Trust-Align: un marco de IA para mejorar la confiabilidad de la generación aumentada por recuperación en modelos de lenguaje de gran tamaño

Los modelos de lenguaje de gran tamaño (LLM, por sus siglas en inglés) han ganado una atención significativa debido a su potencial para mejorar varias aplicaciones de inteligencia artificial, en particular en el procesamiento del lenguaje natural. Cuando se integran en marcos como Retrieval-Augmented Generation (RAG), estos modelos apuntan a refinar el resultado de los sistemas de IA extrayendo información de documentos externos en lugar de depender únicamente de su base de conocimiento interna. Este enfoque es crucial para garantizar que el contenido generado por IA siga siendo factualmente preciso, lo cual es un problema persistente en los modelos que no están vinculados a fuentes externas.
Un problema clave al que se enfrenta esta área es la aparición de alucinaciones en los modelos de aprendizaje a distancia, en los que estos generan información aparentemente plausible pero que es incorrecta en los hechos. Esto se vuelve especialmente problemático en tareas que requieren una gran precisión, como responder a preguntas fácticas o brindar asistencia en los campos legal y educativo. Muchos modelos de aprendizaje a distancia de última generación dependen en gran medida de la información de conocimiento paramétrico aprendida durante el entrenamiento, lo que los hace inadecuados para tareas en las que las respuestas deben provenir estrictamente de documentos específicos. Para abordar este problema, se deben introducir nuevos métodos para evaluar y mejorar la confiabilidad de estos modelos.
Los métodos tradicionales se centran en evaluar los resultados finales de los LLM dentro del marco de RAG, pero pocos exploran la confiabilidad intrínseca de los modelos en sí. Actualmente, los enfoques como las técnicas de incitación alinean las respuestas de los modelos con la información basada en documentos. Sin embargo, estos métodos a menudo fallan, ya sea porque no adaptan los modelos o porque dan como resultado resultados demasiado sensibles que responden de manera inapropiada. Los investigadores identificaron la necesidad de una nueva métrica para medir el desempeño de los LLM y garantizar que los modelos brinden respuestas fundamentadas y confiables basadas únicamente en los documentos recuperados.
Investigadores de la Universidad de Tecnología y Diseño de Singapur, en colaboración con los Laboratorios Nacionales DSO, introdujeron un nuevo marco llamado “TRUST-ALIGN”. Este método se centra en mejorar la fiabilidad de los LLM en las tareas RAG alineando sus resultados para proporcionar respuestas más precisas y respaldadas por documentos. Los investigadores también desarrollaron una nueva métrica de evaluación, TRUST-SCORE, que evalúa los modelos en función de múltiples dimensiones, como su capacidad para determinar si se puede responder a una pregunta utilizando los documentos proporcionados y su precisión al citar fuentes relevantes.
TRUST-ALIGN funciona ajustando los LLM mediante un conjunto de datos que contiene 19.000 pares de preguntas y documentos, cada uno etiquetado con respuestas preferidas y no preferidas. Este conjunto de datos se creó sintetizando respuestas naturales de LLM como GPT-4 y respuestas negativas derivadas de alucinaciones comunes. La principal ventaja de este método radica en su capacidad para optimizar directamente el comportamiento de los LLM para proporcionar negativas fundamentadas cuando sea necesario, lo que garantiza que los modelos solo respondan a las preguntas cuando haya suficiente información disponible. Mejora la precisión de las citas de los modelos al guiarlos para que hagan referencia a las partes más relevantes de los documentos, lo que evita la sobrecitación o la atribución incorrecta.
En cuanto al rendimiento, la introducción de TRUST-ALIGN mostró mejoras sustanciales en varios conjuntos de datos de referencia. Por ejemplo, cuando se evaluó en el conjunto de datos ASQA, LLaMA-3-8b, alineado con TRUST-ALIGN, logró un aumento del 10,73 % en el TRUST-SCORE, superando a modelos como GPT-4 y Claude-3.5 Sonnet. En el conjunto de datos QAMPARI, el método superó a los modelos de referencia en un 29,24 %, mientras que el conjunto de datos ELI5 mostró un aumento del rendimiento del 14,88 %. Estas cifras demuestran la eficacia del marco TRUST-ALIGN para generar respuestas más precisas y confiables en comparación con otros métodos.
