GSM composicional: un nuevo punto de referencia de IA para evaluar las capacidades de razonamiento de modelos de lenguaje grandes en problemas de varios pasos

El procesamiento del lenguaje natural (PNL) ha experimentado rápidos avances, y se utilizan grandes modelos de lenguaje (LLM) para abordar diversos problemas desafiantes. Entre las diversas aplicaciones de los LLM, la resolución de problemas matemáticos se ha convertido en un punto de referencia para evaluar sus capacidades de razonamiento. Estos modelos han demostrado un rendimiento notable en pruebas comparativas específicas de matemáticas como GSM8K, que mide sus capacidades para resolver problemas matemáticos de la escuela primaria. Sin embargo, existe un debate en curso sobre si estos modelos realmente comprenden conceptos matemáticos o explotan patrones dentro de los datos de entrenamiento para producir respuestas correctas. Esto ha llevado a la necesidad de una evaluación más profunda para comprender el alcance de sus capacidades de razonamiento al manejar tipos de problemas complejos e interconectados.
A pesar de su éxito en los puntos de referencia matemáticos existentes, los investigadores identificaron un problema crítico: la mayoría de los LLM necesitan exhibir un razonamiento consistente cuando se enfrentan a preguntas de composición más complejas. Si bien los puntos de referencia estándar implican resolver problemas individuales de forma independiente, los escenarios del mundo real a menudo requieren comprender las relaciones entre múltiples problemas, donde la respuesta a una pregunta debe usarse para resolver otra. Las evaluaciones tradicionales no representan adecuadamente esos escenarios, que se centran únicamente en la resolución de problemas aislados. Esto crea una discrepancia entre los altos puntajes de referencia y la usabilidad práctica de los LLM para tareas complejas que requieren un razonamiento paso a paso y una comprensión más profunda.
Investigadores de Mila, Google DeepMind y Microsoft Research han introducido un nuevo método de evaluación llamado “Matemáticas compositivas de escuela primaria (GSM)”. Este método implica encadenar dos problemas matemáticos separados de modo que la solución del primer problema se convierta en una variable en el segundo problema. Utilizando este enfoque, los investigadores pueden analizar las capacidades de los LLM para manejar dependencias entre preguntas, un concepto que debe ser capturado adecuadamente por los puntos de referencia existentes. El método GSM composicional ofrece una evaluación más completa de las capacidades de razonamiento de los LLM al introducir problemas vinculados que requieren que el modelo transporte información de un problema a otro, lo que hace necesario resolver ambos correctamente para obtener un resultado exitoso.
La evaluación se llevó a cabo utilizando una variedad de LLM, incluidos modelos de peso abierto como LLAMA3 y modelos de peso cerrado como las familias GPT y Gemini. El estudio incluyó tres conjuntos de pruebas: la división de pruebas GSM8K original, una versión modificada de GSM8K en la que se sustituyeron algunas variables y el nuevo conjunto de pruebas GSM composicional, cada uno de los cuales contiene 1200 ejemplos. Los modelos se probaron utilizando un método de indicaciones de 8 disparos, donde se les dieron varios ejemplos antes de pedirles que resolvieran los problemas de composición. Este método permitió a los investigadores comparar el rendimiento de los modelos de manera integral, considerando su capacidad para resolver problemas individualmente y en un contexto compositivo.
