torchao: una biblioteca nativa de PyTorch que hace que los modelos sean más rápidos y más pequeños aprovechando los tipos D de bits bajos, la cuantificación y la dispersión

PyTorch se ha lanzado oficialmente torchaouna biblioteca nativa integral diseñada para optimizar los modelos de PyTorch para lograr un mejor rendimiento y eficiencia. El lanzamiento de esta biblioteca es un hito en la optimización de modelos de aprendizaje profundo, ya que proporciona a los usuarios un conjunto de herramientas accesible que aprovecha técnicas avanzadas como tipos de bits bajos, cuantificación y escasez. La biblioteca está escrita predominantemente en código PyTorch, lo que garantiza la facilidad de uso y la integración para los desarrolladores que trabajan en cargas de trabajo de inferencia y capacitación.
Características clave del torchao
- Proporciona soporte integral para varios modelos de IA generativa, como Llama 3 y modelos de difusión, lo que garantiza compatibilidad y facilidad de uso.
- Demuestra impresionantes ganancias de rendimiento, logrando hasta un 97% de aceleración y reducciones significativas en el uso de memoria durante la inferencia y el entrenamiento del modelo.
- Ofrece técnicas de cuantificación versátiles, incluidos tipos d de bits bajos como int4 y float8, para optimizar modelos para inferencia y entrenamiento.
- Admite la cuantificación de activación dinámica y la escasez para varios tipos, lo que mejora la flexibilidad de la optimización del modelo.
- Cuenta con Quantization Aware Training (QAT) para minimizar la degradación de la precisión que puede ocurrir con la cuantificación de bits bajos.
- Proporciona flujos de trabajo de comunicación y computación de baja precisión y fáciles de usar para la capacitación que son compatibles con las capas ‘nn.Linear’ de PyTorch.
- Introduce soporte experimental para optimizadores de 8 y 4 bits, que sirve como reemplazo directo de AdamW para optimizar el entrenamiento de modelos.
- Se integra perfectamente con los principales proyectos de código abierto, como los transformadores y difusores HuggingFace, y sirve como implementación de referencia para acelerar modelos.
Estas características clave establecen a torchao como una biblioteca de optimización de modelos de aprendizaje profundo versátil y eficiente.
Técnicas avanzadas de cuantificación
