LOONG: un nuevo generador de vídeo autorregresivo basado en LLM que puede generar vídeos de un minuto de duración

La generación de vídeos mediante LLM es un campo emergente con una trayectoria de crecimiento prometedora. Si bien los modelos autorregresivos de lenguaje grande (LLM) se han destacado en la generación de secuencias largas y coherentes de tokens en el procesamiento del lenguaje natural, su aplicación en la generación de videos se ha limitado a videos cortos de unos pocos segundos. Para abordar esto, los investigadores han presentado Loong, un generador de video autorregresivo basado en LLM capaz de generar videos que duran minutos.
Entrenar un modelo de generación de videos como Loong implica un proceso único. El modelo se entrena desde cero, con tokens de texto y tokens de video tratados como una secuencia unificada. Los investigadores propusieron un enfoque de entrenamiento progresivo de corta a larga duración y un esquema de pesaje de pérdidas para mitigar el problema del desequilibrio de pérdidas para el entrenamiento con video largo. Esto permite entrenar a Loong en un video de 10 segundos y luego extenderlo para generar videos largos de un minuto condicionados a indicaciones de texto.
Sin embargo, la generación de vídeos de gran tamaño es bastante más complicada y tiene muchos desafíos por delante. En primer lugar, existe el problema de las pérdidas desequilibradas durante el entrenamiento. Cuando se entrena con el objetivo de predecir el siguiente token, predecir los tokens del fotograma inicial a partir de indicaciones de texto es más difícil que predecir los tokens del fotograma tardío basándose en fotogramas anteriores, lo que genera una pérdida desigual durante el entrenamiento. A medida que aumenta la duración del vídeo, la pérdida acumulada de los tokens fáciles eclipsa la pérdida de los tokens difíciles, dominando la dirección del gradiente. En segundo lugar, El modelo predice el siguiente token basándose en tokens de verdad fundamental, pero se basa en sus propias predicciones durante la inferencia. Esta discrepancia causa acumulación de errores, especialmente debido a fuertes dependencias entre cuadros y muchos tokens de video, lo que lleva a una degradación de la calidad visual en inferencias de video largas.
Para mitigar el desafío de dificultades con el token de vídeo desequilibrado, Los investigadores han propuesto una estrategia de entrenamiento progresiva de corta a larga duración con reponderación de pérdidas, como se demuestra a continuación:
Entrenamiento progresivo de corto a largo
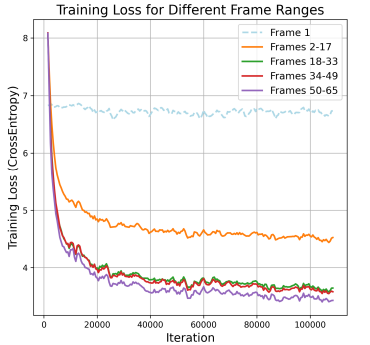
El entrenamiento se divide en tres etapas, lo que aumenta la duración del mismo:
Etapa 1: Modelo previamente entrenado con generación de texto a imagen en un gran conjunto de datos de imágenes estáticas, lo que ayuda al modelo a establecer una base sólida para modelar la apariencia por cuadro.
Etapa 2: Modelo entrenado con imágenes y videoclips cortos, donde el modelo aprende a capturar dependencias temporales a corto plazo.
Etapa 3: Aumentó el número de fotogramas de vídeo y continúa la formación conjunta
Loong está diseñado con un sistema de dos componentes, un tokenizador de video que comprime videos en tokens y un decodificador y un transformador que predice los siguientes tokens de video basándose en tokens de texto.
Loong utiliza la arquitectura CNN 3D para tokenizadorinspirado en MAGViT2. El modelo funciona con vídeos de baja resolución y deja la superresolución para el posprocesamiento. Tokenizer puede comprimir vídeo de 10 segundos (65 fotogramas, resolución de 128*128) en una secuencia de 17*16*16 tokens discretos. La generación de video autorregresiva basada en LLM convierte cuadros de video en tokens discretos, lo que permite que los tokens de texto y video formen una secuencia unificada. La generación de texto a video se modela como tokens de video de predicción autorregresiva basados en tokens de texto que utilizan Transformers solo decodificadores.
Los modelos de lenguaje grandes pueden generalizarse a videos más largos, pero extenderse más allá de las duraciones entrenadas corre el riesgo de acumulación de errores y degradación de la calidad. Existen amplios métodos para corregirlo:
- Recodificación de token de vídeo
- Estrategia de muestreo
- Súper resolución y refinamiento
El modelo utiliza la arquitectura LLaMA, con tamaños que van desde parámetros 700M A 7B. Los modelos se entrenan desde cero sin pesos preentrenados de texto. El vocabulario contiene 32.000 tokens para texto, 8.192 tokens para vídeo y 10 tokens especiales (un total de 40.202). El tokenizador de video replica MAGViT2, utilizando una estructura CNN 3D causal para el primer cuadro de video. Las dimensiones espaciales se comprimen 8x y las temporales 4x. La cuantificación de vectores en clúster (CVQ) se utiliza para la cuantificación, lo que mejora el uso del libro de códigos con respecto a la VQ estándar. El tokenizador de vídeo tiene 246 millones de parámetros.

El modelo Loong genera vídeos largos con una apariencia consistente, gran dinámica de movimiento y transiciones naturales de escenas. Loong se modela con tokens de texto y tokens de video en una secuencia unificada y supera los desafíos del entrenamiento con video largo con el esquema de entrenamiento progresivo de corto a largo y la reponderación de pérdidas. El modelo se puede implementar para ayudar a artistas visuales, productores de cine y fines de entretenimiento. Pero, al mismo tiempo, se puede utilizar erróneamente para crear contenido falso y ofrecer información engañosa.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Está interesado en promocionar su empresa, producto, servicio o evento ante más de 1 millón de desarrolladores e investigadores de IA? ¡Colaboremos!
Nazmi Syed es pasante de consultoría en MarktechPost y está cursando una licenciatura en ciencias en el Instituto Indio de Tecnología (IIT) Kharagpur. Tiene una profunda pasión por la ciencia de datos y explora activamente las amplias aplicaciones de la inteligencia artificial en diversas industrias. Fascinada por los avances tecnológicos, Nazmi está comprometida a comprender e implementar innovaciones de vanguardia en contextos del mundo real.