MassiveDS: un almacén de datos de 1,4 billones de tokens que permite que los modelos de lenguaje alcancen una eficiencia y precisión superiores en aplicaciones de PNL con uso intensivo de conocimiento

Los modelos de lenguaje se han convertido en la piedra angular de la PNL moderna, permitiendo avances significativos en diversas aplicaciones, incluida la generación de texto, la traducción automática y los sistemas de respuesta a preguntas. Investigaciones recientes se han centrado en escalar estos modelos en términos de la cantidad de datos de entrenamiento y la cantidad de parámetros. Estas leyes de escalamiento han demostrado que aumentar los datos y los parámetros del modelo produce mejoras sustanciales en el rendimiento. Sin embargo, ahora se está explorando una nueva dimensión de escala: el tamaño de los almacenes de datos externos disponibles en el momento de la inferencia. A diferencia de los modelos paramétricos tradicionales, que dependen únicamente de los datos de entrenamiento, los modelos de lenguaje basados en la recuperación pueden acceder dinámicamente a una base de conocimientos mucho más grande durante la inferencia, mejorando su capacidad para generar respuestas más precisas y contextualmente relevantes. Este novedoso enfoque de integrar vastos almacenes de datos abre nuevas posibilidades para gestionar eficientemente el conocimiento y mejorar la precisión fáctica de los LM.
Uno de los principales desafíos de la PNL es retener y utilizar un vasto conocimiento sin incurrir en costos computacionales significativos. Los modelos de lenguaje tradicional generalmente se entrenan en grandes conjuntos de datos estáticos codificados en los parámetros del modelo. Una vez entrenados, estos modelos no pueden integrar nueva información dinámicamente y requieren un costoso reentrenamiento para actualizar su base de conocimientos. Esto es particularmente problemático para tareas intensivas en conocimiento, donde los modelos necesitan hacer referencia a extensas fuentes externas. El problema se agrava cuando se requiere que estos modelos manejen diversos dominios, como datos web generales, artículos científicos y códigos técnicos. La incapacidad de adaptarse dinámicamente a nueva información y la carga computacional asociada con el reentrenamiento limitan la efectividad de estos modelos. Por lo tanto, se necesita un nuevo paradigma para permitir que los modelos de lenguaje accedan y utilicen dinámicamente el conocimiento externo.
Los enfoques existentes para mejorar las capacidades de los modelos de lenguaje incluyen el uso de mecanismos basados en recuperación que dependen de almacenes de datos externos. Estos modelos, conocidos como modelos de lenguaje basados en recuperación (RIC-LM), pueden acceder a contexto adicional durante la inferencia consultando un almacén de datos externo. Esta estrategia contrasta con los modelos paramétricos, limitados por el conocimiento incorporado dentro de sus parámetros. Los esfuerzos notables incluyen el uso de almacenes de datos del tamaño de Wikipedia con unos pocos miles de millones de tokens. Sin embargo, estos almacenes de datos suelen ser específicos de un dominio y no cubren toda la información necesaria para tareas posteriores complejas. Además, los modelos anteriores basados en la recuperación tienen limitaciones de eficiencia y viabilidad computacional, ya que los almacenes de datos a gran escala presentan desafíos para mantener la velocidad y la precisión de la recuperación. Aunque algunos modelos como RETRO han utilizado almacenes de datos propietarios, sus resultados no han sido completamente replicables debido a la naturaleza cerrada de los conjuntos de datos.
Un equipo de investigación de la Universidad de Washington y el Instituto Allen de IA construyó un nuevo almacén de datos llamado MasivoDSque comprende 1,4 billones de tokens. Este almacén de datos de código abierto es el más grande y diverso disponible para LM basados en recuperación. Incluye datos de ocho dominios: libros, artículos científicos, artículos de Wikipedia, repositorios de GitHub y textos matemáticos. MassiveDS fue diseñado específicamente para facilitar la recuperación a gran escala durante la inferencia, permitiendo que los modelos de lenguaje accedan y utilicen más información que nunca. Los investigadores implementaron una canalización eficiente que reduce la sobrecarga computacional asociada con el escalado del almacén de datos. Este canal permite la evaluación sistemática de las tendencias de escalamiento de los almacenes de datos mediante la recuperación de un subconjunto de documentos y la aplicación de operaciones como indexación, filtrado y submuestreo solo a estos subconjuntos, lo que hace que la construcción y utilización de grandes almacenes de datos sean computacionalmente accesibles.
La investigación demostró que MassiveDS mejora significativamente el rendimiento de los modelos de lenguaje basados en recuperación. Por ejemplo, un LM más pequeño que utiliza este almacén de datos superó a un LM paramétrico más grande en múltiples tareas posteriores. Específicamente, los modelos MassiveDS lograron puntuaciones de perplejidad más bajas en datos científicos y web generales, lo que indica una mayor calidad del modelado del lenguaje. Además, en tareas de respuesta a preguntas intensivas en conocimiento, como TriviaQA y Preguntas Naturales, los LM que utilizaron MassiveDS superaron consistentemente a sus homólogos más grandes. En TriviaQA, los modelos con acceso a menos de 100 mil millones de tokens de MassiveDS podrían superar el rendimiento de modelos de lenguaje mucho más grandes que no utilizaban almacenes de datos externos. Estos hallazgos sugieren que aumentar el tamaño del almacén de datos permite que los modelos funcionen mejor sin mejorar sus parámetros internos, lo que reduce el costo general de capacitación.
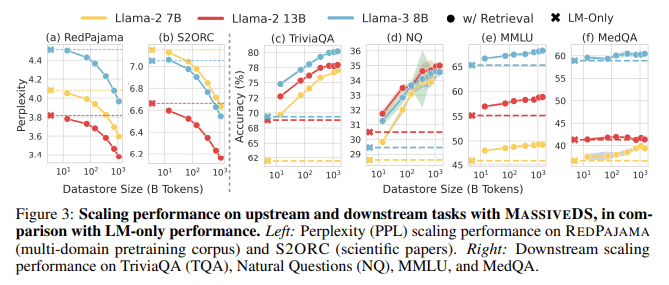
Los investigadores atribuyen estas mejoras de rendimiento a la capacidad de MassiveDS para proporcionar información de alta calidad y específica del dominio durante la inferencia. Incluso para tareas con mucho razonamiento, como MMLU y MedQA, los LM basados en recuperación que utilizan MassiveDS mostraron mejoras notables en comparación con los modelos paramétricos. El uso de múltiples fuentes de datos garantiza que el almacén de datos pueda proporcionar un contexto relevante para diversas consultas, lo que hace que los modelos de lenguaje sean más versátiles y efectivos en diferentes dominios. Los resultados resaltan la importancia de utilizar filtros de calidad de datos y métodos de recuperación optimizados, lo que mejora aún más los beneficios del escalamiento del almacén de datos.

En conclusión, este estudio demuestra que los modelos de lenguaje basados en recuperación equipados con un gran almacén de datos como MassiveDS pueden funcionar mejor a un costo computacional menor que los modelos paramétricos tradicionales. Al aprovechar un amplio almacén de datos de 1,4 billones de tokens, estos modelos pueden acceder dinámicamente a información diversa y de alta calidad, mejorando significativamente su capacidad para manejar tareas intensivas en conocimiento. Esto representa una dirección prometedora para futuras investigaciones, ya que ofrece un método escalable y eficiente para mejorar el rendimiento de los modelos de lenguaje sin aumentar el tamaño del modelo ni el costo de capacitación.
Mira el Papel, Conjunto de datos, GitHuby Proyecto. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como emprendedor e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.