RanDumb: un enfoque de IA simple pero potente para el aprendizaje continuo sin ejemplos

El aprendizaje continuo es un área de investigación en rápida evolución que se centra en el desarrollo de modelos capaces de aprender a partir de flujos de datos que llegan secuencialmente, similar al aprendizaje humano. Aborda los desafíos de adaptarse a nueva información manteniendo al mismo tiempo los conocimientos adquiridos previamente. Este campo es particularmente relevante en escenarios donde los modelos deben funcionar bien en múltiples tareas durante períodos prolongados, como aplicaciones del mundo real con datos no estacionarios y recursos computacionales limitados. A diferencia del aprendizaje automático tradicional, donde los modelos se entrenan en conjuntos de datos estáticos, el aprendizaje continuo requiere que los modelos se adapten dinámicamente a nuevos datos mientras administran la memoria y la eficiencia computacional.
Un problema importante en el aprendizaje continuo es el problema del “olvido catastrófico”, donde las redes neuronales pierden la capacidad de recordar tareas aprendidas previamente cuando se exponen a otras nuevas. Este fenómeno es especialmente problemático cuando los modelos necesitan ayuda para almacenar o revisar datos antiguos, lo que dificulta equilibrar la estabilidad del aprendizaje y la adaptabilidad del modelo. La incapacidad de integrar eficazmente nueva información sin sacrificar el rendimiento del conocimiento previo sigue siendo un obstáculo importante. Los investigadores han estado intentando diseñar soluciones que aborden esta limitación. Sin embargo, muchos métodos existentes no logran los resultados deseados en escenarios sin ejemplos donde no se pueden almacenar muestras de datos anteriores para referencia futura.
Los métodos existentes para abordar el olvido catastrófico generalmente implican el entrenamiento conjunto de representaciones junto con clasificadores o el uso de técnicas de regularización y repetición de experiencias. Sin embargo, estos enfoques suponen que las representaciones derivadas de redes neuronales aprendidas continuamente superarán naturalmente las funciones aleatorias predefinidas, como se observa en las configuraciones estándar de aprendizaje profundo. La cuestión central es que estos métodos no se evalúan bajo las limitaciones del aprendizaje continuo. Por ejemplo, los modelos a menudo no pueden actualizarse lo suficiente en escenarios de aprendizaje continuo en línea antes de que se descarten los datos. Esto da como resultado representaciones subóptimas y una precisión de clasificación reducida cuando se trata de nuevos flujos de datos.
Investigadores de la Universidad de Oxford, IIIT Hyderabad y Apple han desarrollado un enfoque novedoso llamado RanDumb. El método utiliza una combinación de características aleatorias de Fourier y un clasificador lineal para crear representaciones efectivas para la clasificación sin la necesidad de almacenar ejemplos o realizar actualizaciones frecuentes. El mecanismo de RanDumb es sencillo: proyecta píxeles de entrada sin procesar en un espacio de características de alta dimensión utilizando una transformada aleatoria de Fourier, que se aproxima al kernel de función de base radial (RBF). A esta proyección aleatoria fija le sigue un clasificador lineal simple que clasifica las características transformadas en función de sus medias de clase más cercanas. Este método supera a muchas técnicas existentes al eliminar la necesidad de realizar ajustes o actualizaciones complejas de la red neuronal, lo que lo hace muy adecuado para el aprendizaje continuo sin ejemplos.
RanDumb opera incrustando los datos de entrada en un espacio de alta dimensión, descorrelacionando las características utilizando la distancia de Mahalanobis y la similitud del coseno para una clasificación precisa. A diferencia de los métodos tradicionales que actualizan las representaciones junto con los clasificadores, RanDumb utiliza una transformación aleatoria fija para la incrustación. Solo requiere actualizaciones en línea de la matriz de covarianza y las medias de clase, lo que le permite manejar nuevos datos a medida que llegan de manera eficiente. El enfoque también evita la necesidad de buffers de memoria, lo que lo convierte en una solución ideal para entornos de bajos recursos. Además, el método conserva la simplicidad computacional al operar con una muestra a la vez, lo que garantiza la escalabilidad incluso con grandes conjuntos de datos.
Las evaluaciones experimentales demuestran que RanDumb se desempeña bien de manera constante en múltiples puntos de referencia de aprendizaje continuo. Por ejemplo, en el conjunto de datos MNIST, RanDumb logró una precisión del 98,3 %, superando los métodos existentes por márgenes de entre el 5 % y el 15 %. En los puntos de referencia CIFAR-10 y CIFAR-100, RanDumb registró precisiones del 55,6% y 28,6%, respectivamente, superando a los métodos de última generación que se basan en el almacenamiento de muestras anteriores. Los resultados resaltan la solidez del método para manejar escenarios de aprendizaje continuo en línea y fuera de línea sin almacenar ejemplos ni emplear estrategias de capacitación complejas. En particular, RanDumb igualó o superó el desempeño de la capacitación conjunta en muchos puntos de referencia, cerrando entre el 70% y el 90% de la brecha de desempeño entre el aprendizaje continuo restringido y el aprendizaje conjunto sin restricciones.
