Leyes de escala y comparación de modelos: nuevas fronteras en el aprendizaje automático a gran escala

Los modelos de lenguajes grandes (LLM) han ganado una atención significativa en el aprendizaje automático, cambiando el enfoque de optimizar la generalización en pequeños conjuntos de datos a reducir el error de aproximación en corpus de texto masivos. Este cambio de paradigma presenta a los investigadores nuevos desafíos en el desarrollo de modelos y metodologías de capacitación. El objetivo principal ha evolucionado desde prevenir el sobreajuste mediante técnicas de regularización hasta ampliar eficazmente los modelos para consumir grandes cantidades de datos. Los investigadores ahora enfrentan el desafío de equilibrar las limitaciones computacionales con la necesidad de mejorar el rendimiento en las tareas posteriores. Este cambio requiere una reevaluación de los enfoques tradicionales y el desarrollo de estrategias sólidas para aprovechar el poder del entrenamiento previo del lenguaje a gran escala y al mismo tiempo abordar las limitaciones impuestas por los recursos informáticos disponibles.
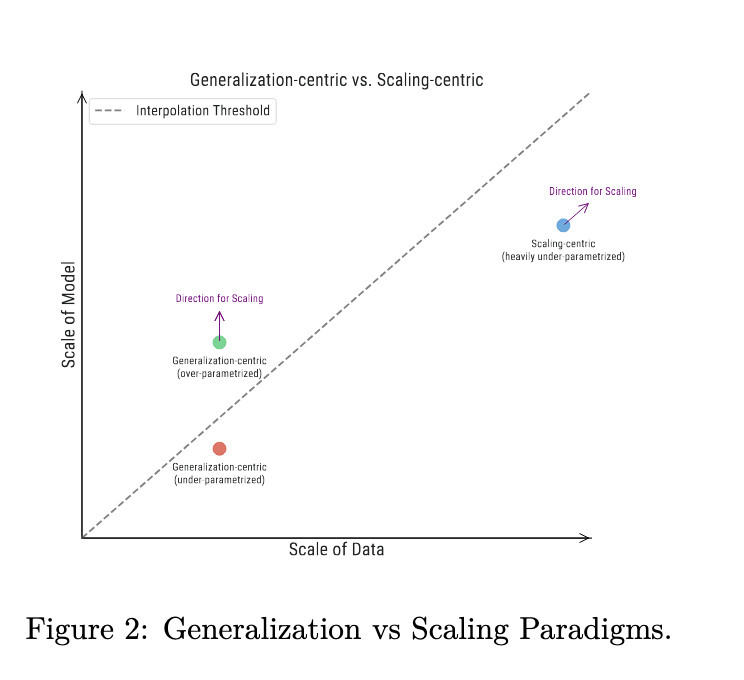
El cambio de un paradigma centrado en la generalización a un paradigma centrado en la escala en el aprendizaje automático ha hecho necesario reevaluar los enfoques tradicionales. Los investigadores de Google DeepMind han identificado diferencias clave entre estos paradigmas, centrándose en minimizar el error de aproximación mediante el escalado en lugar de reducir el error de generalización mediante la regularización. Este cambio desafía la sabiduría convencional, ya que las prácticas que eran efectivas en el paradigma centrado en la generalización pueden no producir resultados óptimos en el enfoque centrado en la escala. El fenómeno del “cruce de leyes de escala” complica aún más las cosas, ya que las técnicas que mejoran el desempeño en escalas más pequeñas pueden no traducirse de manera efectiva en escalas más grandes. Para mitigar estos desafíos, los investigadores proponen desarrollar nuevos principios y metodologías para guiar los esfuerzos de ampliación y comparar de manera efectiva modelos a escalas sin precedentes donde la realización de múltiples experimentos a menudo es inviable.
El aprendizaje automático tiene como objetivo desarrollar funciones capaces de realizar predicciones precisas sobre datos invisibles mediante la comprensión de la estructura subyacente de los datos. Este proceso implica minimizar la pérdida de pruebas en datos invisibles mientras se aprende de un conjunto de entrenamiento. El error de prueba se puede descomponer en la brecha de generalización y el error de aproximación (error de entrenamiento).
Han surgido dos paradigmas distintos en el aprendizaje automático, diferenciados por las escalas relativa y absoluta de datos y modelos:
1. El paradigma centrado en la generalización, que opera con escalas de datos relativamente pequeñas, se divide a su vez en dos subparadigmas:
a) El clásico régimen de compensación sesgo-varianza, donde la capacidad del modelo se restringe intencionalmente.
b) El régimen moderno sobreparametrizado, donde la escala del modelo supera significativamente la escala de los datos.
