Este artículo de IA de KAIST AI presenta un enfoque novedoso para mejorar la eficiencia de la inferencia de LLM en entornos multilingües
El procesamiento del lenguaje natural (PLN) ha experimentado un gran avance con la aparición de grandes modelos de lenguaje (LLM), que se utilizan en diversas aplicaciones, como la generación de texto, la traducción y los agentes conversacionales. Estos modelos pueden procesar y comprender lenguajes humanos a un nivel sin precedentes, lo que permite una comunicación perfecta entre máquinas y usuarios. Sin embargo, a pesar de su éxito, implementar estos modelos en múltiples idiomas plantea desafíos importantes debido a los recursos computacionales necesarios. La complejidad de los entornos multilingües, que implican diversas estructuras lingüísticas y diferencias de vocabulario, complica aún más la implementación eficiente de los LLM en aplicaciones prácticas del mundo real.
El alto tiempo de inferencia es un problema importante cuando se implementan LLM en contextos multilingües. El tiempo de inferencia se refiere a la duración requerida por un modelo para generar respuestas basadas en entradas dadas, y este tiempo aumenta dramáticamente en entornos multilingües. Un factor que contribuye a este problema es la discrepancia en la tokenización y el tamaño del vocabulario entre idiomas, lo que genera variaciones en la longitud de la codificación. Por ejemplo, los idiomas con estructuras gramaticales complejas o conjuntos de caracteres más grandes, como el japonés o el ruso, requieren muchos más tokens para codificar la misma cantidad de información que el inglés. Como resultado, los LLM tienden a exhibir tiempos de respuesta más lentos y costos computacionales más altos al procesar dichos idiomas, lo que dificulta mantener un rendimiento consistente en todos los pares de idiomas.
Los investigadores han explorado varios métodos para optimizar la eficiencia de la inferencia LLM para superar estos desafíos. Técnicas como la destilación de conocimientos y la compresión de modelos reducen el tamaño de los modelos grandes al entrenar modelos más pequeños para replicar sus resultados. Otra técnica prometedora es la decodificación especulativa, que aprovecha un modelo asistente, un “redactor”, para generar borradores iniciales de los resultados del LLM objetivo. Este modelo de redactor puede ser significativamente más pequeño que el LLM principal, lo que reduce el costo computacional. Sin embargo, los métodos de decodificación especulativa generalmente se diseñan con un enfoque monolingüe y no se generalizan de manera efectiva a escenarios multilingües, lo que resulta en un rendimiento subóptimo cuando se aplican a diversos idiomas.
Investigadores de KAIST AI y KT Corporation han introducido un enfoque innovador para la decodificación especulativa multilingüe, aprovechando una estrategia previa al entrenamiento y ajuste. El enfoque comienza con el entrenamiento previo de los modelos de redacción utilizando conjuntos de datos multilingües en una tarea de modelado de lenguaje general. Luego, los modelos se ajustan para cada idioma específico para alinearse mejor con las predicciones del LLM objetivo. Este proceso de dos pasos permite a los redactores especializarse en el manejo de las características únicas de cada idioma, lo que da como resultado borradores iniciales más precisos. Los investigadores validaron este enfoque experimentando con varios idiomas y evaluando el desempeño de los redactores en tareas de traducción que involucraban alemán, francés, japonés, chino y ruso.
La metodología introducida por el equipo de investigación implica un proceso de tres etapas conocido como paradigma borrador-verificar-aceptar. Durante la etapa inicial de “borrador”, el modelo del redactor genera posibles tokens futuros en función de la secuencia de entrada. La etapa de “verificación” compara estos tokens redactados con las predicciones realizadas por el LLM principal para garantizar la coherencia. Si el resultado del redactor se alinea con las predicciones del LLM, se aceptan los tokens; de lo contrario, se descartan o se corrigen y se repite el ciclo. Este proceso reduce efectivamente la carga computacional del LLM principal al filtrar temprano los tokens incorrectos, lo que le permite centrarse solo en verificar y refinar los borradores proporcionados por el modelo asistente.
