Salesforce AI presenta SFR-Judge: una familia de tres modelos Judge de 8 mil millones de parámetros, tamaño 8B, 12B y 70B, construidos con Meta Llama 3 y Mistral NeMO

El avance de los modelos de lenguaje grande (LLM) en el procesamiento del lenguaje natural ha mejorado significativamente varios dominios. A medida que se desarrollan modelos más complejos, evaluar con precisión sus resultados se vuelve esencial. Tradicionalmente, las evaluaciones humanas han sido el enfoque estándar para evaluar la calidad, pero este proceso requiere mucho tiempo y debe ser más escalable para el rápido ritmo de desarrollo del modelo.
La investigación de IA de Salesforce presenta Juez SFRuna familia de tres modelos de jueces basados en LLM, para revolucionar la forma en que se evalúan los resultados de LLM. Construido con Meta Llama 3 y Mistral NeMO, SFR-Judge viene en tres tamaños: 8 mil millones (8B), 12 mil millones (12B) y 70 mil millones (70B) de parámetros. Cada modelo está diseñado para realizar múltiples tareas de evaluación, como comparaciones por pares, calificaciones individuales y clasificación binaria. Estos modelos se desarrollaron para ayudar a los equipos de investigación a evaluar rápida y eficazmente nuevos LLM.
Una de las principales limitaciones de utilizar LLM tradicionales como jueces es su susceptibilidad a sesgos e inconsistencias. Muchos modelos de jueces, por ejemplo, exhiben un sesgo de posición, donde su juicio está influenciado por el orden en que se presentan las respuestas. Otros pueden mostrar un sesgo de longitud, favoreciendo respuestas más largas que parecen más completas incluso cuando las más cortas son más precisas. Para abordar estos problemas, los modelos SFR-Judge se entrenan mediante la optimización de preferencias directas (DPO), lo que permite que el modelo aprenda de ejemplos positivos y negativos. Esta metodología de capacitación permite que el modelo desarrolle una comprensión matizada de las tareas de evaluación, reduciendo los sesgos y garantizando juicios consistentes.
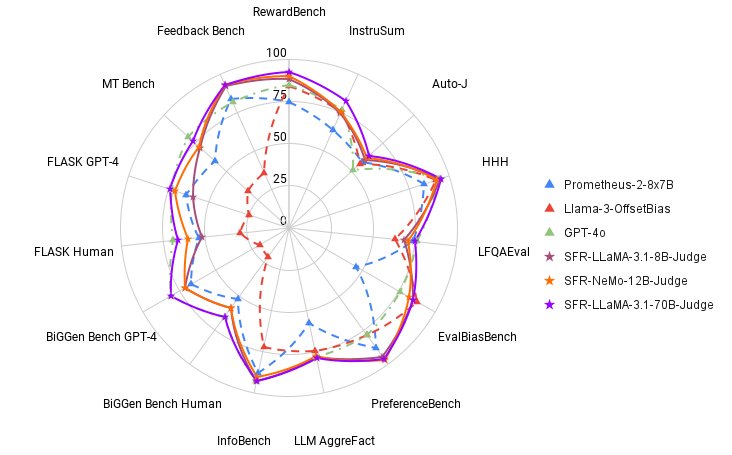
Los modelos SFR-Judge se probaron en 13 puntos de referencia en tres tareas de evaluación, demostrando un rendimiento superior a los modelos de jueces existentes, incluidos modelos propietarios como GPT-4o. En particular, SFR-Judge logró el mejor desempeño en 10 de los 13 puntos de referencia, estableciendo un nuevo estándar en la evaluación basada en LLM. Por ejemplo, en la tabla de clasificación de RewardBench, SFR-Judge logró una precisión del 92,7 %, marcando la primera y segunda vez que cualquier modelo de juez generativo cruzó el umbral del 90 %. Estos resultados resaltan la efectividad de SFR-Judge no solo como modelo de evaluación sino también como modelo de recompensa capaz de guiar modelos posteriores en el aprendizaje reforzado a partir de escenarios de retroalimentación humana (RLHF).
El enfoque de capacitación de SFR-Judge implica tres formatos de datos distintos. La primera, la Crítica de la Cadena de Pensamiento, ayuda al modelo a generar análisis estructurados y detallados de las respuestas evaluadas. Esta crítica mejora la capacidad del modelo para razonar sobre datos complejos y producir juicios informados. El segundo formato, Juicio Estándar, simplifica las evaluaciones al eliminar la crítica y proporciona retroalimentación más directa sobre si las respuestas cumplen con los criterios especificados. Finalmente, la deducción de respuestas permite al modelo deducir cómo se ve una reacción de alta calidad, reforzando sus capacidades de juicio. Estos tres formatos de datos funcionan en conjunto para fortalecer la capacidad del modelo para producir evaluaciones completas y precisas.