2. El paradigma centrado en la escala, caracterizado por grandes datos y escalas de modelos, donde la escala de datos excede la escala del modelo.
Estos paradigmas presentan diferentes desafíos y requieren enfoques distintos para optimizar el rendimiento del modelo y lograr los resultados deseados.
El método propuesto emplea una arquitectura de transformador solo decodificador entrenada en el conjunto de datos C4, utilizando la base de código NanoDO. Las características arquitectónicas clave incluyen incrustación posicional rotativa, norma QK para cálculo de atención y pesos de incrustación y cabeza desatados. El modelo utiliza activación Gelu con F = 4D, donde D es la dimensión del modelo y F es la dimensión oculta del MLP. Los cabezales de atención están configurados con una dimensión de cabezal de 64 y la longitud de la secuencia está establecida en 512.
El tamaño del vocabulario del modelo es 32,101 y el recuento total de parámetros es de aproximadamente 12D²L, donde L es el número de capas del transformador. La mayoría de los modelos están entrenados para lograr el óptimo de Chinchilla, utilizando tokens de 20 × (12D²L + DV). Los requisitos informáticos se estiman mediante la fórmula F = 6ND, donde F representa el número de operaciones de punto flotante.
Para la optimización, el método emplea AdamW con β1 = 0,9, β2 = 0,95, ϵ = 1e-20 y una caída de peso acoplada λ = 0,1. Esta combinación de opciones arquitectónicas y estrategias de optimización tiene como objetivo mejorar el rendimiento del modelo en el paradigma centrado en el escalado.
En el paradigma centrado en el escalamiento, las técnicas de regularización tradicionales están siendo reevaluadas por su efectividad. Tres métodos de regularización populares comúnmente utilizados en el paradigma centrado en la generalización son la regularización explícita de L2 y los efectos de regularización implícitos de grandes tasas de aprendizaje y tamaños de lotes pequeños. Estas técnicas han sido fundamentales para mitigar el sobreajuste y reducir la brecha entre las pérdidas de entrenamiento y prueba en modelos de menor escala.
Sin embargo, en el contexto de grandes modelos de lenguaje y el paradigma centrado en la escala, se cuestiona la necesidad de estas técnicas de regularización. A medida que los modelos operan en un régimen en el que el sobreajuste es menos preocupante debido a la gran cantidad de datos de capacitación, es posible que los beneficios tradicionales de la regularización ya no se apliquen. Este cambio lleva a los investigadores a reconsiderar el papel de la regularización en el entrenamiento de modelos y a explorar enfoques alternativos que pueden ser más adecuados para el paradigma centrado en la escala.
El paradigma centrado en la escala presenta desafíos únicos en la comparación de modelos a medida que los enfoques tradicionales de conjuntos de validación se vuelven poco prácticos a escalas masivas. El fenómeno del cruce de leyes de escala complica aún más las cosas, ya que las clasificaciones de desempeño observadas en escalas más pequeñas pueden no ser válidas para modelos más grandes. Esto plantea la cuestión crítica de cómo comparar modelos de manera efectiva cuando la capacitación sólo es factible una vez a escala.
Por el contrario, el paradigma centrado en la generalización se basa en gran medida en la regularización como principio rector. Este enfoque ha dado lugar a conocimientos sobre la elección de hiperparámetros, los efectos de la disminución del peso y los beneficios de la sobreparametrización. También explica la efectividad de técnicas como el peso compartido en las CNN, la localidad y la jerarquía en las arquitecturas de redes neuronales.
Sin embargo, el paradigma centrado en la escala puede requerir nuevos principios rectores. Si bien la regularización ha sido crucial para comprender y mejorar la generalización en modelos más pequeños, se están reevaluando su papel y eficacia en modelos lingüísticos a gran escala. Los investigadores ahora enfrentan el desafío de desarrollar metodologías y principios sólidos que puedan guiar el desarrollo y la comparación de modelos en este nuevo paradigma, donde los enfoques tradicionales pueden ya no aplicarse.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de 52k+ ML.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Asjad es consultor interno en Marktechpost. Está cursando B.Tech en ingeniería mecánica en el Instituto Indio de Tecnología, Kharagpur. Asjad es un entusiasta del aprendizaje automático y el aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en la atención médica.