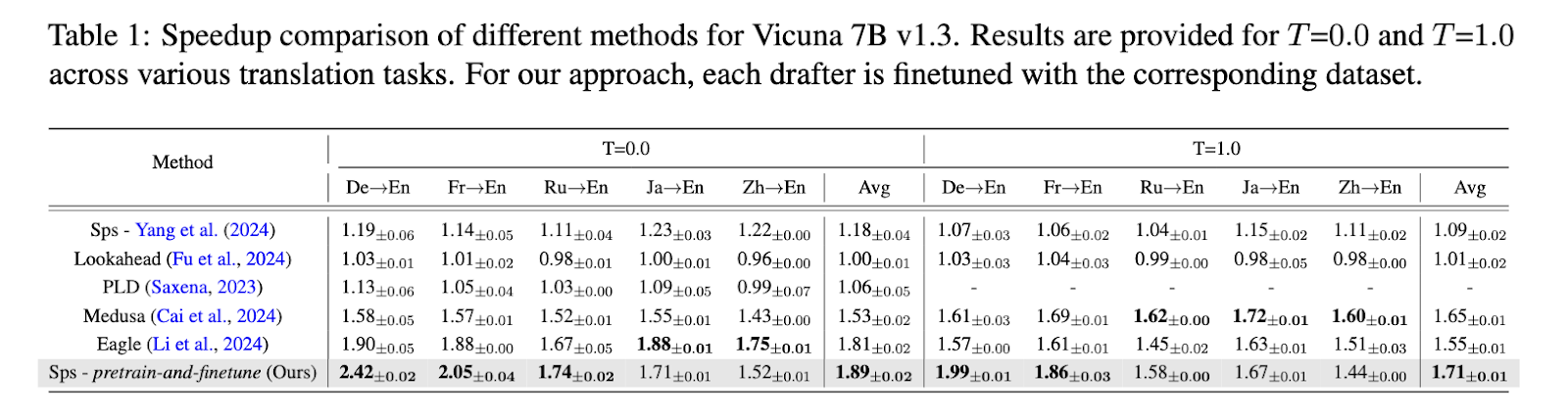
El rendimiento de este enfoque se probó exhaustivamente y se produjeron resultados impresionantes. El equipo de investigación observó una reducción significativa en el tiempo de inferencia, logrando una tasa de aceleración promedio de 1,89 veces en comparación con los métodos de decodificación autorregresivos estándar. En tareas específicas de traducción multilingüe, el método propuesto registró una tasa de aceleración de hasta 2,42 veces cuando se aplicó a pares de idiomas como alemán-inglés y francés-inglés. Estos resultados se obtuvieron utilizando el modelo Vicuña 7B como LLM principal, siendo los modelos de redacción significativamente más pequeños. Por ejemplo, el modelo del redactor alemán comprendía sólo 68 millones de parámetros, pero aceleró con éxito el proceso de traducción sin comprometer la precisión. Con respecto a las puntuaciones de juicio de GPT-4o, los investigadores informaron que los modelos de redacción especializados superaron consistentemente a las técnicas de decodificación especulativa existentes en múltiples conjuntos de datos de traducción.
Otros desgloses del rendimiento de aceleración revelaron que los modelos de redactores especializados lograron una relación de aceleración de 1,19 en entornos deterministas (T=0) y una relación de 1,71 en entornos de muestreo más diversos (T=1), lo que demuestra su solidez en diferentes escenarios. Además, los resultados indicaron que la estrategia propuesta de entrenamiento previo y ajuste mejora significativamente la capacidad del redactor para predecir tokens futuros con precisión, especialmente en contextos multilingües. Este hallazgo es crucial para las aplicaciones que priorizan mantener la coherencia del rendimiento en todos los idiomas, como las plataformas globales de atención al cliente y los sistemas de IA conversacionales multilingües.
La investigación presenta una estrategia novedosa para mejorar la eficiencia de la inferencia LLM en aplicaciones multilingües a través de modelos de redacción especializados. Los investigadores mejoraron con éxito la alineación entre el redactor y el LLM primario empleando un proceso de capacitación de dos pasos, logrando reducciones sustanciales en el tiempo de inferencia. Estos resultados sugieren que la capacitación previa y el ajuste específico de los redactores pueden ser más efectivos que simplemente aumentar el tamaño del modelo, estableciendo así un nuevo punto de referencia para la implementación práctica de LLM en diversos entornos lingüísticos.
Mira el Papel y GitHub. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de 52k+ ML.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.