Una de las características destacadas de torchao es su sólido soporte para la cuantificación. Los algoritmos de cuantificación de inferencia de la biblioteca funcionan sobre modelos arbitrarios de PyTorch que contienen capas ‘nn.Linear’, proporcionando cuantificación de activación dinámica y de solo peso para varios tipos de d y diseños dispersos. Los desarrolladores pueden seleccionar las técnicas de cuantificación más adecuadas utilizando la API ‘quantize_’ de nivel superior. Esta API incluye opciones para modelos vinculados a memoria, como int4_weight_only e int8_weight_only, y modelos vinculados a computación. Para los modelos vinculados a la computación, torchao puede realizar una cuantificación float8, lo que proporciona flexibilidad adicional para la optimización del modelo de alto rendimiento. Además, las técnicas de cuantificación de torchao son altamente componibles, lo que permite la combinación de escasez y cuantificación para mejorar el rendimiento.
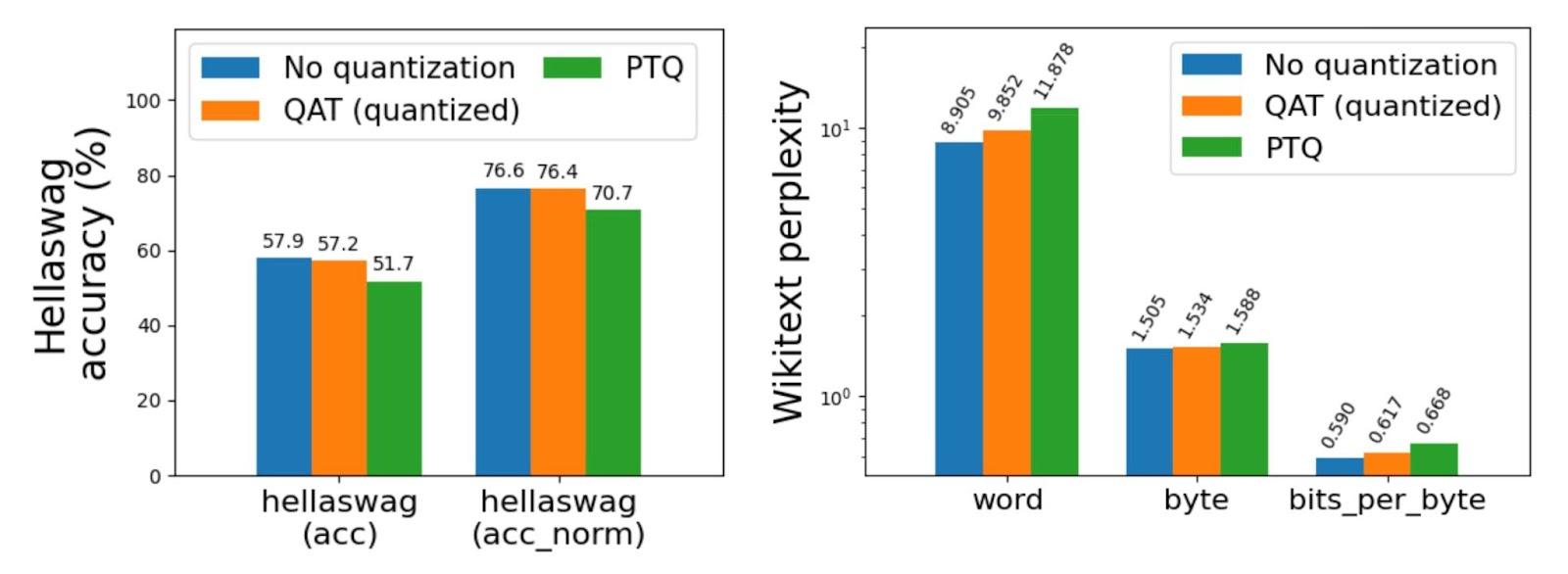
Entrenamiento consciente de la cuantificación (QAT)
Torchao aborda la posible degradación de la precisión asociada con la cuantificación posterior al entrenamiento, particularmente para modelos cuantificados a menos de 4 bits. La biblioteca incluye soporte para Quantization Aware Training (QAT), que se ha demostrado que recupera hasta el 96 % de la degradación de la precisión en puntos de referencia desafiantes como Hellaswag. Esta característica está integrada como una receta de un extremo a otro en torchtune, con un tutorial mínimo para facilitar su implementación. La incorporación de QAT convierte a torchao en una herramienta poderosa para entrenar modelos con cuantificación de bits bajos manteniendo la precisión.
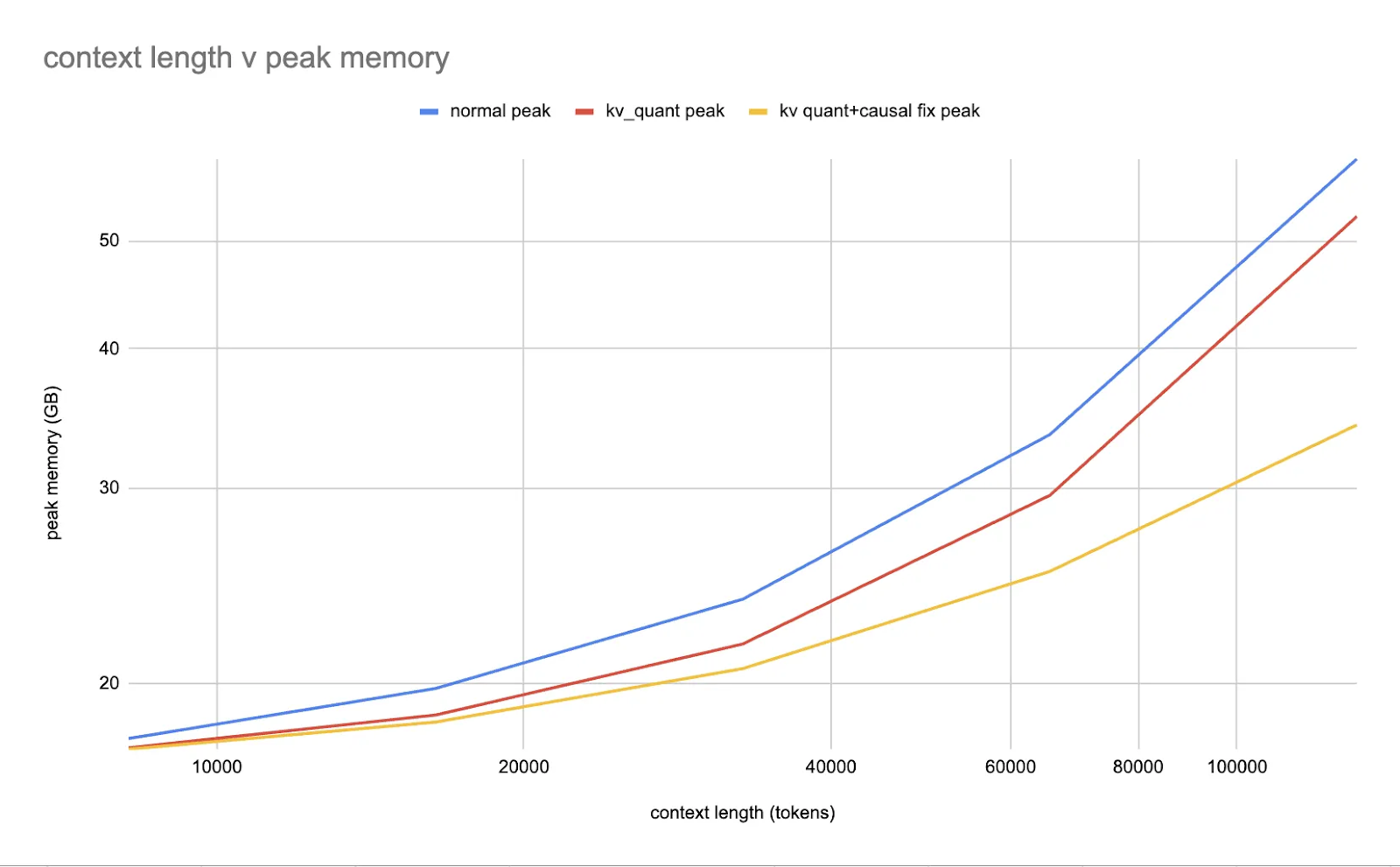
Optimización del entrenamiento con baja precisión
Además de la optimización de la inferencia, torchao ofrece soporte integral para la computación y la comunicación de baja precisión durante el entrenamiento. La biblioteca incluye flujos de trabajo fáciles de usar para reducir la precisión de la computación de entrenamiento y las comunicaciones distribuidas, comenzando con float8 para las capas `torch.nn.Linear`.
Torchao ha demostrado resultados impresionantes, como una aceleración de 1,5x para el preentrenamiento de Llama 3 70B cuando se usa float8. La biblioteca también proporciona soporte experimental para otras optimizaciones de entrenamiento, como NF4 QLoRA en torchtune, entrenamiento de prototipos int8 y entrenamiento disperso acelerado 2:4. Estas características hacen de torchao una opción atractiva para los usuarios que buscan acelerar el entrenamiento y minimizar el uso de memoria.
Optimizadores de bits bajos
