Investigadores de John Hopkins y Samaya AI proponen un Promptriever: un recuperador de disparo cero entrenado a partir de un nuevo conjunto de datos de recuperación basado en instrucciones

Los modelos de recuperación de información (IR) enfrentan desafíos importantes a la hora de ofrecer experiencias de búsqueda transparentes e intuitivas. Las metodologías actuales se basan principalmente en una única puntuación de similitud semántica para hacer coincidir las consultas con los pasajes, lo que genera una experiencia de usuario potencialmente opaca. Este enfoque a menudo requiere que los usuarios participen en un proceso engorroso de encontrar palabras clave específicas, aplicar varios filtros en la configuración de búsqueda avanzada y refinar iterativamente sus consultas en función de resultados de búsqueda anteriores. La necesidad de que los usuarios elaboren la consulta “perfecta” para recuperar los pasajes deseados resalta las limitaciones de los sistemas IR existentes a la hora de proporcionar capacidades de búsqueda eficientes y fáciles de usar.
Los desarrollos recientes en los modelos IR han introducido el uso de instrucciones, yendo más allá del entrenamiento tradicional de recuperadores densos que se centraba en funciones de similitud similares a la concordancia a nivel de frase. Los primeros esfuerzos como TART e Instructor incorporaron prefijos de tareas simples durante el entrenamiento. Modelos más recientes como E5-Mistral, GritLM y NV-Retriever han ampliado este enfoque al ampliar tanto el tamaño del conjunto de datos como del modelo. Estos modelos más nuevos suelen adoptar el conjunto de instrucciones propuesto por E5-Mistral. Sin embargo, si bien estos avances representan avances en el campo, todavía dependen principalmente de un único conjunto de instrucciones y no abordan completamente los desafíos de brindar a los usuarios una experiencia de búsqueda más transparente y flexible.
Investigadores de la Universidad Johns Hopkins y Samaya AI han presentado Promptriever, un enfoque único para la recuperación de información que permite el control mediante indicaciones en lenguaje natural. Este modelo permite a los usuarios ajustar dinámicamente los criterios de relevancia utilizando descripciones conversacionales, eliminando la necesidad de múltiples búsquedas o filtros complejos. Por ejemplo, al buscar películas de James Cameron, los usuarios pueden simplemente especificar criterios como “Los documentos relevantes no están codirigidos y se crearon antes de 2022”. Promptriever se basa en una arquitectura de recuperación de codificador dual y utiliza modelos de lenguaje grandes como LLaMA-2 7B como columna vertebral. Si bien los modelos de lenguaje previamente entrenados pueden adaptarse a instrucciones de lenguaje natural, el entrenamiento de IR tradicional a menudo compromete esta capacidad al centrarse únicamente en optimizar las puntuaciones de similitud semántica de los pasajes de consulta. Promptriever aborda esta limitación, manteniendo la capacidad de seguir instrucciones después del entrenamiento IR.
