiempo de entrenamiento en un conjunto de datos de atención médica a gran escala, al tiempo que preservaba la privacidad de los datos de los pacientes, lo que lo convierte en una solución viable para entornos sensibles a la privacidad. Otra prueba en servicios financieros mostró que las estrategias de agregación adaptativa de APPFL llevaron a predicciones más precisas de los riesgos de impago de préstamos en comparación con los métodos tradicionales a pesar de la heterogeneidad de los datos en diferentes instituciones financieras.
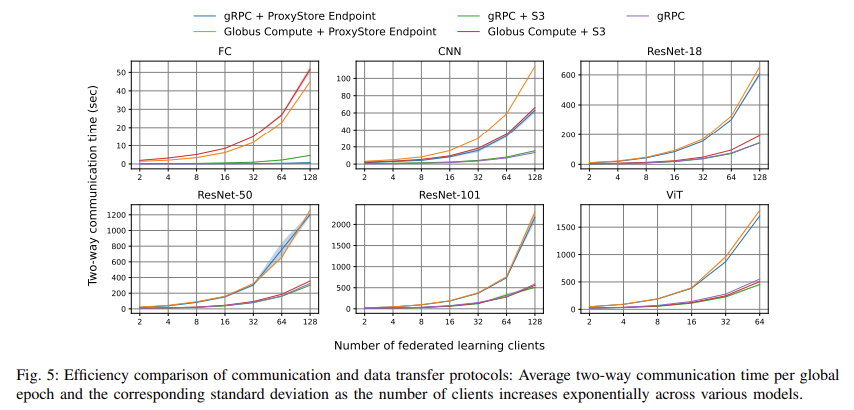
Los resultados de rendimiento también destacan la capacidad de APPFL para manejar modelos grandes de manera eficiente. Por ejemplo, al entrenar un modelo Vision Transformer con 88 millones de parámetros, APPFL logró una reducción del tiempo de comunicación del 15 % por época. Esta reducción es fundamental en escenarios en los que son necesarias actualizaciones oportunas del modelo, como la gestión de la red eléctrica o los diagnósticos médicos en tiempo real. El marco también tuvo un buen desempeño en configuraciones de aprendizaje federado vertical, donde diferentes clientes tienen características distintas del mismo conjunto de datos, lo que demuestra su versatilidad en varios paradigmas de aprendizaje federado.

En conclusión, APPFL es un avance significativo en el aprendizaje federado, que aborda los desafíos centrales de la heterogeneidad de los datos, la disparidad computacional y la seguridad. Al proporcionar un marco extensible que integra estrategias de agregación avanzadas y tecnologías que preservan la privacidad, APPFL mejora la eficiencia y la precisión de los modelos de aprendizaje federado. Su capacidad para reducir los tiempos de comunicación hasta en un 40% y los tiempos de entrenamiento en un 30%, manteniendo al mismo tiempo altos niveles de privacidad y precisión del modelo, lo posiciona como una solución líder para el aprendizaje automático descentralizado. La adaptabilidad del marco a diferentes escenarios de aprendizaje federado, desde la atención médica hasta las finanzas, garantiza que desempeñará un papel crucial en el futuro de la IA segura y distribuida.
Echa un vistazo a la Papel y GitHubTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc. Como ingeniero y emprendedor visionario, Asif está comprometido con aprovechar el potencial de la inteligencia artificial para el bien social. Su iniciativa más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad de noticias sobre aprendizaje automático y aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)