LASER: un método adaptativo para seleccionar modelos de recompensa RM y entrenar iterativamente LLM utilizando múltiples modelos de recompensa RM

Uno de los principales desafíos a la hora de alinear los grandes modelos de lenguaje (LLM) con las preferencias humanas es la dificultad de seleccionar el modelo de recompensa (RM) adecuado para guiar su formación. Un solo RM puede sobresalir en tareas como la escritura creativa, pero fracasar en áreas más orientadas a la lógica, como el razonamiento matemático. Esta falta de generalización conduce a un rendimiento subóptimo y a problemas como la piratería de recompensas. Al mismo tiempo, el uso simultáneo de varios RM es costoso desde el punto de vista computacional e introduce señales contradictorias. Superar estos desafíos es crucial para desarrollar sistemas de IA más adaptables y precisos capaces de manejar diversas aplicaciones del mundo real.
Los enfoques actuales se basan en un único RM o combinan varios RM en un conjunto. Los RM únicos tienen dificultades para generalizar entre tareas, lo que genera un rendimiento deficiente, especialmente cuando se enfrentan a problemas complejos y multidominio. Los métodos de conjunto mitigan esto, pero conllevan altos costos computacionales y enfrentan dificultades para manejar señales ruidosas o conflictivas de los RM. Estas limitaciones ralentizan el entrenamiento de modelos y degradan el rendimiento general, creando ineficiencias que dificultan las aplicaciones generalizadas en tiempo real.
Los investigadores de la UNC Chapel Hill proponen LASER (Aprender a seleccionar recompensas de forma adaptativa), que enmarca la selección de RM como un problema de bandidos con múltiples brazos. En lugar de cargar y ejecutar varios RM simultáneamente, LASER selecciona dinámicamente el RM más adecuado para cada tarea o instancia durante el entrenamiento. El método utiliza el algoritmo bandido LinUCB, que adapta la selección de RM en función del contexto de la tarea y el desempeño anterior. Al optimizar la selección de RM a nivel de instancia, LASER reduce la sobrecarga computacional al tiempo que mejora la eficiencia y precisión del entrenamiento LLM en un conjunto diverso de tareas, evitando los problemas de piratería de recompensas que se observan en los métodos de RM únicos.
LASER opera iterando tareas, generando múltiples respuestas del LLM y calificándolas con el RM más apropiado seleccionado por el MAB. Utilizando el algoritmo LinUCB, el MAB equilibra la exploración (probar nuevos RM) y la explotación (utilizar RM de alto rendimiento). El método se probó en varios puntos de referencia, como StrategyQA, GSM8K y el conjunto de datos WildChat, y abarca tareas de razonamiento, matemáticas y de seguimiento de instrucciones. LASER adapta continuamente su proceso de selección de RM, lo que mejora la eficiencia y precisión del entrenamiento en estos dominios. La selección dinámica también permite un mejor manejo de RM ruidosos o conflictivos, lo que resulta en un rendimiento más sólido.
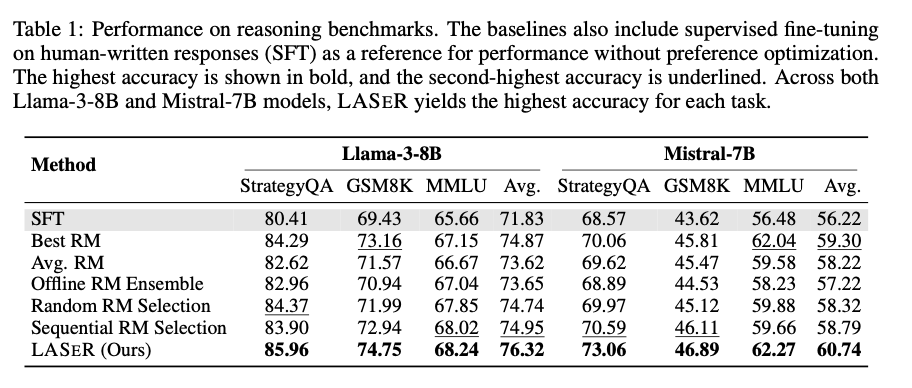
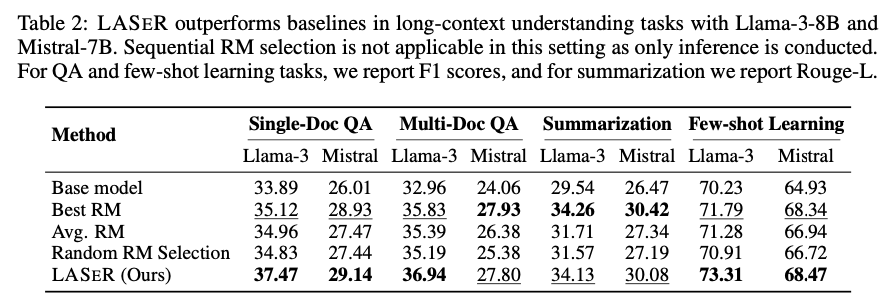
Los investigadores demostraron que LASER mejoró constantemente el rendimiento del LLM en varios puntos de referencia. Para tareas de razonamiento como StrategyQA y GSM8K, LASER mejoró la precisión promedio en un 2,67 % en comparación con los métodos de conjunto. En las tareas de seguimiento de instrucciones, LASER logró una tasa de éxito del 71,45 %, superando la selección secuencial de RM. En tareas de comprensión de contexto prolongado, LASER logró mejoras sustanciales, aumentando las puntuaciones F1 en 2,64 y 2,42 puntos en tareas de control de calidad de un solo documento y de varios documentos, respectivamente. En general, la selección de RM adaptativa de LASER condujo a una capacitación más eficiente, una complejidad computacional reducida y una generalización mejorada en una amplia gama de tareas.
En conclusión, LASER representa un avance significativo en la selección de modelos de recompensa para la formación LLM. Al seleccionar dinámicamente el RM más apropiado para cada instancia, LASER mejora tanto la eficiencia del entrenamiento como el desempeño de las tareas en diversos puntos de referencia. Este método aborda las limitaciones de los enfoques de RM únicos y conjuntos, ofreciendo una solución sólida para optimizar la alineación de LLM con las preferencias humanas. Con su capacidad para generalizar tareas y manejar recompensas ruidosas, LASER está preparado para tener un impacto duradero en el futuro desarrollo de la IA.
Mira el Papel y GitHub. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Está interesado en promocionar su empresa, producto, servicio o evento ante más de 1 millón de desarrolladores e investigadores de IA? ¡Colaboremos!
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasiona la ciencia de datos y el aprendizaje automático, y aporta una sólida formación académica y experiencia práctica en la resolución de desafíos interdisciplinarios de la vida real.