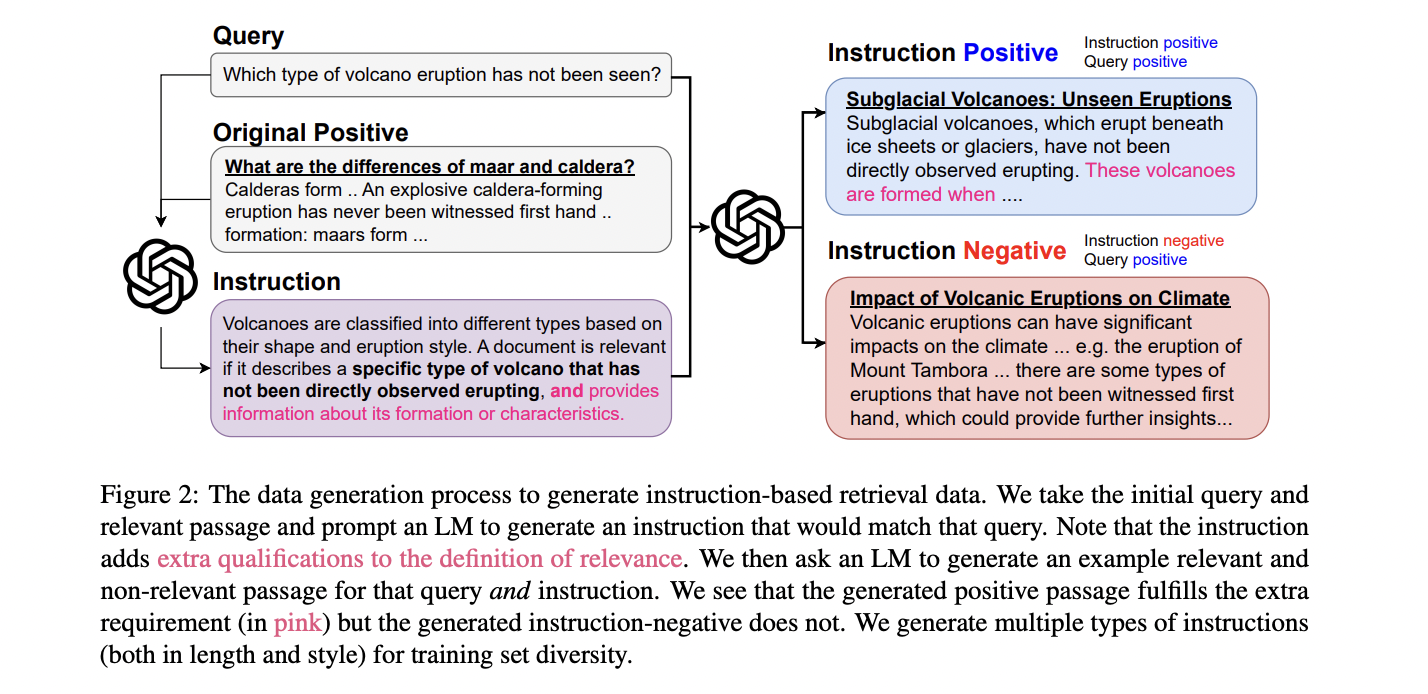
Promptriever utiliza un proceso de generación de datos de dos partes para entrenar su bicodificador para la recuperación basada en instrucciones. El modelo se basa en el conjunto de datos de MS MARCO, utilizando la versión tevatron-msmarco-aug con negativos duros. El primer paso implica la generación de instrucciones, donde Llama-3-70B-Instruct crea instrucciones diversas y específicas para cada consulta, que varían en longitud y estilo. Estas instrucciones mantienen la relevancia con los pasajes positivos originales, según lo verificado por FollowIR-7B.
El segundo paso, la minería de instrucciones negativas, introduce pasajes que son positivos para consultas pero negativos para instrucciones. Este proceso alienta al modelo a considerar tanto la consulta como la instrucción durante el entrenamiento. GPT-4 genera estos pasajes, que luego se filtran utilizando FollowIR-7B para garantizar la precisión. La validación humana confirma la eficacia de este proceso de filtrado, alcanzando la concordancia modelo-humano el 84%.
Este enfoque integral de aumento de datos permite a Promptriever adaptar sus criterios de relevancia de forma dinámica en función de instrucciones en lenguaje natural, mejorando significativamente sus capacidades de recuperación en comparación con los modelos IR tradicionales.
