GemFilter: un nuevo enfoque de IA para acelerar la inferencia de LLM y reducir el consumo de memoria para entradas de contexto largas

Los modelos de lenguajes grandes (LLM) se han convertido en parte integral de numerosos sistemas de inteligencia artificial y muestran capacidades notables en diversas aplicaciones. Sin embargo, a medida que crece la demanda de procesar entradas de contexto prolongado, los investigadores enfrentan desafíos importantes para optimizar el rendimiento del LLM. La capacidad de manejar secuencias de entrada extensas es crucial para mejorar la funcionalidad de los agentes de IA y mejorar las técnicas de generación aumentada de recuperación. Si bien los avances recientes han ampliado la capacidad de los LLM para procesar entradas de hasta 1 millón de tokens, esto tiene un costo sustancial en recursos computacionales y tiempo. El principal desafío radica en acelerar la velocidad de generación de LLM y reducir el consumo de memoria de la GPU para entradas de contexto prolongado, lo cual es esencial para minimizar la latencia de respuesta y aumentar el rendimiento en las llamadas API de LLM. Aunque técnicas como la optimización de la caché KV han mejorado la fase de generación iterativa, la fase de cálculo rápido sigue siendo un cuello de botella importante, especialmente a medida que los contextos de entrada se alargan. Esto plantea la pregunta crítica: ¿Cómo pueden los investigadores acelerar la velocidad y reducir el uso de memoria durante la fase de cálculo rápido?
Los intentos anteriores de acelerar la velocidad de generación de LLM con entradas de contexto largas se han centrado principalmente en técnicas de desalojo y compresión de caché KV. Se han desarrollado métodos como el desalojo selectivo de contextos de largo alcance, la transmisión de LLM con receptores de atención y la indexación dispersa dinámica para optimizar la fase de generación iterativa. Estos enfoques tienen como objetivo reducir el consumo de memoria y el tiempo de ejecución asociado con la caché KV, especialmente para entradas largas.
Algunas técnicas, como QuickLLaMA y ThinkK, clasifican y podan la caché KV para preservar solo tokens o dimensiones esenciales. Otros, como H2O y SnapKV, se centran en retener tokens que contribuyen significativamente a la atención acumulativa o que son esenciales según las ventanas de observación. Si bien estos métodos se han mostrado prometedores a la hora de optimizar la fase de generación iterativa, no abordan el cuello de botella en la fase de cálculo rápido.
Un enfoque diferente implica comprimir secuencias de entrada eliminando la redundancia en el contexto. Sin embargo, este método requiere retener una parte sustancial de los tokens de entrada para mantener el rendimiento de LLM, lo que limita su eficacia para una compresión significativa. A pesar de estos avances, el desafío de reducir simultáneamente el tiempo de ejecución y el uso de memoria de la GPU durante las fases de cálculo rápido y generación iterativa sigue en gran medida sin abordarse.
Investigadores de la Universidad de Wisconsin-Madison, Salesforce AI Research y la Universidad de Hong Kong presentes Filtro de gemasuna visión única de cómo los LLM procesan la información. Este enfoque se basa en la observación de que los LLM a menudo identifican tokens relevantes en las primeras capas, incluso antes de generar una respuesta. GemFilter utiliza estas primeras capas, denominadas “capas de filtro”, para comprimir significativamente secuencias de entrada largas.
