Investigadores de la Universidad Rice presentan RAG-Modulo: un marco de inteligencia artificial para mejorar la eficiencia de los agentes basados en LLM en tareas secuenciales

La resolución de tareas secuenciales que requieren múltiples pasos plantea desafíos importantes en robótica, en particular en aplicaciones del mundo real donde los robots operan en entornos inciertos. Estos entornos suelen ser estocásticos, lo que significa que los robots enfrentan variabilidad en sus acciones y observaciones. Un objetivo central en robótica es mejorar la eficiencia de los sistemas robóticos al permitirles manejar tareas de largo plazo, que requieren un razonamiento sostenido durante períodos prolongados de tiempo. La toma de decisiones se complica aún más por los sensores limitados de los robots y la observabilidad parcial de su entorno, que restringen su capacidad para comprender completamente su entorno. En consecuencia, los investigadores buscan continuamente nuevos métodos para mejorar la forma en que los robots perciben, aprenden y actúan, haciéndolos más autónomos y confiables.
El principal problema de los investigadores en este ámbito se centra en la incapacidad de los robots para aprender de sus acciones pasadas de forma eficiente. Los robots dependen de métodos como el aprendizaje por refuerzo (AR) para mejorar su rendimiento. Sin embargo, el AR requiere muchos ensayos, a menudo millones, para que un robot adquiera la capacidad de completar tareas. Esto es poco práctico, especialmente en entornos parcialmente observables donde los robots no pueden interactuar de forma continua debido a los riesgos asociados. Además, los sistemas existentes, como los modelos de toma de decisiones basados en grandes modelos de lenguaje (LLM), tienen dificultades para retener interacciones pasadas, lo que obliga a los robots a repetir errores o a volver a aprender estrategias que ya han experimentado. Esta incapacidad para aplicar el conocimiento previo dificulta su eficacia en tareas complejas y a largo plazo.
Aunque los agentes basados en aprendizaje por refuerzo y aprendizaje por lentitud han demostrado ser prometedores, presentan varias limitaciones. Por ejemplo, el aprendizaje por refuerzo requiere una gran cantidad de datos y un esfuerzo manual significativo para diseñar funciones de recompensa. Por otro lado, los agentes basados en aprendizaje por refuerzo, que se utilizan para generar secuencias de acciones, a menudo carecen de la capacidad de refinar sus acciones en función de experiencias pasadas. Los métodos recientes han incorporado críticas para evaluar la viabilidad de las decisiones. Sin embargo, aún tienen deficiencias en un área crítica: la capacidad de almacenar y recuperar conocimiento útil de interacciones pasadas. Esta brecha significa que, si bien estos sistemas pueden funcionar bien en tareas estáticas o de corto plazo, su rendimiento se degrada en entornos dinámicos, lo que requiere un aprendizaje y una adaptación continuos.
Los investigadores de la Universidad Rice han presentado el marco RAG-Modulo. Este novedoso sistema mejora los agentes basados en LLM al equiparlos con una memoria de interacción. Esta memoria almacena decisiones pasadas, lo que permite a los robots recordar y aplicar experiencias relevantes cuando se enfrentan a tareas similares en el futuro. Al hacerlo, el sistema mejora las capacidades de toma de decisiones a lo largo del tiempo. Además, el marco utiliza un conjunto de críticos para evaluar la viabilidad de las acciones, ofreciendo retroalimentación basada en la sintaxis, la semántica y la política de bajo nivel. Estos críticos garantizan que las acciones del robot sean ejecutables y contextualmente apropiadas. Es importante destacar que este enfoque elimina la necesidad de un ajuste manual extenso, ya que la memoria se adapta y ajusta automáticamente las indicaciones para el LLM en función de las experiencias pasadas.
El marco RAG-Modulo mantiene una memoria dinámica de las interacciones del robot, lo que le permite recuperar acciones y resultados pasados como ejemplos en contexto. Cuando se enfrenta a una nueva tarea, el marco recurre a esta memoria para guiar el proceso de toma de decisiones del robot, evitando así errores repetidos y mejorando la eficiencia. Los críticos integrados en el sistema actúan como verificadores, proporcionando retroalimentación en tiempo real sobre la viabilidad de las acciones. Por ejemplo, si un robot intenta realizar una acción inviable, como recoger un objeto en un espacio ocupado, los críticos sugerirán medidas correctivas. A medida que el robot continúa realizando tareas, su memoria se expande y se vuelve más capaz de manejar secuencias cada vez más complejas. Este enfoque garantiza un aprendizaje continuo sin reprogramación frecuente ni intervención humana.