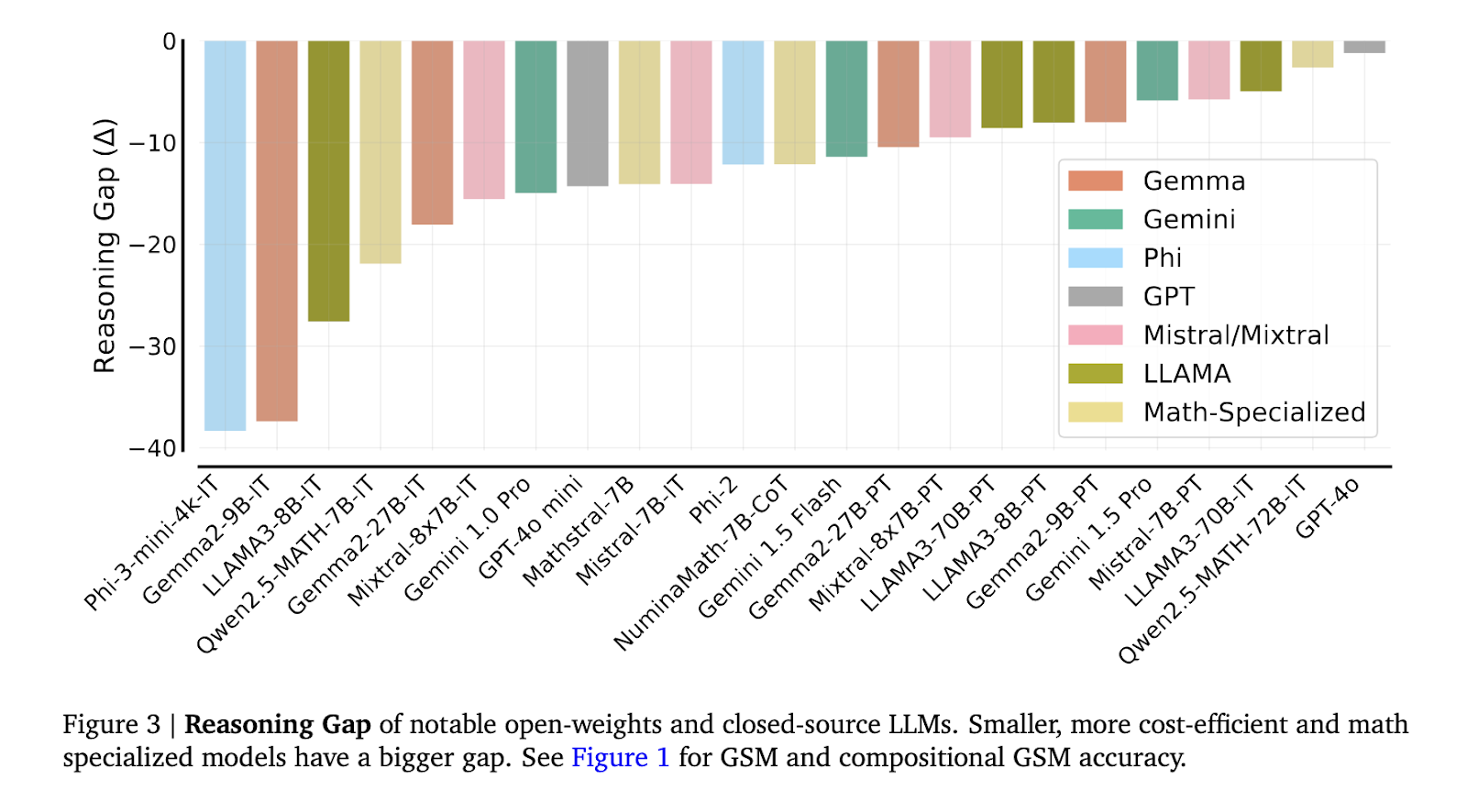
Los resultados mostraron una brecha considerable en la capacidad de razonamiento. Por ejemplo, los modelos rentables como el GPT-4o mini mostraron una brecha de razonamiento de 2 a 12 veces peor en GSM compositivo en comparación con su rendimiento en el GSM8K estándar. Además, los modelos especializados en matemáticas como Qwen2.5-MATH-72B, que lograron más del 80% de precisión en preguntas de nivel competitivo de la escuela secundaria, solo pudieron resolver menos del 60% de los problemas matemáticos de composición de la escuela primaria. Esta caída sustancial sugiere que se necesita algo más que una formación especializada en matemáticas para preparar adecuadamente modelos para tareas de razonamiento de varios pasos. Además, se observó que modelos como LLAMA3-8B y Mistral-7B, a pesar de lograr puntuaciones altas en problemas aislados, mostraron una fuerte caída cuando se requería vincular respuestas entre problemas relacionados.