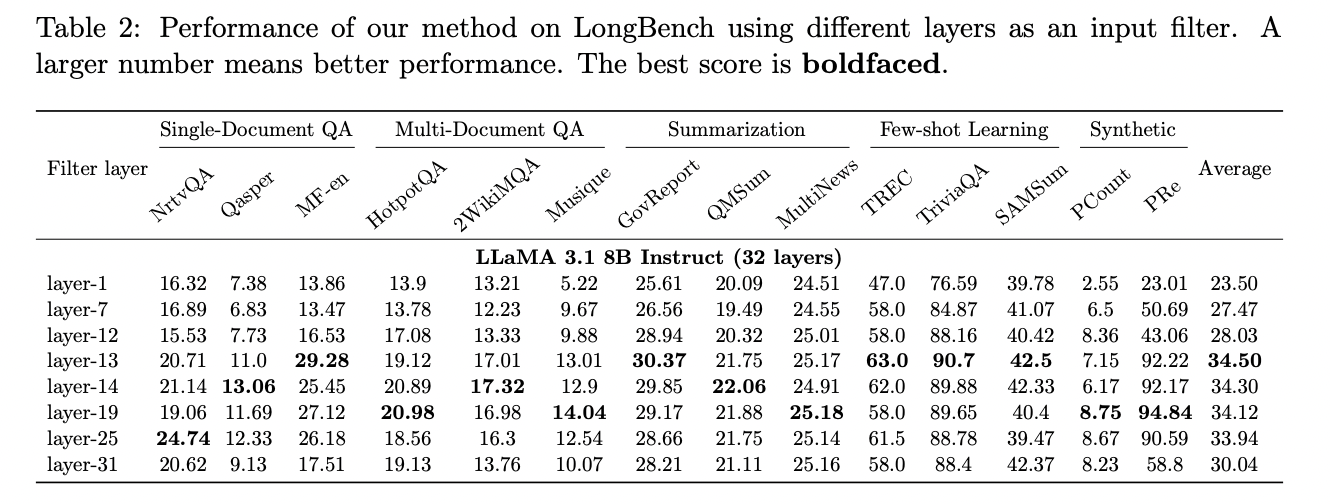
El método funciona analizando la matriz de atención de estas primeras capas para destilar la información necesaria para responder consultas. Por ejemplo, en el modelo LLaMA 3.1 8B, las capas 13 a 19 pueden resumir de manera efectiva la información requerida. Esto permite a GemFilter realizar cálculos rápidos en entradas de contexto largas solo para estas capas de filtro, comprimiendo los tokens de entrada desde hasta 128K a solo 100.
Al seleccionar un subconjunto de tokens en función de los patrones de atención en estas primeras capas, GemFilter logra reducciones sustanciales tanto en el tiempo de procesamiento como en el uso de memoria de la GPU. Luego, los tokens seleccionados se introducen en el modelo completo para su inferencia, seguido de funciones de generación estándar. Este enfoque aborda el cuello de botella en la fase de cálculo rápido y al mismo tiempo mantiene un rendimiento comparable a los métodos existentes en la fase de generación iterativa.
La arquitectura de GemFilter está diseñada para optimizar el rendimiento de LLM aprovechando el procesamiento de capas tempranas para una selección eficiente de tokens. El método utiliza las matrices de atención de las primeras capas, específicamente las “capas de filtro”, para identificar y comprimir tokens de entrada relevantes. Este proceso implica analizar los patrones de atención para seleccionar un pequeño subconjunto de tokens que contengan la información esencial necesaria para la tarea.
El núcleo de la arquitectura de GemFilter es su enfoque de dos pasos:
1. Selección de tokens: GemFilter utiliza la matriz de atención de una capa inicial (por ejemplo, la capa 13 en LLaMA 3.1 8B) para comprimir los tokens de entrada. Selecciona los k índices principales de la última fila de la matriz de atención, lo que reduce efectivamente el tamaño de entrada de 128.000 tokens potenciales a alrededor de 100 tokens.
2. Inferencia completa del modelo: los tokens seleccionados se procesan a través de todo el LLM para una inferencia completa, seguido de funciones de generación estándar.
Esta arquitectura permite a GemFilter lograr importantes aceleraciones y reducciones de memoria durante la fase de cálculo rápido mientras mantiene el rendimiento en la fase de generación iterativa. El método se formula en el Algoritmo 1, que describe los pasos específicos para la selección y el procesamiento de tokens. El diseño de GemFilter se destaca por su simplicidad, falta de requisitos de capacitación y amplia aplicabilidad en varias arquitecturas LLM, lo que la convierte en una solución versátil para mejorar la eficiencia de LLM.
La arquitectura de GemFilter se basa en un enfoque de dos pasos para optimizar el rendimiento de LLM. El algoritmo central, detallado en el Algoritmo 1, consta de los siguientes pasos clave:
1. Paso directo inicial: el algoritmo ejecuta solo las primeras r capas de la red de transformadores de m capas en la secuencia de entrada T. Este paso genera la consulta y las matrices clave (Q(r) y K(r)) para el r- octava capa, que sirve como capa filtrante.