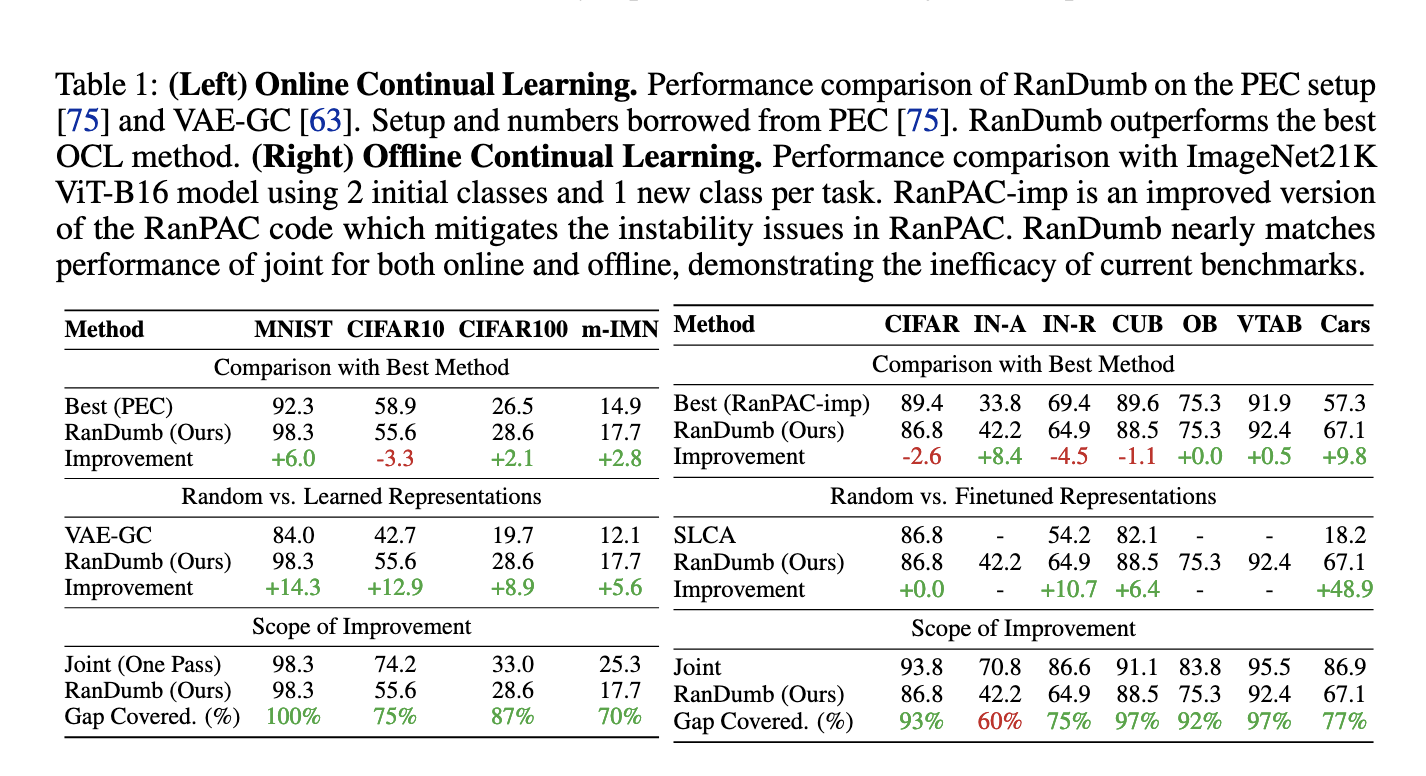
Además, la eficiencia de RanDumb se extiende a escenarios que incorporan extractores de funciones previamente entrenados. Cuando se aplicó a conjuntos de datos complejos como TinyImageNet, el método propuesto logró un rendimiento casi de última generación utilizando un clasificador lineal simple además de proyecciones aleatorias. El enfoque logró cerrar la brecha de rendimiento con los clasificadores conjuntos hasta en un 90%, superando significativamente a la mayoría de las estrategias de ajuste fino y rápido continuo. Además, el método muestra una marcada ganancia de rendimiento en escenarios poco ejemplares donde el almacenamiento de datos está restringido o no está disponible. Por ejemplo, RanDumb superó a los métodos líderes anteriores en un 4 % en el conjunto de datos CIFAR-100 en aprendizaje continuo fuera de línea.
En conclusión, el enfoque RanDumb redefine los supuestos que rodean el aprendizaje de representación eficaz en el aprendizaje continuo. Su metodología aleatoria basada en características demuestra ser una solución más simple pero más poderosa para el aprendizaje de representación, desafiando la dependencia convencional de actualizaciones complejas de redes neuronales. La investigación aborda las limitaciones de los métodos actuales de aprendizaje continuo y abre nuevas vías para desarrollar soluciones eficientes y escalables en entornos libres de ejemplos y con recursos limitados. Al aprovechar el poder de las incorporaciones aleatorias, RanDumb allana el camino para futuros avances en el aprendizaje continuo, especialmente en escenarios de aprendizaje en línea donde los datos y los recursos computacionales son limitados.
Mira el Papel y GitHub. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de 52k+ ML.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.