VectorSearch: una solución integral para los desafíos de recuperación de documentos con indexación híbrida, búsqueda multivectorial y rendimiento de consultas optimizado

El campo de la recuperación de información ha evolucionado rápidamente debido al crecimiento exponencial de los datos digitales. Con el creciente volumen de datos no estructurados, los métodos eficientes para buscar y recuperar información relevante se han vuelto más cruciales que nunca. Las técnicas de búsqueda tradicionales basadas en palabras clave a menudo necesitan capturar el significado matizado del texto, lo que genera resultados de búsqueda inexactos o irrelevantes. Este problema se vuelve más pronunciado con conjuntos de datos complejos que abarcan varios tipos de medios, como texto, imágenes y vídeos. La adopción generalizada de dispositivos inteligentes y plataformas sociales ha contribuido aún más a este aumento de datos, y las estimaciones sugieren que los datos no estructurados podrían constituir el 80% del volumen total de datos para 2025. Como tal, existe una necesidad crítica de metodologías sólidas que puedan transformar estos datos en conocimientos significativos.
Uno de los principales desafíos en la recuperación de información es lidiar con la alta dimensionalidad y la naturaleza dinámica de los conjuntos de datos modernos. Las técnicas existentes a menudo necesitan ayuda para proporcionar soluciones escalables y eficientes para manejar consultas multivectoriales o integrar actualizaciones en tiempo real. Esto es particularmente problemático para aplicaciones que requieren una recuperación rápida de resultados contextualmente relevantes, como sistemas de recomendación y motores de búsqueda a gran escala. Si bien se han logrado algunos avances en la mejora de los mecanismos de recuperación mediante el análisis semántico latente (LSA) y modelos de aprendizaje profundo, estos métodos aún deben abordar las brechas semánticas entre consultas y documentos.
Los sistemas actuales de recuperación de información, como Milvus, han intentado ofrecer soporte para la gestión de datos vectoriales a gran escala. Sin embargo, estos sistemas se ven obstaculizados por su dependencia de conjuntos de datos estáticos y la falta de flexibilidad para manejar consultas complejas de múltiples vectores. Los algoritmos y bibliotecas tradicionales a menudo dependen en gran medida del almacenamiento de la memoria principal y no pueden distribuir datos entre varias máquinas, lo que limita su escalabilidad. Esto restringe su adaptabilidad a escenarios del mundo real donde los datos cambian constantemente. Como resultado, las soluciones existentes luchan por proporcionar la precisión y eficiencia necesarias para entornos dinámicos.
El equipo de investigación de la Universidad de Washington presentó Búsqueda vectorialun novedoso marco de recuperación de documentos diseñado para abordar estas limitaciones. VectorSearch integra modelos de lenguaje avanzados, técnicas de indexación híbrida y mecanismos de manejo de consultas de múltiples vectores para mejorar significativamente la precisión de la recuperación y la escalabilidad. Al aprovechar tanto las incrustaciones de vectores como los métodos de indexación tradicionales, VectorSearch puede administrar de manera eficiente conjuntos de datos a gran escala, lo que lo convierte en una herramienta poderosa para operaciones de búsqueda complejas. El marco incorpora mecanismos de caché y algoritmos de búsqueda optimizados, lo que mejora los tiempos de respuesta y el rendimiento general. Estas capacidades lo diferencian de los sistemas convencionales y ofrecen una solución integral para la recuperación de documentos.
VectorSearch opera como un sistema híbrido que combina las fortalezas de múltiples técnicas de indexación, como FAISS para indexación distribuida y HNSWlib para optimización de búsqueda jerárquica. Este enfoque permite la gestión fluida de conjuntos de datos a gran escala en múltiples máquinas. Además, introduce algoritmos novedosos para la búsqueda multivectorial, codificando documentos en incrustaciones de alta dimensión que capturan las relaciones semánticas entre diferentes datos. La integración de estas incrustaciones en una base de datos vectorial permite que el sistema recupere documentos relevantes en función de las consultas de los usuarios de manera eficiente. Los experimentos con conjuntos de datos del mundo real demuestran que VectorSearch supera a los sistemas existentes, con una tasa de recuperación del 76,62 % y una tasa de precisión del 98,68 % en una dimensión de índice de 1024.
La evaluación del desempeño de VectorSearch reveló mejoras significativas en varias métricas. El sistema logró un tiempo de consulta promedio de 0,47 segundos cuando utilizó el modelo sin caja basado en BERT y la técnica de indexación FAISS, que es considerablemente más rápida que los sistemas de recuperación tradicionales. Esta reducción en el tiempo de consulta se atribuye al uso innovador de la indexación jerárquica y el manejo de consultas multivectoriales. Además, el marco propuesto admite actualizaciones en tiempo real, lo que le permite manejar conjuntos de datos que evolucionan dinámicamente sin una reindexación extensa. Estas mejoras hacen de VectorSearch una solución versátil para aplicaciones que van desde motores de búsqueda web hasta sistemas de recomendación.
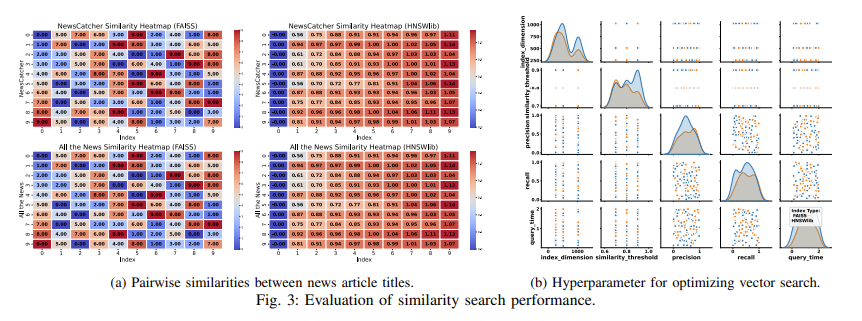
Las conclusiones clave de la investigación incluyen:
- Alta precisión y recuperación: VectorSearch logró una tasa de recuperación del 76,62 % y una tasa de precisión del 98,68 % cuando utilizó una dimensión de índice de 1024, superando a los modelos de referencia en varias tareas de recuperación.
- Tiempo de consulta reducido: El sistema redujo significativamente el tiempo de consulta, logrando un promedio de 0,47 segundos para la recuperación de datos de alta dimensión.
- Escalabilidad: Al integrar FAISS y HNSWlib, VectorSearch maneja de manera eficiente conjuntos de datos en evolución y a gran escala, lo que lo hace adecuado para aplicaciones en tiempo real.
- Soporte para datos dinámicos: El marco admite actualizaciones en tiempo real, lo que le permite mantener un alto rendimiento incluso cuando cambian los datos.

En conclusión, VectorSearch presenta una solución sólida a los desafíos que enfrentan los sistemas de recuperación de información existentes. Al introducir un enfoque escalable y adaptable, el equipo de investigación ha creado un marco que satisface las demandas de las aplicaciones modernas con uso intensivo de datos. La integración de técnicas de indexación híbrida, operaciones de búsqueda multivectorial y modelos de lenguaje avanzados da como resultado una mejora significativa en la precisión y eficiencia de la recuperación. Esta investigación allana el camino para futuros avances en el campo y ofrece información valiosa sobre el desarrollo de sistemas de recuperación de documentos de próxima generación.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como emprendedor e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.