Revisando la caída de peso: más allá de la regularización en el aprendizaje profundo moderno

La disminución del peso y la regularización ℓ2 son cruciales en el aprendizaje automático, especialmente para limitar la capacidad de la red y reducir los componentes de peso irrelevantes. Estas técnicas se alinean con los principios de la navaja de Occam y son fundamentales para las discusiones sobre los límites de la generalización. Sin embargo, estudios recientes han cuestionado la correlación entre medidas basadas en normas y la generalización en redes profundas. Aunque la caída de peso se utiliza ampliamente en redes profundas de última generación como GPT-3, CLIP y PALM, su efecto aún no se comprende completamente. La aparición de nuevas arquitecturas como los transformadores y el modelado de lenguajes de casi una época ha complicado aún más la aplicabilidad de los resultados clásicos a los entornos modernos de aprendizaje profundo.
Los esfuerzos para comprender y utilizar la pérdida de peso han progresado significativamente con el tiempo. Estudios recientes han destacado los distintos efectos de la disminución de peso y la regularización ℓ2, especialmente para optimizadores como Adam. También destaca la influencia de la disminución del peso en la dinámica de optimización, incluido su impacto en las tasas de aprendizaje efectivas en redes invariantes de escala. Otros métodos incluyen su función en la regularización de la entrada jacobiana y la creación de efectos de amortiguación específicos en ciertos optimizadores. Además, una investigación reciente contiene la relación entre la disminución de peso, la duración del entrenamiento y el rendimiento de generalización. Si bien se ha demostrado que la disminución del peso mejora la precisión de las pruebas, las mejoras suelen ser modestas, lo que sugiere que la regularización implícita desempeña un papel importante en el aprendizaje profundo.
Investigadores del Laboratorio de Teoría del Aprendizaje Automático de la EPFL han propuesto una nueva perspectiva sobre el papel de la disminución del peso en el aprendizaje profundo moderno. Su trabajo desafía la visión tradicional de la disminución del peso como principalmente una técnica de regularización, tal como se estudia en la teoría clásica del aprendizaje. Han demostrado que la caída del peso modifica significativamente la dinámica de optimización en redes sobreparametrizadas y subparametrizadas. Además, la disminución del peso previene la pérdida repentina de divergencias en el entrenamiento de precisión mixta bfloat16, un aspecto crucial del entrenamiento LLM. Se aplica en varias arquitecturas, desde ResNets hasta LLM, lo que indica que la principal ventaja de la disminución del peso radica en su capacidad para influir en la dinámica del entrenamiento en lugar de actuar como un regularizador explícito.
Los experimentos se llevan a cabo entrenando modelos GPT-2 en OpenWebText utilizando el repositorio NanoGPT. Se utiliza un modelo de parámetros de 124M (GPT-2-Small) entrenado para 50.000 iteraciones, con modificaciones para garantizar la practicidad dentro de las limitaciones académicas. Se encuentra que las pérdidas de entrenamiento y validación permanecen estrechamente alineadas entre diferentes valores de disminución de peso. Los investigadores proponen dos mecanismos principales para la pérdida de peso en los LLM:
- Optimización mejorada, como se observa en estudios anteriores.
- Prevención de divergencias de pérdidas al utilizar la precisión bfloat16.
Estos hallazgos contrastan con entornos con datos limitados donde la generalización es el enfoque clave, destacando la importancia de la velocidad de optimización y la estabilidad del entrenamiento en la formación LLM.
Los resultados experimentales revelan un efecto crucial de la disminución del peso al permitir un entrenamiento estable de precisión mixta bfloat16 para los LLM. El entrenamiento de Bfloat16 acelera el proceso y reduce el uso de memoria de la GPU, lo que permite entrenar modelos más grandes y tamaños de lotes más grandes. Sin embargo, incluso el bfloat16 más estable puede presentar picos de entrenamiento tardío que perjudican el rendimiento del modelo. También se ha comprobado que la pérdida de peso previene estas divergencias. Si bien se sabe que el entrenamiento float16 encuentra problemas con valores moderadamente grandes que exceden 65,519, plantea un desafío diferente y su precisión limitada puede generar problemas al agregar componentes de red con diferentes escalas. La pérdida de peso resuelve eficazmente estos problemas relacionados con la precisión al prevenir el crecimiento excesivo de peso.
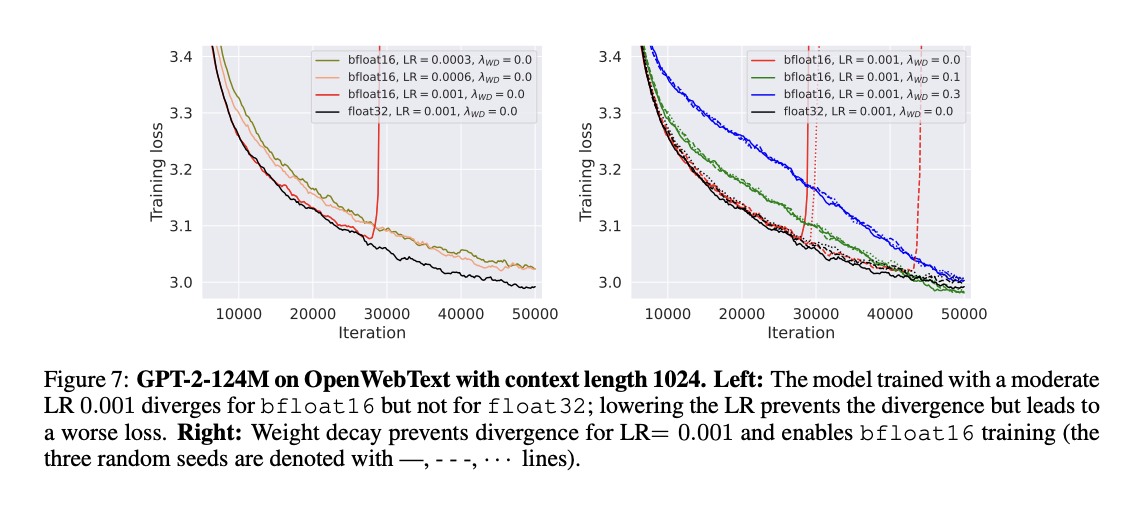
En este artículo, los investigadores presentaron una nueva perspectiva sobre el papel de la disminución del peso en el aprendizaje profundo moderno. Concluyeron que la pérdida de peso muestra tres efectos distintos en el aprendizaje profundo:
- Proporcionar regularización cuando se combina con ruido estocástico.
- Mejora de la optimización de la pérdida de entrenamiento
- Garantizar la estabilidad en el entrenamiento de baja precisión.
Los investigadores están desafiando la idea tradicional de que la pérdida de peso actúa principalmente como un regularizador explícito. En cambio, argumentan que su uso generalizado en el aprendizaje profundo moderno se debe a su capacidad para crear cambios beneficiosos en la dinámica de optimización. Este punto de vista ofrece una explicación unificada para el éxito de la disminución del peso en diferentes arquitecturas y entornos de entrenamiento, que van desde tareas de visión con ResNets hasta LLM. Los enfoques futuros incluyen el entrenamiento de modelos y el ajuste de hiperparámetros en el campo del aprendizaje profundo.
Mira el Papel y GitHub. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!

Sajjad Ansari es un estudiante de último año de IIT Kharagpur. Como entusiasta de la tecnología, profundiza en las aplicaciones prácticas de la IA centrándose en comprender el impacto de las tecnologías de IA y sus implicaciones en el mundo real. Su objetivo es articular conceptos complejos de IA de una manera clara y accesible.