El rendimiento de RAG-Modulo se ha probado rigurosamente en dos entornos de referencia: BabyAI y AlfWorld. El sistema demostró una marcada mejora con respecto a los modelos de referencia, logrando mayores tasas de éxito y reduciendo la cantidad de acciones inviables. En BabyAI-Synth, por ejemplo, RAG-Modulo logró una tasa de éxito del 57%, mientras que el modelo competidor más cercano, LLM-Planner, alcanzó solo el 43%. La brecha de rendimiento se amplió en el más complejo BabyAI-BossLevel, donde RAG-Modulo alcanzó una tasa de éxito del 57% en comparación con el 37% de LLM-Planner. De manera similar, en el entorno AlfWorld, RAG-Modulo exhibió una eficiencia superior en la toma de decisiones, con menos acciones fallidas y tiempos de finalización de tareas más cortos. En el entorno AlfWorld-Seen, el marco logró una tasa promedio de inejecutabilidad de 0,09 en comparación con 0,16 para LLM-Planner. Estos resultados demuestran la capacidad del sistema para generalizar a partir de experiencias anteriores y optimizar el rendimiento del robot.
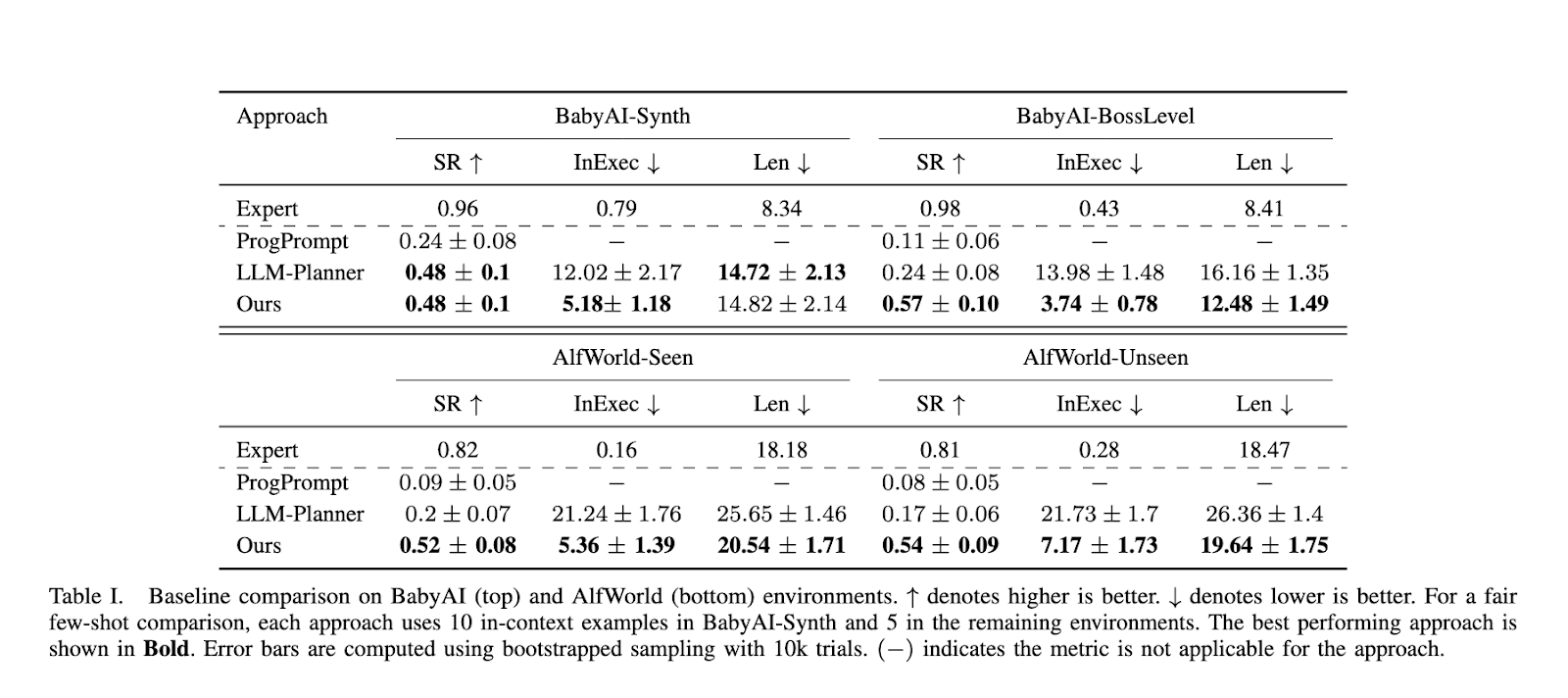
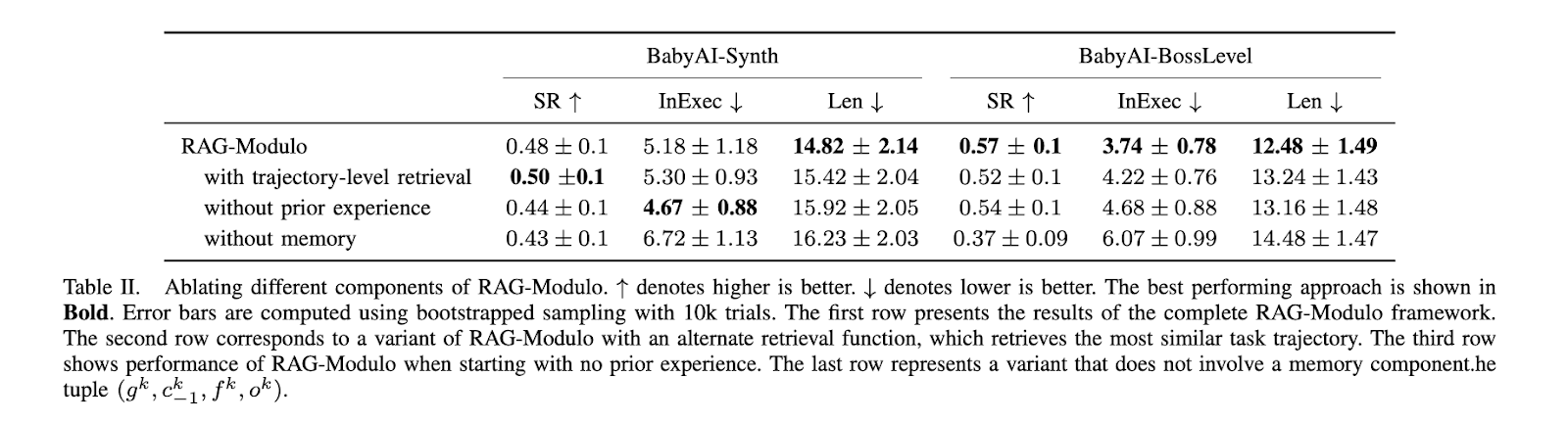
En cuanto a la ejecución de tareas, RAG-Modulo también redujo la duración media de los episodios, lo que pone de relieve su capacidad para realizar tareas de forma más eficiente. En BabyAI-Synth, la duración media de los episodios fue de 12,48 pasos, mientras que otros modelos requerían más de 16 pasos para completar las mismas tareas. Esta reducción de la duración de los episodios es significativa porque aumenta la eficiencia operativa y reduce los costes computacionales asociados a la ejecución del modelo de lenguaje durante períodos más prolongados. Al acortar la cantidad de acciones necesarias para alcanzar un objetivo, el marco reduce la complejidad general de la ejecución de tareas y, al mismo tiempo, garantiza que el robot aprenda de cada decisión que toma.
El marco RAG-Modulo representa un avance sustancial que permite a los robots aprender de interacciones pasadas y aplicar este conocimiento a tareas futuras. Al abordar el desafío crítico de la retención de memoria en agentes basados en LLM, el sistema proporciona una solución escalable para manejar tareas complejas de largo plazo. Su capacidad para combinar la memoria con la retroalimentación en tiempo real de los críticos garantiza que los robots puedan mejorar continuamente sin requerir una intervención manual excesiva. Este avance marca un paso significativo hacia sistemas robóticos más autónomos e inteligentes capaces de aprender y evolucionar en entornos del mundo real.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Nikhil es consultor en prácticas en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA y el aprendizaje automático que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de los materiales, está explorando nuevos avances y creando oportunidades para contribuir.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)