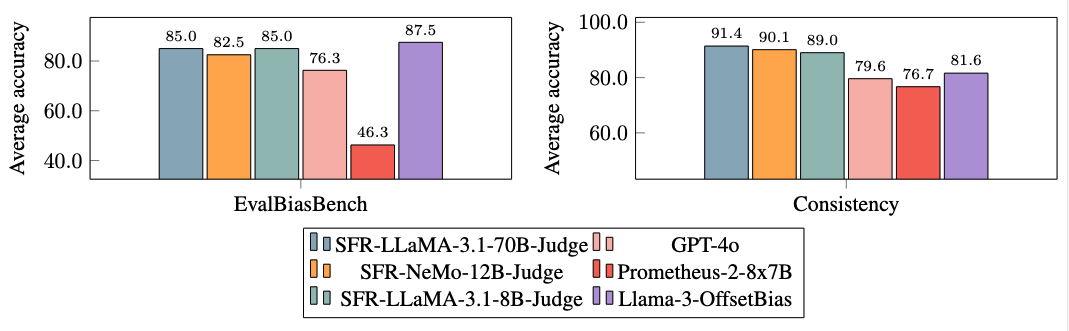
Amplios experimentos revelaron que los modelos SFR-Judge están significativamente menos sesgados que los modelos de la competencia, como lo demuestra su desempeño en EvalBiasBench, un punto de referencia diseñado para probar seis tipos de sesgo. Los modelos exhiben altos niveles de coherencia en el orden de pares en múltiples puntos de referencia, lo que indica que sus juicios permanecen estables incluso cuando se altera el orden de las respuestas. Esta solidez posiciona a SFR-Judge como una solución confiable para automatizar la evaluación de LLM, reducir la dependencia de anotadores humanos y proporcionar una alternativa escalable para la evaluación de modelos.
Conclusiones clave de la investigación:
- Alta precisión: SFR-Judge logró puntuaciones máximas en 10 de 13 puntos de referencia, incluida una precisión del 92,7 % en RewardBench, superando a muchos modelos de jueces de última generación.
- Mitigación de sesgos: Los modelos demostraron niveles más bajos de sesgo, incluido el sesgo de longitud y posición, en comparación con otros modelos de jueces, como lo confirma su desempeño en EvalBiasBench.
- Aplicaciones versátiles: SFR-Judge admite tres tareas de evaluación principales: comparaciones por pares, calificaciones individuales y clasificación binaria, lo que lo hace adaptable a varios escenarios de evaluación.
- Explicaciones estructuradas: A diferencia de muchos modelos de jueces, SFR-Judge está capacitado para producir explicaciones detalladas de sus juicios, lo que reduce la naturaleza de caja negra de las evaluaciones basadas en LLM.
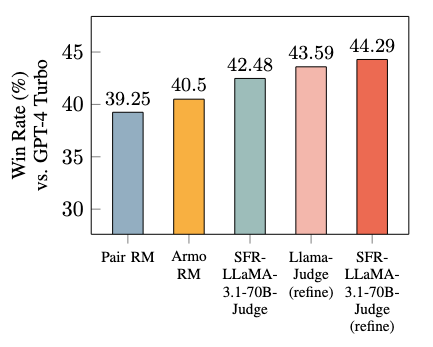
- Aumento del rendimiento en modelos posteriores: Las explicaciones del modelo pueden mejorar los resultados de los modelos posteriores, convirtiéndolo en una herramienta eficaz para escenarios RLHF.
En conclusión, la introducción de SFR-Judge por parte de Salesforce AI Research marca un importante avance en la evaluación automatizada de grandes modelos de lenguaje. Aprovechando la optimización de preferencias directas y un conjunto diverso de datos de entrenamiento, el equipo de investigación ha creado una familia de modelos de evaluación que son a la vez sólidos y confiables. Estos modelos pueden aprender de diversos ejemplos, proporcionar comentarios detallados y reducir los sesgos comunes, lo que los convierte en herramientas invaluables para evaluar y perfeccionar el contenido generativo. SFR-Judge establece un nuevo punto de referencia en la evaluación basada en LLM y abre la puerta a mayores avances en la evaluación de modelos automatizados.
Mira el Papel y Detalles. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como emprendedor e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.