2. Selección de tokens: utilizando la matriz de atención de la capa r, GemFilter selecciona los k tokens más relevantes. Esto se hace identificando los k valores más grandes de la última fila de la matriz de atención, que representan la interacción entre el último token de consulta y todos los tokens clave.
3. Manejo de la atención de múltiples cabezas: para la atención de múltiples cabezas, el proceso de selección considera la suma de la última fila en todas las matrices de cabezas de atención.
4. Reordenación de tokens: los tokens seleccionados se ordenan para mantener su orden de entrada original, asegurando una estructura de secuencia adecuada (por ejemplo, manteniendo el token
5. Generación final: el algoritmo ejecuta una función de generación y paso directo completo utilizando solo los k tokens seleccionados, lo que reduce significativamente la longitud del contexto de entrada (por ejemplo, de 128K a 1024 tokens).
Este enfoque permite a GemFilter procesar eficientemente entradas largas aprovechando la información de las primeras capas para la selección de tokens, reduciendo así el tiempo de cálculo y el uso de memoria tanto en la fase de cálculo rápido como en la de generación iterativa.

GemFilter demuestra un rendimiento impresionante en múltiples puntos de referencia, lo que demuestra su eficacia en el manejo de entradas de contexto prolongado para LLM.
En el punto de referencia Needle in a Haystack, que prueba la capacidad de los LLM para recuperar información específica de documentos extensos, GemFilter supera significativamente los métodos de atención estándar (All KV) y SnapKV. Este rendimiento superior se observa tanto en los modelos Mistral Nemo 12B Instruct como en LLaMA 3.1 8B Instruct, con longitudes de entrada de 60K y 120K tokens respectivamente.
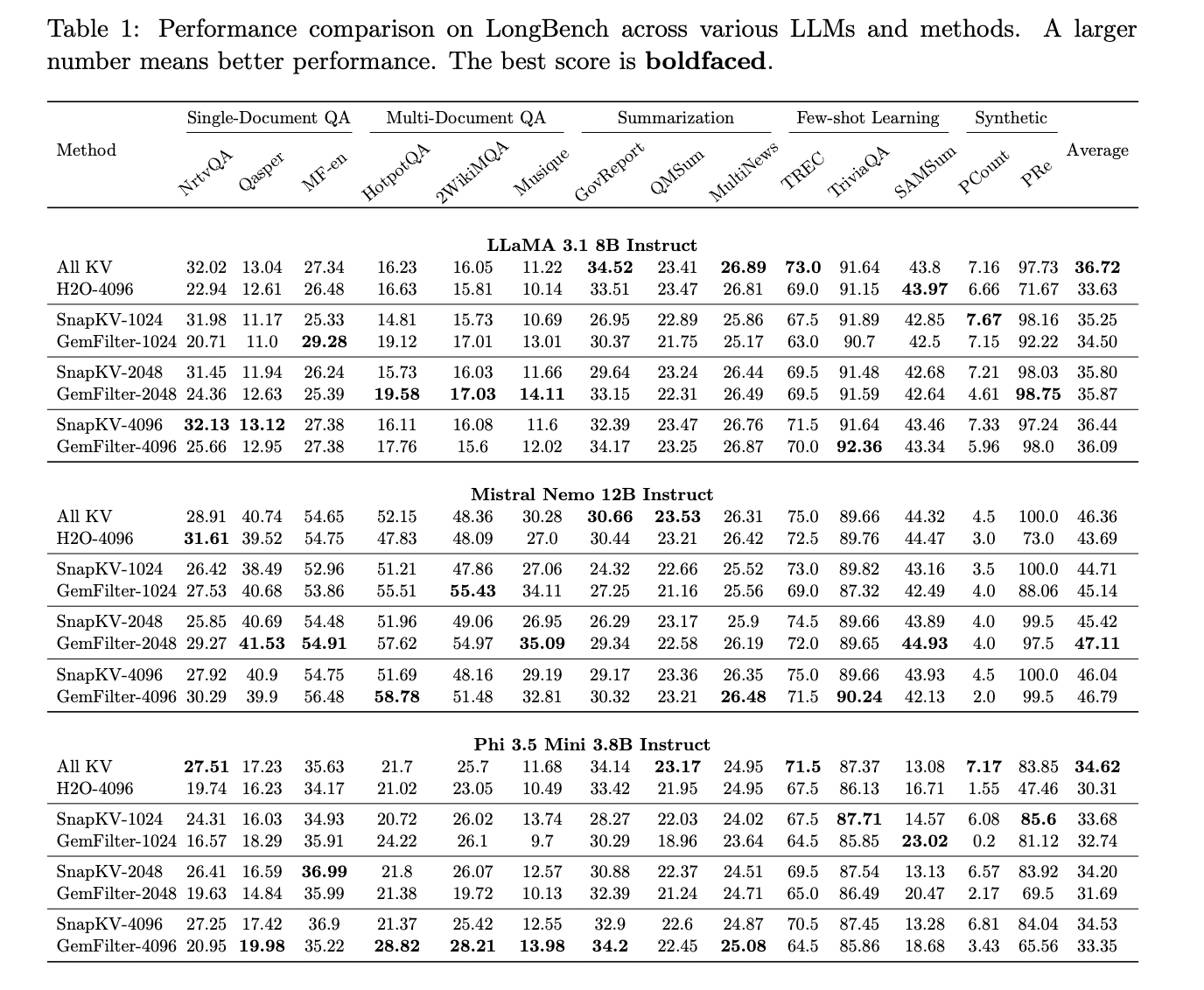