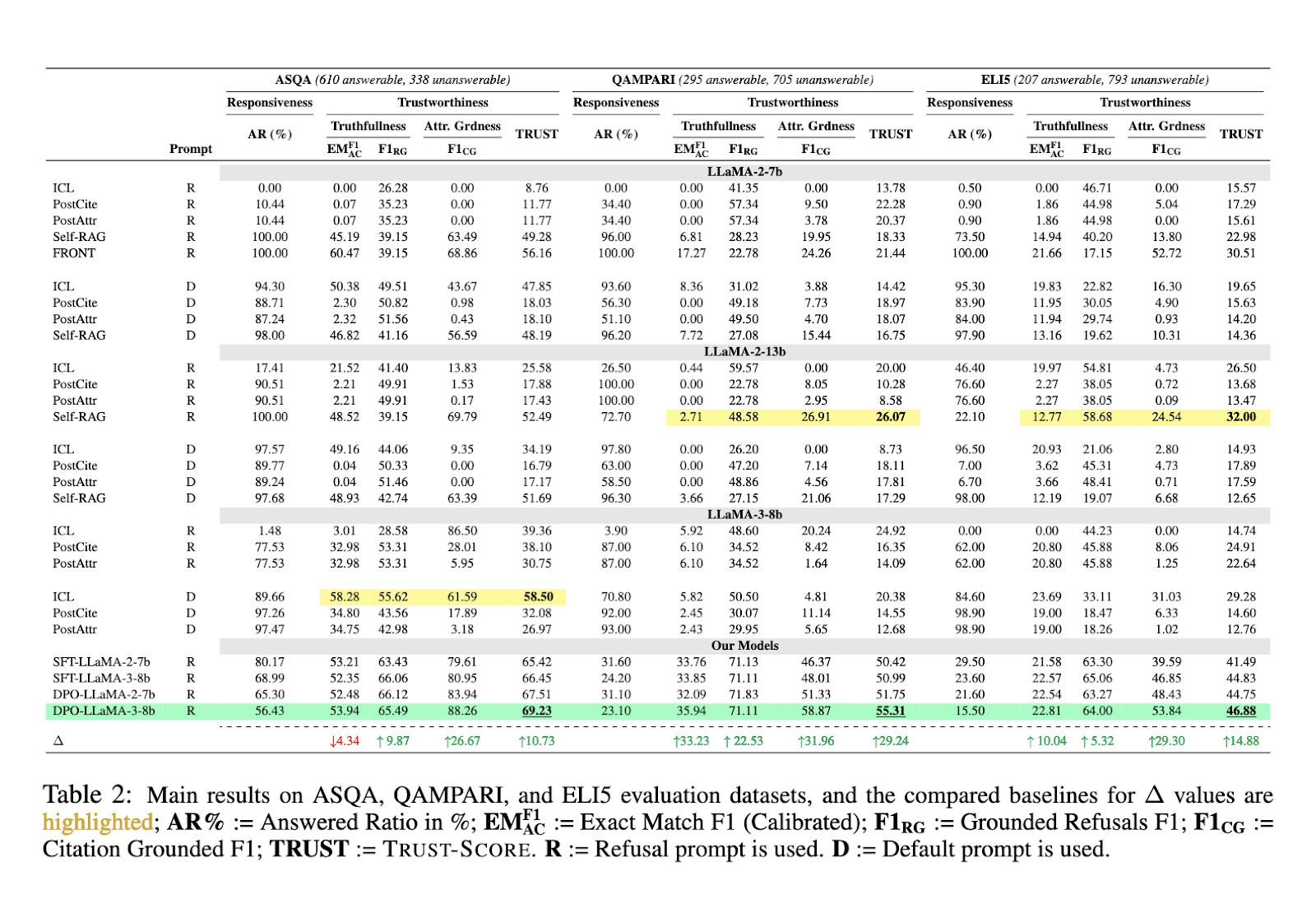
Una de las mejoras significativas aportadas por TRUST-ALIGN fue la capacidad de los modelos para negarse a responder cuando los documentos disponibles no eran suficientes. En ASQA, la métrica de rechazo mejoró en un 9,87%, mientras que en QAMPARI mostró un aumento aún mayor del 22,53%. La capacidad de negarse se destacó aún más en ELI5, donde la mejora alcanzó el 5,32%. Estos resultados indican que el marco mejoró la precisión de los modelos y redujo significativamente su tendencia a responder en exceso las preguntas sin una justificación adecuada a partir de los documentos proporcionados.
Otro logro notable de TRUST-ALIGN fue la mejora de la calidad de las citas. En ASQA, los puntajes de precisión de las citas aumentaron un 26,67%, mientras que en QAMPARI, la recuperación de citas aumentó un 31,96%. El conjunto de datos ELI5 también mostró una mejora del 29,30%. Esta mejora en la fundamentación de las citas garantiza que los modelos brinden respuestas bien sustentadas, lo que los hace más confiables para los usuarios que confían en sistemas basados en hechos.
En conclusión, esta investigación aborda un problema crítico en la implementación de modelos lingüísticos de gran tamaño en aplicaciones del mundo real. Al desarrollar TRUST-SCORE y el marco TRUST-ALIGN, los investigadores han creado un método confiable para alinear los LLM hacia la generación de respuestas basadas en documentos, minimizando las alucinaciones y mejorando la confiabilidad general. Este avance es particularmente significativo en campos donde la precisión y la capacidad de proporcionar información bien citada son primordiales, allanando el camino para sistemas de IA más confiables en el futuro.
Echa un vistazo a la Papel y Página de GitHubTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Nikhil es consultor en prácticas en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA y el aprendizaje automático que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de los materiales, está explorando nuevos avances y creando oportunidades para contribuir.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)