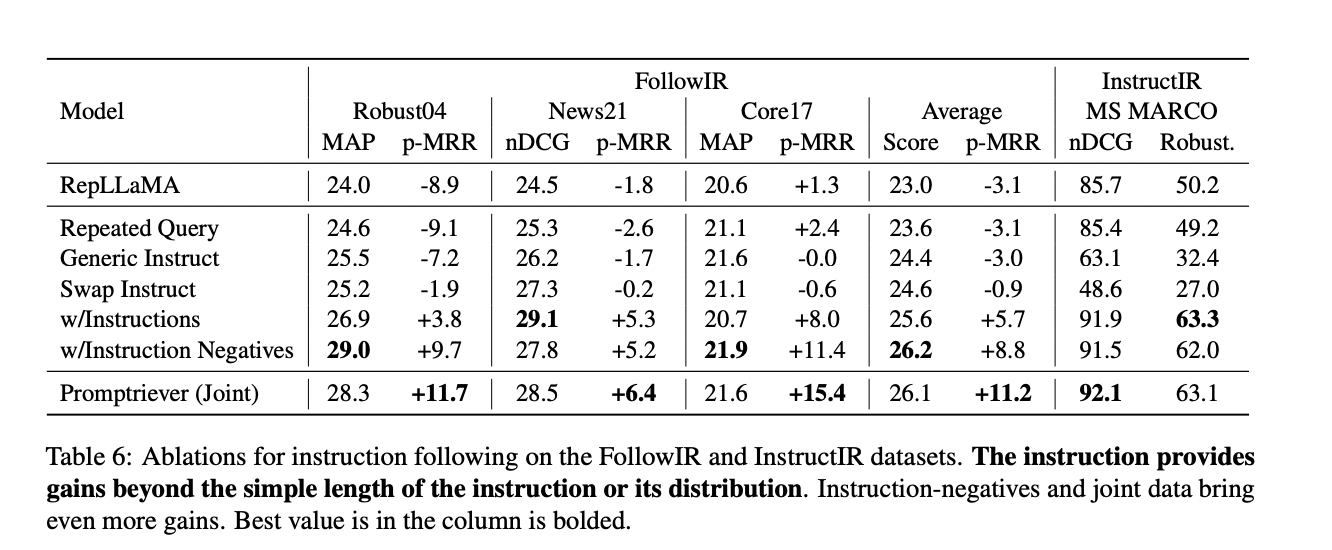
Promptriever demuestra un desempeño superior en el seguimiento de instrucciones mientras mantiene sólidas capacidades de recuperación estándar. Supera al RepLLaMA original por un margen significativo, con mejoras de +14,3 p-MRR y +3,1 en nDCG/MAP, estableciéndose como el recuperador denso de mayor rendimiento. Si bien los modelos con codificador cruzado logran los mejores resultados debido a su ventaja computacional, el rendimiento de Promptriever como modelo bicodificador es comparable y más eficiente.
En tareas de recuperación estándar sin instrucciones, Promptriever se desempeña a la par con RepLLaMA para tareas dentro del dominio (MS MARCO) y tareas fuera del dominio (BEIR). Además, Promptriever muestra un 44 % menos de variación en las indicaciones en comparación con RepLLaMA y un 77 % menos que BM25, lo que indica una mayor solidez ante las variaciones de entrada. Estos resultados subrayan la eficacia del enfoque basado en instrucciones de Promptriever para mejorar tanto la precisión de la recuperación como la adaptabilidad a diversas consultas.
Este estudio presenta Promptriever, un avance significativo en la recuperación de información, que presenta el primer recuperador rápido de disparo cero. Desarrollado utilizando un conjunto de datos único basado en instrucciones derivado de MS MARCO, este modelo demuestra un rendimiento superior tanto en tareas de recuperación estándar como en seguimiento de instrucciones. Al adaptar dinámicamente sus criterios de relevancia en función de instrucciones por consulta, Promptriever muestra la aplicación exitosa de técnicas de estimulación desde modelos de lenguaje hasta recuperadores densos. Esta innovación allana el camino para sistemas de recuperación de información más flexibles y fáciles de usar, cerrando la brecha entre el procesamiento del lenguaje natural y las capacidades de búsqueda eficientes.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de 52k+ ML
Asjad es consultor interno en Marktechpost. Está cursando B.Tech en ingeniería mecánica en el Instituto Indio de Tecnología, Kharagpur. Asjad es un entusiasta del aprendizaje automático y el aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en la atención médica.