En el punto de referencia multitarea LongBench, que evalúa la comprensión de contexto prolongado en varias tareas, GemFilter muestra un rendimiento comparable o mejor que la atención estándar, incluso cuando se utilizan solo 1024 tokens seleccionados. Por ejemplo, GemFilter-2048 supera la atención estándar del modelo Mistral Nemo 12B Instruct. GemFilter también demuestra un rendimiento significativamente mejor que H2O y un rendimiento comparable al de SnapKV.
En particular, GemFilter logra estos resultados al tiempo que comprime eficazmente los contextos de entrada. Reduce los tokens de entrada a un promedio del 8% cuando se usan 1024 tokens y al 32% cuando se usan 4096 tokens, con caídas de precisión insignificantes. Esta capacidad de compresión, combinada con su capacidad para filtrar información clave y proporcionar resúmenes interpretables, hace de GemFilter una herramienta poderosa para optimizar el rendimiento de LLM en tareas de contexto prolongado.
GemFilter demuestra mejoras significativas en la eficiencia computacional y la utilización de recursos. En comparación con enfoques existentes como SnapKV y atención estándar, GemFilter logra una aceleración de 2,4 veces y reduce el uso de memoria de la GPU en un 30% y un 70%, respectivamente. Esta ganancia de eficiencia surge del exclusivo enfoque de procesamiento de tres etapas de GemFilter, donde el contexto de entrada largo se maneja solo durante la etapa inicial. Las etapas posteriores operan con insumos comprimidos, lo que genera ahorros sustanciales de recursos. Los experimentos con los modelos Mistral Nemo 12B Instruct y Phi 3.5 Mini 3.8B Instruct confirman aún más el rendimiento superior de GemFilter en términos de tiempo de ejecución y consumo de memoria de GPU en comparación con los métodos de última generación.