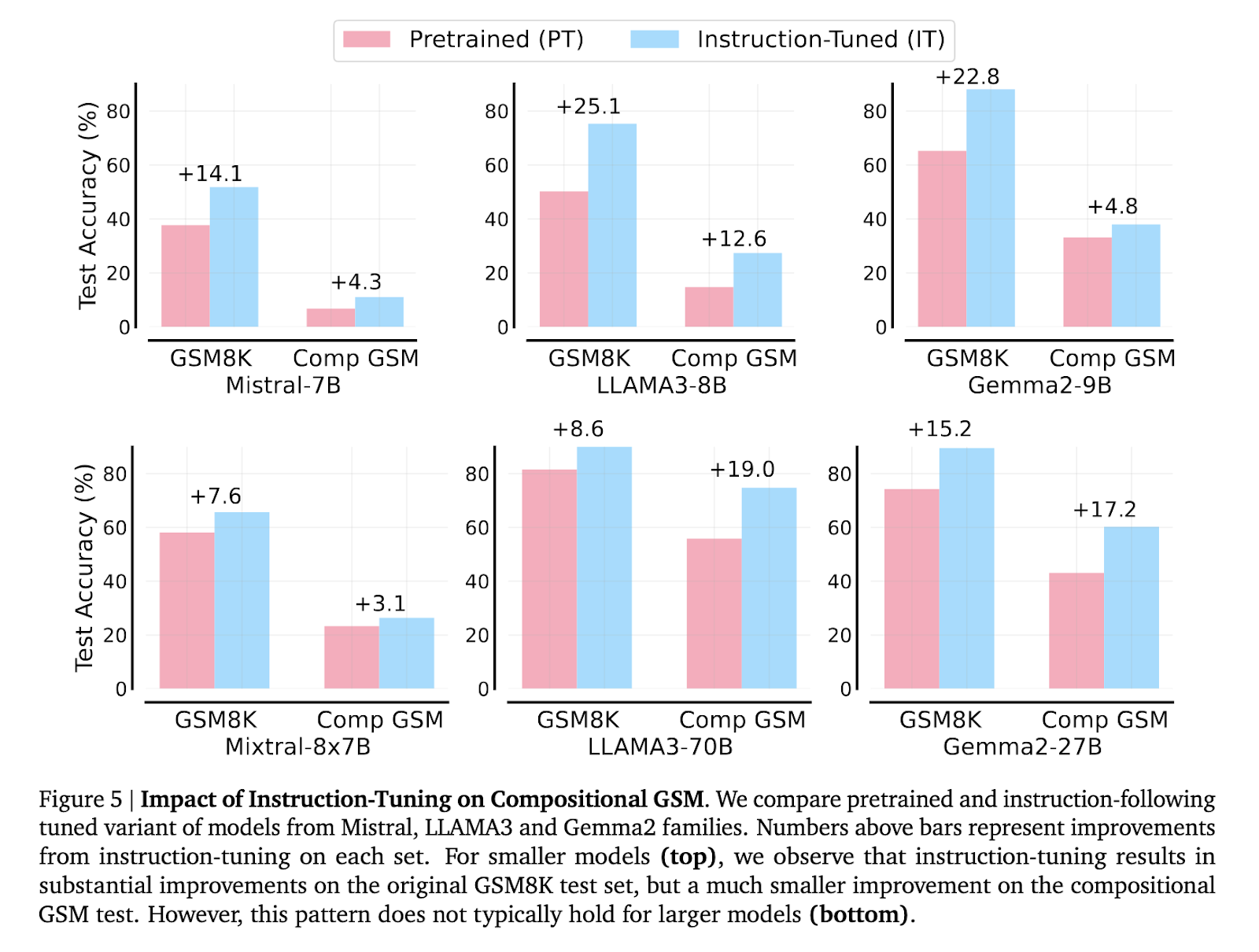
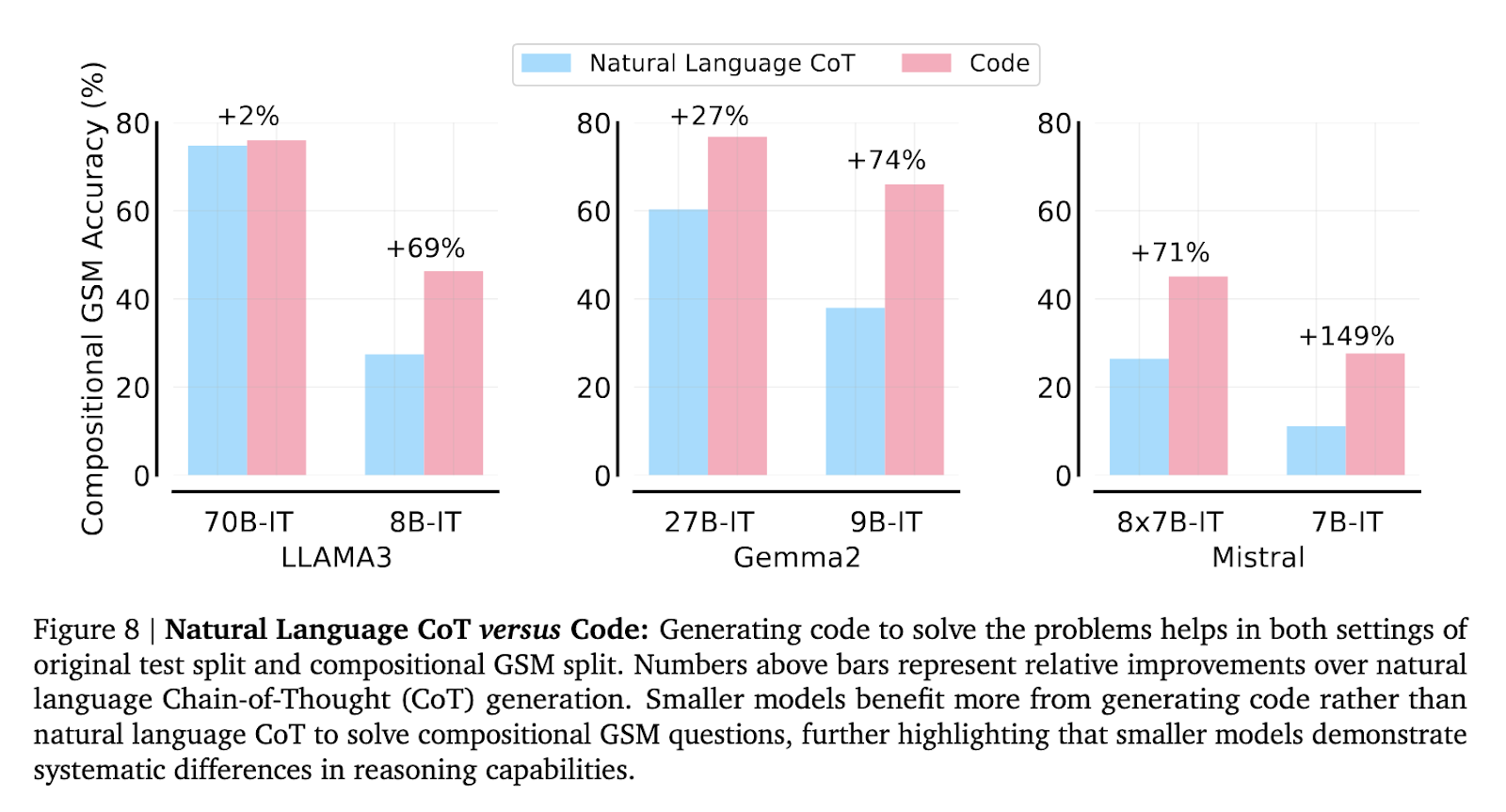
Los investigadores también exploraron el impacto del ajuste de instrucciones y la generación de código en el rendimiento del modelo. El ajuste de instrucciones mejoró los resultados para modelos más pequeños en problemas GSM8K estándar, pero solo generó mejoras menores en la composición GSM. Mientras tanto, generar soluciones de código en lugar de utilizar lenguaje natural resultó en una mejora del 71% al 149% para algunos modelos más pequeños en GSM compositivo. Este hallazgo indica que, si bien la generación de código ayuda a reducir la brecha de razonamiento, no la elimina, y persisten diferencias sistemáticas en las capacidades de razonamiento entre los distintos modelos.
El análisis de las lagunas de razonamiento reveló que la caída del rendimiento no se debió a fugas en el conjunto de pruebas, sino a distracciones causadas por un contexto adicional y un razonamiento deficiente en el segundo salto. Por ejemplo, cuando modelos como LLAMA3-70B-IT y Gemini 1.5 Pro debían resolver una segunda pregunta utilizando la respuesta de la primera, con frecuencia necesitaban aplicar la solución con precisión, lo que daba como resultado respuestas finales incorrectas. Este fenómeno, conocido como brecha de razonamiento del segundo salto, fue más pronunciado en modelos más pequeños, que tendían a pasar por alto detalles cruciales al resolver problemas complejos.
El estudio destaca que los LLM actuales, independientemente de su desempeño en los puntos de referencia estándar, todavía tienen dificultades con las tareas de razonamiento compositivo. El punto de referencia Compositional GSM introducido en la investigación proporciona una herramienta valiosa para evaluar las capacidades de razonamiento de los LLM más allá de la resolución de problemas aislados. Estos resultados sugieren que se necesitan estrategias de entrenamiento y diseños de referencia más sólidos para mejorar las capacidades de composición de estos modelos, permitiéndoles funcionar mejor en escenarios complejos de resolución de problemas. Esta investigación subraya la importancia de reevaluar los métodos de evaluación existentes y priorizar el desarrollo de modelos capaces de razonamiento de varios pasos.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Está interesado en promocionar su empresa, producto, servicio o evento ante más de 1 millón de desarrolladores e investigadores de IA? ¡Colaboremos!
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.