Diffusion Reuse MOtion (Dr. Mo): Un modelo de difusión para la generación eficiente de videos con reutilización de movimiento

Mediante el uso de modelos avanzados de inteligencia artificial, la generación de videos implica la creación de imágenes en movimiento a partir de descripciones textuales o imágenes estáticas. Esta área de investigación busca producir videos realistas de alta calidad y al mismo tiempo superar importantes desafíos computacionales. Los videos generados por IA encuentran aplicaciones en diversos campos, como la cinematografía, la educación y las simulaciones de video, y ofrecen una forma eficiente de automatizar la producción de videos. Sin embargo, las demandas computacionales para generar videos largos y visualmente consistentes siguen siendo un obstáculo clave, lo que impulsa a los investigadores a desarrollar métodos que equilibren la calidad y la eficiencia en la generación de videos.
Un problema importante en la generación de videos es el enorme costo computacional asociado con la creación de cada fotograma. El proceso iterativo de eliminación de ruido, en el que el ruido se elimina gradualmente de una representación latente hasta que se logra la calidad visual deseada, requiere mucho tiempo. Este proceso debe repetirse para cada fotograma de un video, lo que hace que el tiempo y los recursos necesarios para producir videos de alta resolución o de larga duración sean prohibitivos. El desafío, por lo tanto, es optimizar este proceso sin sacrificar la calidad y la consistencia del contenido del video.
Los métodos existentes, como los modelos probabilísticos de difusión de eliminación de ruido (DDPM) y los modelos de difusión de video (VDM), han generado videos de alta calidad con éxito. Estos modelos refinan los fotogramas de video mediante pasos de eliminación de ruido, lo que produce imágenes detalladas y coherentes. Sin embargo, cada fotograma se somete a un proceso de eliminación de ruido completo, lo que aumenta las demandas computacionales. Soluciones como el cambio latente intentan reutilizar las características latentes en los fotogramas, pero aún requieren mejoras en términos de eficiencia. Estos métodos tienen dificultades para generar videos de larga duración o alta resolución sin una sobrecarga computacional significativa, lo que genera la necesidad de enfoques más efectivos.
Un equipo de investigación ha introducido la red Diffusion Reuse Motion (Dr. Mo) para resolver la ineficiencia de los modelos de generación de vídeo actuales. Dr. Mo reduce la carga computacional aprovechando la coherencia del movimiento en fotogramas de vídeo consecutivos. Los investigadores observaron que los patrones de ruido se mantienen constantes en muchos fotogramas en las primeras etapas del proceso de eliminación de ruido. Dr. Mo utiliza esta coherencia para propagar el ruido de grano grueso de un fotograma al siguiente, eliminando los cálculos redundantes. Además, el Selector de pasos de eliminación de ruido (DSS), una metared, determina dinámicamente el paso adecuado para cambiar de la propagación del movimiento a la eliminación de ruido tradicional, optimizando aún más el proceso de generación.
En detalle, el Dr. Mo construye matrices de movimiento para capturar características semánticas de movimiento entre fotogramas. Estas matrices se forman a partir de las características latentes extraídas por un decodificador tipo U-Net, que analiza el movimiento entre fotogramas de vídeo consecutivos. A continuación, el DSS evalúa qué pasos de eliminación de ruido pueden reutilizar las estimaciones basadas en el movimiento en lugar de volver a calcular cada fotograma desde cero. Este enfoque permite que el sistema equilibre la eficiencia y la calidad del vídeo. El Dr. Mo reutiliza los patrones de ruido para acelerar el proceso en las primeras etapas de eliminación de ruido. A medida que la generación del vídeo se acerca a su finalización, se restauran detalles más precisos a través del modelo de difusión tradicional, lo que garantiza una alta calidad visual. El resultado es un sistema más rápido que genera fotogramas de vídeo manteniendo la claridad y el realismo.
El equipo de investigación evaluó exhaustivamente el rendimiento de Dr. Mo en conjuntos de datos conocidos, como UCF-101 y MSR-VTT. Los resultados demostraron que Dr. Mo no solo redujo significativamente el tiempo computacional, sino que también mantuvo una alta calidad de video. Al generar videos de 16 fotogramas con una resolución de 256×256, Dr. Mo logró una mejora de velocidad cuatro veces mayor en comparación con Latent-Shift, completando la tarea en solo 6,57 segundos, mientras que Latent-Shift requirió 23,4 segundos. Para videos con una resolución de 512×512, Dr. Mo fue 1,5 veces más rápido que los modelos de la competencia como SimDA y LaVie, generando videos en 23,62 segundos en comparación con los 34,2 segundos de SimDA. A pesar de esta aceleración, Dr. Mo preservó el 96% de la puntuación de inicio (IS) e incluso mejoró la puntuación de distancia de video de Fréchet (FVD), lo que indica que produjo videos visualmente coherentes estrechamente alineados con la realidad del terreno.