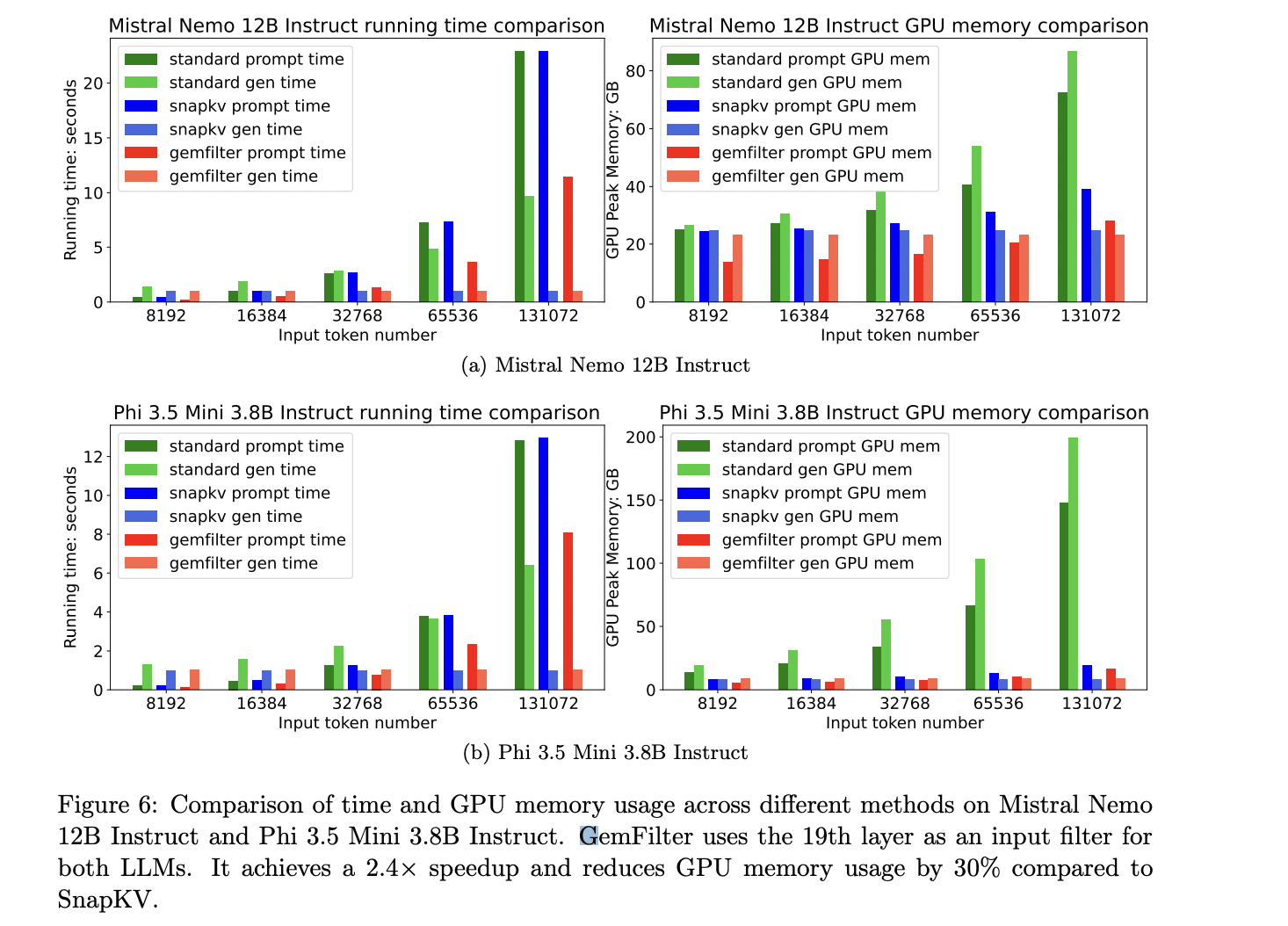
Este estudio presenta Filtro de gemasun enfoque sólido para mejorar la inferencia LLM para entradas de contexto largas, abordando desafíos críticos en velocidad y eficiencia de la memoria. Al aprovechar las capacidades de las primeras capas de LLM para identificar información relevante, GemFilter logra mejoras notables con respecto a las técnicas existentes. La aceleración de 2,4 veces del método y la reducción del 30 % en el uso de memoria de la GPU, junto con su rendimiento superior en Needle en un punto de referencia de Haystack, subrayan su eficacia. La simplicidad de GemFilter, su naturaleza sin capacitación y su amplia aplicabilidad a varios LLM lo convierten en una solución versátil. Además, su interpretabilidad mejorada a través de la inspección directa de tokens ofrece información valiosa sobre los mecanismos internos de LLM, lo que contribuye tanto a avances prácticos en la implementación de LLM como a una comprensión más profunda de estos modelos complejos.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Está interesado en promocionar su empresa, producto, servicio o evento ante más de 1 millón de desarrolladores e investigadores de IA? ¡Colaboremos!
Asjad es consultor interno en Marktechpost. Está cursando B.Tech en ingeniería mecánica en el Instituto Indio de Tecnología, Kharagpur. Asjad es un entusiasta del aprendizaje automático y el aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en la atención médica.