Inspirándose en el trabajo pionero de Bits y Bytes en optimizadores de bits bajos, torchao presenta soporte de prototipo para optimizadores de 8 y 4 bits como reemplazo directo del ampliamente utilizado optimizador AdamW. Esta característica permite a los usuarios cambiar a optimizadores de bits bajos sin problemas, mejorando aún más la eficiencia del entrenamiento del modelo sin modificar significativamente sus bases de código existentes.
Integraciones y desarrollos futuros
Torchao se ha integrado activamente en algunos de los proyectos de código abierto más importantes de la comunidad de aprendizaje automático. Estas integraciones incluyen servir como backend de inferencia para los transformadores HuggingFace, contribuir a los difusores-torchao para acelerar los modelos de difusión y proporcionar recetas QLoRA y QAT en torchtune. Las técnicas de cuantificación de 4 y 8 bits de torchao también son compatibles con el proyecto SGLang, lo que lo convierte en una herramienta valiosa para quienes trabajan en implementaciones de investigación y producción.
En el futuro, el equipo de PyTorch ha descrito varios desarrollos interesantes para torchao. Estos incluyen ampliar los límites de la cuantificación al ir por debajo de los 4 bits, desarrollar núcleos de alto rendimiento para inferencias de alto rendimiento, expandirse a más capas, tipos de escala o granularidades y admitir backends de hardware adicionales, como el hardware MX.
Conclusiones clave del lanzamiento de torchao
- Mejoras de rendimiento significativas: Se logró una aceleración de hasta el 97 % para la inferencia de Llama 3 8B utilizando técnicas de cuantificación avanzadas.
- Reducción del consumo de recursos: Se demostró una reducción máxima de VRAM del 73 % para la inferencia Llama 3.1 8B y una reducción del 50 % en VRAM para los modelos de difusión.
- Soporte de cuantificación versátil: Proporciona amplias opciones de cuantificación, incluidas float8 e int4, con soporte para QAT para recuperar la precisión.
- Optimizadores de bits bajos: Se introdujeron optimizadores de 8 y 4 bits como reemplazo directo de AdamW.
- Integración con importantes proyectos de código abierto: Integrado activamente en transformadores, difusores-torchao y otros proyectos clave de HuggingFace.
En conclusión, el lanzamiento de torchao representa un gran paso adelante para PyTorch, ya que proporciona a los desarrolladores un potente conjunto de herramientas para hacer modelos más rápidos y eficientes en escenarios de entrenamiento e inferencia.
Mira el Detalles y GitHub. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como empresario e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.