¿Qué sucede cuando se fusionan los modelos de difusión y autorregresivos? Este artículo sobre IA revela generación con difusión unificada

Los modelos generativos basados en procesos de difusión se han mostrado muy prometedores a la hora de transformar el ruido en datos, pero enfrentan desafíos clave en materia de flexibilidad y eficiencia. Los modelos de difusión existentes normalmente se basan en representaciones de datos fijas (por ejemplo, basadas en píxeles) y programas de ruido uniformes, lo que limita su capacidad para adaptarse a la estructura de conjuntos de datos complejos y de alta dimensión. Esta rigidez genera ineficiencias, lo que hace que los modelos sean computacionalmente costosos y menos efectivos para tareas que requieren un control preciso sobre el proceso generativo, como la síntesis de imágenes de alta resolución y la generación de datos jerárquicos. Además, la separación entre los enfoques generativos autorregresivos y los basados en difusión ha limitado la integración de estos métodos, cada uno de los cuales ofrece distintas ventajas. Abordar estos desafíos es esencial para avanzar en las técnicas de modelado generativo en IA, ya que se requieren modelos más adaptables, eficientes e integrados para satisfacer las crecientes demandas de las aplicaciones modernas de IA.
Los modelos generativos tradicionales basados en difusión, como los de Ho et al. (2020) y Song & Ermon (2019), operan agregando progresivamente ruido a los datos y luego aprendiendo un proceso inverso para generar muestras a partir de ruido. Estos modelos han sido eficaces pero presentan varias limitaciones inherentes. En primer lugar, se basan en una base fija para el proceso de difusión, normalmente utilizando representaciones basadas en píxeles que no logran capturar patrones de múltiples escalas en datos complejos. En segundo lugar, los programas de ruido se aplican uniformemente a todos los componentes de datos, ignorando la importancia variable de las diferentes características. En tercer lugar, el uso de antecedentes gaussianos limita la expresividad de estos modelos a la hora de aproximar distribuciones de datos del mundo real. Estas limitaciones reducen la eficiencia de la generación de datos y dificultan la adaptabilidad de los modelos a diversas tareas, particularmente aquellas que involucran conjuntos de datos complejos donde es necesario preservar o priorizar diferentes niveles de detalle.
Investigadores de la Universidad de Amsterdam presentaron el Difusión Unificada Generativa (GUD) marco para superar las limitaciones de los modelos de difusión tradicionales. Este novedoso enfoque introduce flexibilidad en tres áreas clave: (1) la elección de la representación de datos, (2) el diseño de programas de ruido y (3) la integración de procesos de difusión y autorregresivos mediante condicionamiento suave. Al permitir que la difusión se produzca en diferentes bases, como la base de Fourier o PCA, el modelo puede extraer y generar características de manera eficiente en múltiples escalas. Además, la introducción de programas de ruido por componentes permite variar los niveles de ruido para diferentes componentes de datos, ajustándose dinámicamente a la importancia de cada característica durante el proceso de generación. El mecanismo de condicionamiento suave mejora aún más el marco al unificar los métodos autorregresivos y de difusión, lo que permite el condicionamiento parcial de datos generados previamente y permite soluciones más poderosas y flexibles para tareas generativas en diversos dominios.
El marco propuesto se basa en la ecuación diferencial estocástica (SDE) fundamental utilizada en los modelos de difusión, pero introduce una formulación más general que permite flexibilidad en el proceso de difusión. La capacidad de elegir diferentes bases (p. ej., píxeles, PCA, Fourier) permite que el modelo capture mejor características de múltiples escalas en los datos, particularmente en conjuntos de datos de alta dimensión como CIFAR-10. La programación de ruido por componentes es una característica clave que permite al modelo ajustar dinámicamente el nivel de ruido aplicado a diferentes componentes de datos en función de su relación señal-ruido (SNR). Esto permite que el modelo retenga información crítica en los datos por más tiempo y al mismo tiempo difunda las partes menos relevantes más rápidamente. El mecanismo de condicionamiento suave es particularmente digno de mención, ya que permite la generación de ciertos componentes de datos de manera condicional, cerrando la brecha entre los modelos tradicionales de difusión y autorregresivos. Esto se logra permitiendo que partes de los datos se generen en función de la información que ya se ha producido durante el proceso de difusión, lo que hace que el modelo sea más adaptable a tareas como la pintura de imágenes y la generación de datos jerárquicos.
El Difusión Unificada Generativa (GUD) El marco demostró un rendimiento superior en múltiples conjuntos de datos, mejorando significativamente métricas clave como la probabilidad logarítmica negativa (NLL) y la distancia de inicio de Fréchet (FID). En experimentos con CIFAR-10, el modelo logró un NLL de 3,17 bits/tenue, superando a los modelos de difusión tradicionales que normalmente obtienen una puntuación superior a 3,5 bits/tenue. Además, la flexibilidad del marco GUD para ajustar los programas de ruido condujo a una generación de imágenes más realista, como lo demuestran las puntuaciones FID más bajas. La capacidad de cambiar entre enfoques autorregresivos y basados en difusión a través del mecanismo de condicionamiento suave mejoró aún más sus capacidades generativas, mostrando claros beneficios en términos de eficiencia y calidad de los resultados generados en tareas como la generación de imágenes jerárquicas y la pintura.
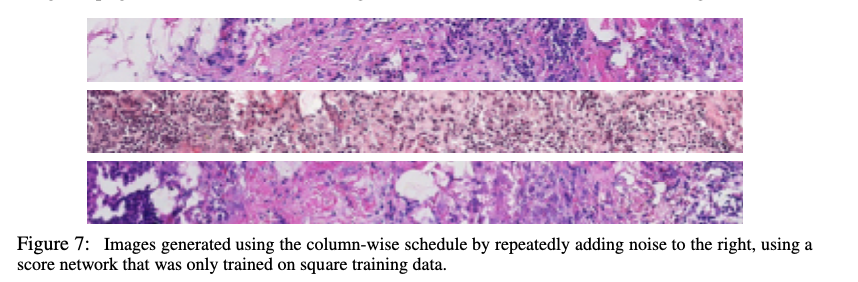
En conclusión, el GUD El marco ofrece un avance importante en el modelado generativo al unificar los procesos de difusión y autorregresivos, y proporcionar una mayor flexibilidad en la representación de datos y la programación del ruido. Esta flexibilidad conduce a una generación de datos más eficiente, adaptable y de mayor calidad en una amplia gama de tareas. Al abordar las limitaciones clave de los modelos de difusión tradicionales, este método allana el camino para futuras innovaciones en IA generativa, particularmente para tareas complejas que requieren generación de datos jerárquicos o condicionales.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Está interesado en promocionar su empresa, producto, servicio o evento ante más de 1 millón de desarrolladores e investigadores de IA? ¡Colaboremos!
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasiona la ciencia de datos y el aprendizaje automático, y aporta una sólida formación académica y experiencia práctica en la resolución de desafíos interdisciplinarios de la vida real.