FusionANNS: una solución ANNS de próxima generación que combina procesamiento cooperativo CPU/GPU para mejorar el rendimiento, la escalabilidad y la rentabilidad

La búsqueda aproximada del vecino más cercano (ANNS) es una tecnología crítica que impulsa varias aplicaciones impulsadas por IA, como minería de datos, motores de búsqueda y sistemas de recomendación. El objetivo principal de ANNS es identificar los vectores más cercanos a una consulta determinada en espacios de alta dimensión. Este proceso es esencial en contextos donde encontrar rápidamente elementos similares es crucial, como el reconocimiento de imágenes, el procesamiento del lenguaje natural y los motores de recomendación a gran escala. Sin embargo, a medida que el tamaño de los datos aumenta a miles de millones de vectores, los sistemas ANNS enfrentan desafíos considerables en términos de rendimiento y escalabilidad. La gestión eficiente de estos conjuntos de datos requiere importantes recursos computacionales y de memoria, lo que la convierte en una tarea muy compleja y costosa.
El principal problema que aborda esta investigación es que las soluciones ANNS existentes a menudo necesitan ayuda para manejar la inmensa escala de los conjuntos de datos modernos manteniendo al mismo tiempo la eficiencia y la precisión. Los enfoques tradicionales son inadecuados para datos de miles de millones de escala porque exigen un alto uso de memoria y potencia computacional. Se han desarrollado técnicas como el archivo invertido (IVF) y los métodos de indexación basados en gráficos para abordar estas limitaciones. Aún así, a menudo requieren memoria a escala de terabytes, lo que los hace costosos y consumen muchos recursos. Además, la complejidad computacional de realizar cálculos masivos de distancias entre vectores de alta dimensión en conjuntos de datos tan grandes es un cuello de botella para los sistemas ANNS actuales.
En el estado actual de la tecnología ANNS, con frecuencia se emplean métodos que requieren mucha memoria, como la FIV y los índices basados en gráficos, para estructurar el espacio de búsqueda. Si bien estos métodos pueden mejorar el rendimiento de las consultas, también aumentan significativamente el consumo de memoria, particularmente para grandes conjuntos de datos que contienen miles de millones de vectores. Las técnicas de indexación jerárquica (HI) y cuantificación de productos (PQ) han optimizado el uso de la memoria al almacenar índices en SSD y utilizar representaciones comprimidas de vectores. Sin embargo, estas soluciones pueden provocar una grave degradación del rendimiento debido a la sobrecarga introducida por las operaciones de compresión y descompresión de datos, lo que puede provocar pérdidas de precisión. Los sistemas actuales como SPANN y RUMMY han demostrado diversos grados de éxito, pero siguen estando limitados por su incapacidad para equilibrar el consumo de memoria y la eficiencia computacional.
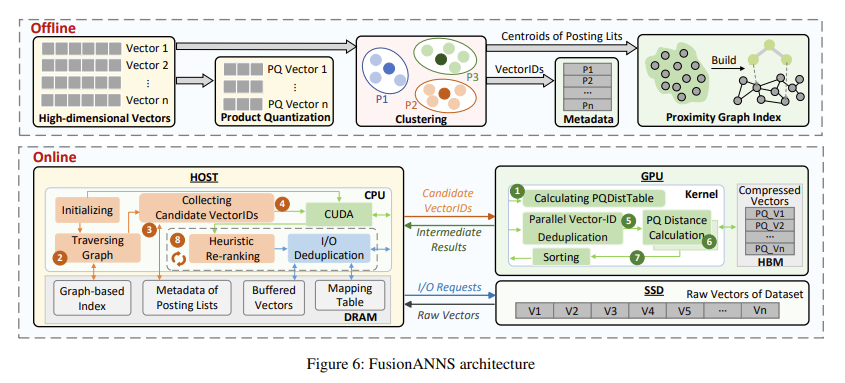
Investigadores de la Universidad de Ciencia y Tecnología de Huazhong y Huawei Technologies Co., Ltd presentaron FusiónANNSuna nueva arquitectura de procesamiento colaborativo CPU/GPU diseñada específicamente para conjuntos de datos de miles de millones de escala para abordar estos desafíos. FusionANNS utiliza una innovadora estructura de índice de varios niveles que aprovecha las fortalezas de las CPU y las GPU. Esta arquitectura permite búsquedas aproximadas de vecinos más cercanos de alto rendimiento y baja latencia utilizando una única GPU de nivel básico, lo que la convierte en una solución rentable. El enfoque de los investigadores se centra en tres innovaciones principales: indexación de varios niveles, reclasificación heurística y deduplicación de E/S con reconocimiento de redundancia, que minimizan la transmisión de datos entre CPU, GPU y SSD para eliminar los cuellos de botella en el rendimiento.
