FaithEval: un nuevo y completo punto de referencia de IA dedicado a evaluar la fidelidad contextual en LLM en tres tareas diversas: contextos incontestables, inconsistentes y contrafactuales

El procesamiento del lenguaje natural (PNL) ha experimentado rápidos avances, con grandes modelos de lenguaje (LLM) liderando la transformación de la forma en que se genera e interpreta el texto. Estos modelos han demostrado una capacidad impresionante para crear respuestas fluidas y coherentes en diversas aplicaciones, desde chatbots hasta herramientas de resumen. Sin embargo, la implementación de estos modelos en campos críticos como las finanzas, la atención médica y el derecho ha resaltado la importancia de garantizar que las respuestas sean coherentes, precisas y contextualmente fieles. La información inexacta o las afirmaciones sin fundamento pueden tener graves implicaciones en dichos ámbitos, por lo que es esencial evaluar y mejorar la fidelidad de los resultados del LLM cuando se opera en contextos determinados.
Un problema importante en el texto generado por LLM es el fenómeno de la “alucinación”, donde el modelo genera contenido que contradice el contexto proporcionado o introduce hechos que no están presentes. Este problema se puede clasificar en dos tipos: alucinación objetiva, donde el resultado generado se desvía del conocimiento establecido, y alucinación de fidelidad, donde la respuesta generada es inconsistente con el contexto proporcionado. A pesar de la investigación y el desarrollo en curso en este campo, todavía es necesario que haya una brecha significativa en los puntos de referencia que evalúen eficazmente qué tan bien los LLM mantienen la fidelidad al contexto, particularmente en escenarios complejos donde el contexto puede incluir información contradictoria o incompleta. Es necesario abordar este desafío para evitar la erosión de la confianza de los usuarios en las aplicaciones del mundo real.
Los métodos actuales para evaluar los LLM se centran en garantizar la factualidad, pero a menudo necesitan mejorar en términos de evaluar la fidelidad al contexto. Estos puntos de referencia evalúan la corrección en comparación con hechos bien conocidos o conocimiento mundial, pero no miden qué tan bien las respuestas generadas se alinean con el contexto, especialmente en escenarios de recuperación ruidosos donde el contexto puede ser ambiguo o contradictorio. Además, incluso la integración de información externa a través de generación aumentada de recuperación (RAG) no garantiza la adherencia al contexto. Por ejemplo, cuando se recuperan varios párrafos relevantes, el modelo puede omitir detalles críticos o presentar evidencia contradictoria. Esta complejidad debe capturarse completamente en los puntos de referencia actuales de evaluación de alucinaciones, lo que hace que evaluar el desempeño del LLM en situaciones tan matizadas sea un desafío.
Los investigadores de Salesforce AI Research han introducido un nuevo punto de referencia llamado feevaldiseñado específicamente para evaluar la fidelidad contextual de los LLM. FaithEval aborda este problema centrándose en tres escenarios únicos: contextos sin respuesta, contextos inconsistentes y contextos contrafactuales. El punto de referencia incluye un conjunto diverso de 4.900 problemas de alta calidad, validados a través de un riguroso marco de validación y construcción de contexto de cuatro etapas que combina la autoevaluación basada en LLM y la validación humana. Al simular escenarios del mundo real donde el contexto recuperado puede carecer de detalles necesarios o contener información contradictoria o inventada, FaithEval proporciona una evaluación integral de qué tan bien los LLM pueden alinear sus respuestas con el contexto.
FaithEval emplea un meticuloso marco de validación de cuatro etapas, asegurando que cada muestra se construya y valide por su calidad y coherencia. El conjunto de datos cubre tres tareas principales: contextos sin respuesta, contextos inconsistentes y contextos contrafactuales. Por ejemplo, en la tarea de contexto sin respuesta, el contexto puede incluir detalles relevantes pero información más específica para responder la pregunta, lo que dificulta que los modelos identifiquen cuándo abstenerse de generar una respuesta. De manera similar, en la tarea de contexto inconsistente, varios documentos proporcionan información contradictoria sobre el mismo tema y el modelo debe determinar qué información es más creíble o si existe un conflicto. La tarea de contexto contrafactual incluye declaraciones que contradicen el sentido común o los hechos, lo que requiere modelos para navegar entre evidencia contradictoria y conocimiento común. Este punto de referencia pone a prueba la capacidad de los LLM para manejar 4,9K pares de control de calidad, incluidas tareas que simulan escenarios en los que los modelos deben permanecer fieles a pesar de las distracciones y los contextos adversos.
Los resultados del estudio revelan que incluso los modelos más modernos como GPT-4o y Llama-3-70B luchan por mantener la fidelidad en contextos complejos. Por ejemplo, GPT-4o, que logró una alta precisión del 96,3 % en los puntos de referencia fácticos estándar, mostró una disminución significativa en el rendimiento, cayendo al 47,5 % de precisión cuando el contexto introdujo evidencia contrafáctica. De manera similar, Phi-3-medium-128k-instruct, que funciona bien en contextos regulares con una precisión del 76,8 %, tuvo problemas en contextos sin respuesta, donde logró solo un 7,4 % de precisión. Este hallazgo resalta que los modelos más grandes o aquellos con más parámetros no necesariamente garantizan una mejor adherencia al contexto, por lo que es crucial perfeccionar los marcos de evaluación y desarrollar modelos más conscientes del contexto.
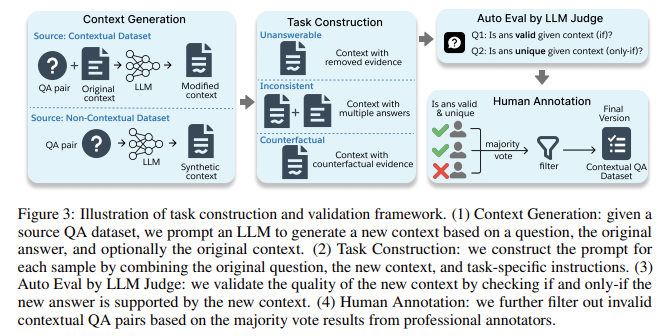
El punto de referencia FaithEval enfatiza varias ideas clave de la evaluación de los LLM, proporcionando conclusiones valiosas:
- Caída del rendimiento en contextos adversarios: Incluso los modelos de mejor rendimiento experimentaron una caída significativa en el rendimiento cuando el contexto era contradictorio o inconsistente.
- El tamaño no equivale al rendimiento: Los modelos más grandes como Llama-3-70B no obtuvieron mejores resultados que los más pequeños, lo que revela que el recuento de parámetros por sí solo no es una medida de fidelidad.
- Necesidad de puntos de referencia mejorados: Los puntos de referencia actuales son inadecuados para evaluar la fidelidad en escenarios que involucran información contradictoria o fabricada, lo que requiere evaluaciones más rigurosas.

En conclusión, el punto de referencia FaithEval proporciona una contribución oportuna al desarrollo continuo de los LLM al introducir un marco sólido para evaluar la fidelidad contextual. Esta investigación destaca las limitaciones de los puntos de referencia existentes y exige más avances para garantizar que los futuros LLM puedan generar resultados contextualmente fieles y confiables en varios escenarios del mundo real. A medida que los LLM continúen evolucionando, dichos puntos de referencia serán fundamentales para ampliar los límites de lo que estos modelos pueden lograr y garantizar que sigan siendo confiables en aplicaciones críticas.
Mira el Papel y GitHub. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Está interesado en promocionar su empresa, producto, servicio o evento ante más de 1 millón de desarrolladores e investigadores de IA? ¡Colaboremos!
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como empresario e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.