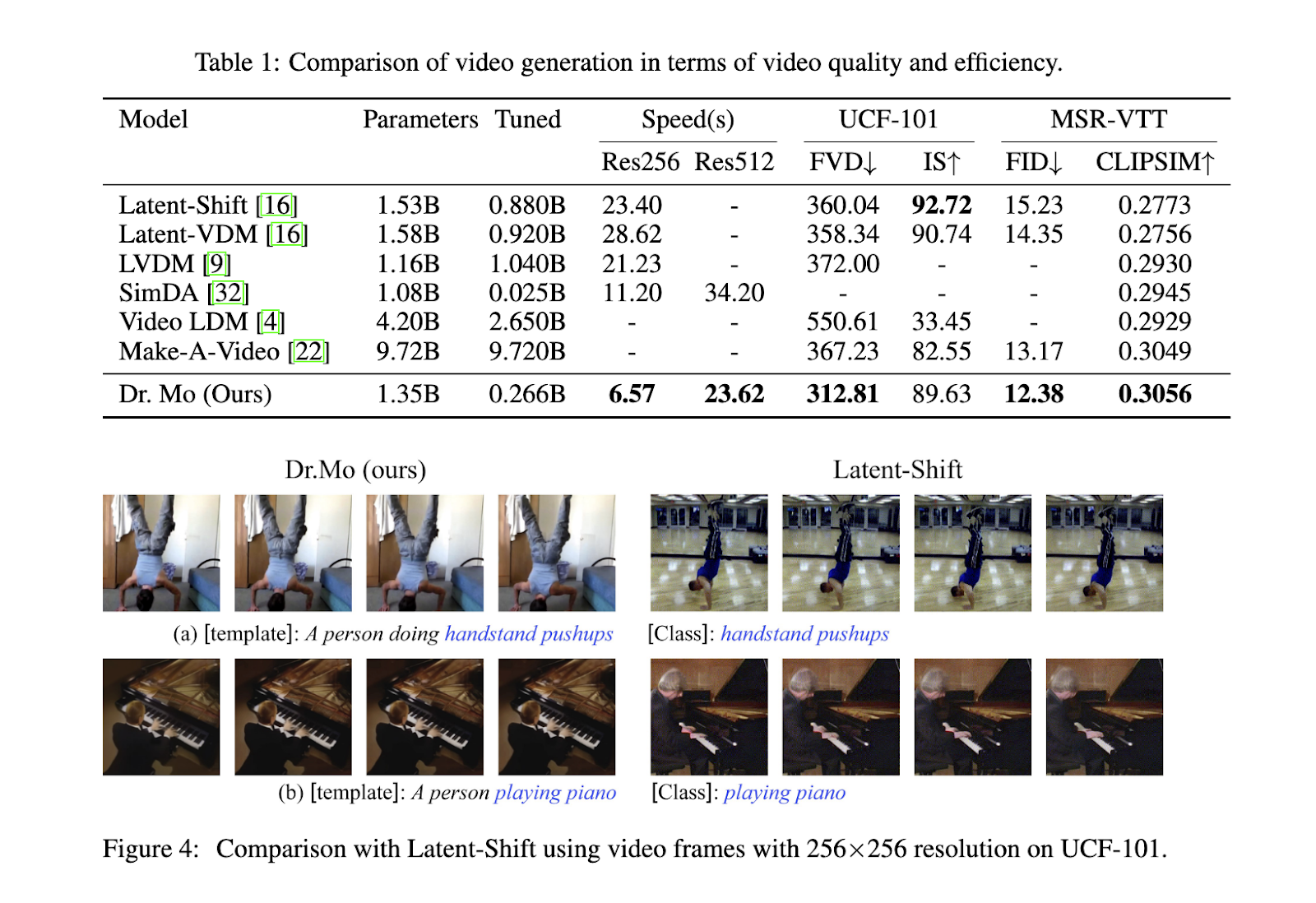
Las métricas de calidad de video enfatizaron aún más la eficiencia del Dr. Mo. En el conjunto de datos UCF-101, el Dr. Mo logró una puntuación FVD de 312,81, superando significativamente a Latent-Shift, que tuvo una puntuación de 360,04. El Dr. Mo obtuvo una puntuación de 0,3056 en la métrica CLIPSIM en el conjunto de datos MSR-VTT, una medida de alineación semántica entre fotogramas de video y entradas de texto. Esta puntuación superó a todos los modelos probados, lo que demuestra su rendimiento superior en tareas de generación de texto a video. Además, el Dr. Mo se destacó en aplicaciones de transferencia de estilo, donde la información de movimiento de videos del mundo real se aplicó a los primeros fotogramas transferidos por estilo, lo que produjo resultados consistentes y realistas en todos los fotogramas generados.
En conclusión, el Dr. Mo proporciona un avance significativo en el campo de la generación de vídeo al ofrecer un método que reduce drásticamente las demandas computacionales sin comprometer la calidad del vídeo. Al reutilizar de forma inteligente la información de movimiento y emplear un selector de pasos de eliminación de ruido dinámico, el sistema genera de forma eficiente vídeos de alta calidad en menos tiempo. Este equilibrio entre eficiencia y calidad marca un avance fundamental para abordar los desafíos asociados con la generación de vídeo.
Echa un vistazo a la Papel y ProyectoTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Nikhil es consultor en prácticas en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA y el aprendizaje automático que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de los materiales, está explorando nuevos avances y creando oportunidades para contribuir.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)