La estructura de indexación de múltiples niveles de FusionANNS permite el filtrado colaborativo de CPU/GPU al almacenar vectores sin procesar en SSD, vectores comprimidos en la memoria de alto ancho de banda (HBM) de la GPU e identificadores de vectores en la memoria del host. Esta estructura evita el intercambio excesivo de datos entre CPU y GPU, lo que reduce significativamente las operaciones de E/S. La reclasificación heurística mejora aún más la precisión de las consultas al dividir el proceso de reclasificación en múltiples minilotes y emplear un mecanismo de control de retroalimentación para finalizar los cálculos innecesarios antes de tiempo. El componente final, la deduplicación de E/S consciente de la redundancia, agrupa vectores con alta similitud en diseños de almacenamiento optimizados, lo que reduce la cantidad de solicitudes de E/S durante la reclasificación en un 30 % y elimina operaciones de E/S redundantes a través de estrategias efectivas de almacenamiento en caché.
Los resultados experimentales indican que FusionANNS supera a los sistemas de última generación como SPANN y RUMMY en varias métricas. El sistema logra hasta 13,1 veces más consultas por segundo (QPS) y 8,8 veces más rentabilidad en comparación con SPANN, y entre 2 y 4,9 veces más QPS y 6,8 veces mejor rentabilidad en comparación con RUMMY. Para un conjunto de datos que contiene mil millones de vectores, FusionANNS puede manejar el proceso de consulta con un QPS de más de 12.000 manteniendo una latencia tan baja como 15 milisegundos. Estos resultados demuestran que FusionANNS es muy eficaz para gestionar conjuntos de datos de miles de millones de escala sin grandes recursos de memoria.
Las conclusiones clave de esta investigación incluyen:
- Mejora del rendimiento: FusionANNS logra un QPS hasta 13,1 veces mayor y una rentabilidad 8,8 veces mejor que el sistema SPANN de última generación basado en SSD.
- Ganancia de eficiencia: Proporciona una eficiencia entre 5,7 y 8,8 veces mayor en el manejo del acceso y procesamiento de datos basados en SSD.
- Escalabilidad: FusionANNS puede gestionar conjuntos de datos a miles de millones de escala utilizando solo una GPU de nivel básico y recursos de memoria mínimos.
- Rentabilidad: El sistema muestra una mejora de 2 a 4,9 veces en la rentabilidad en comparación con las soluciones en memoria existentes como RUMMY.
- Reducción de latencia: FusionANNS mantiene una latencia de consulta de 15 milisegundos, significativamente menor que otras soluciones basadas en SSD y aceleradas por GPU.
- Innovación en Diseño: El uso de indexación de varios niveles, reclasificación heurística y deduplicación de E/S con reconocimiento de redundancia son contribuciones innovadoras que distinguen a FusionANNS de los métodos existentes.

En conclusión, FusionANNS representa un gran avance en la tecnología ANNS al ofrecer un alto rendimiento, baja latencia y una rentabilidad superior. El novedoso enfoque de los investigadores para la colaboración CPU/GPU y la indexación de múltiples niveles ofrece una solución práctica para escalar ANNS para admitir grandes conjuntos de datos. FusionANNS establece un nuevo estándar para el manejo de datos de alta dimensión en aplicaciones del mundo real al reducir la huella de memoria y eliminar cálculos innecesarios.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como emprendedor e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.