Revisando los RNN de redes neuronales recurrentes: LSTM y GRU mínimos para un entrenamiento paralelo eficiente

Las redes neuronales recurrentes (RNN) han sido fundamentales en el aprendizaje automático para abordar diversos problemas basados en secuencias, incluido el pronóstico de series temporales y el procesamiento del lenguaje natural. Los RNN están diseñados para manejar secuencias de diferentes longitudes manteniendo un estado interno que captura información a lo largo de pasos de tiempo. Sin embargo, estos modelos a menudo tienen problemas con problemas de gradiente que desaparecen y explotan, lo que reduce su efectividad para secuencias más largas. Para abordar esta limitación, se han desarrollado varios avances arquitectónicos a lo largo de los años, mejorando la capacidad de los RNN para capturar dependencias a largo plazo y realizar tareas más complejas basadas en secuencias.
Un desafío importante en el modelado de secuencias es la ineficiencia computacional de los modelos existentes, particularmente para secuencias largas. Los transformadores se han convertido en una arquitectura dominante y han logrado resultados de última generación en numerosas aplicaciones, como el modelado de lenguajes y la traducción. Sin embargo, su complejidad cuadrática con respecto a la longitud de la secuencia los hace intensivos en recursos y poco prácticos para muchas aplicaciones con secuencias más largas o recursos computacionales limitados. Esto ha llevado a un interés renovado en modelos que puedan equilibrar el rendimiento y la eficiencia, garantizando la escalabilidad sin comprometer la precisión.
Se han propuesto varios métodos actuales para abordar este problema, como modelos de espacio de estados como Mamba, que utilizan transiciones dependientes de la entrada para gestionar secuencias de manera eficiente. Otros métodos, como los modelos de atención lineal, optimizan el entrenamiento al reducir el cálculo necesario para secuencias más largas. A pesar de lograr un rendimiento comparable al de los transformadores, estos métodos a menudo implican algoritmos complejos y requieren técnicas especializadas para una implementación eficiente. Además, los mecanismos basados en la atención como Aaren y S4 han introducido estrategias innovadoras para abordar las ineficiencias, pero aún enfrentan limitaciones, como un mayor uso de memoria y complejidad en la implementación.
Los investigadores de Borealis AI y Mila—Université de Montréal han reexaminado las arquitecturas RNN tradicionales, específicamente los modelos de memoria a corto plazo (LSTM) y unidad recurrente cerrada (GRU). Introdujeron versiones mínimas y simplificadas de estos modelos, denominadas minLSTM y minGRU, para abordar los problemas de escalabilidad que enfrentan sus contrapartes tradicionales. Al eliminar las dependencias de estado ocultas, las versiones mínimas ya no requieren retropropagación en el tiempo (BPTT) y pueden entrenarse en paralelo, lo que mejora significativamente la eficiencia. Este avance permite que estos RNN mínimos manejen secuencias más largas con costos computacionales reducidos, lo que los hace competitivos con los últimos modelos de secuencia.
Los modelos mínimos LSTM y GRU propuestos eliminan varios mecanismos de activación que son computacionalmente costosos e innecesarios para muchas tareas de secuencia. Al simplificar la arquitectura y garantizar que los resultados sean independientes del tiempo en escala, los investigadores pudieron crear modelos que utilizan hasta un 33% menos de parámetros que los RNN tradicionales. Además, la arquitectura modificada permite el entrenamiento paralelo, lo que hace que estos modelos mínimos sean hasta 175 veces más rápidos que los LSTM y GRU estándar cuando manejan secuencias de longitud 512. Esta mejora en la velocidad de entrenamiento es crucial para ampliar los modelos para aplicaciones del mundo real que requieren Manejo de secuencias largas, como generación de texto y modelado de lenguaje.
En términos de rendimiento y resultados, los RNN mínimos demostraron ganancias sustanciales en el tiempo de capacitación y la eficiencia. Por ejemplo, en una GPU T4, el modelo minGRU logró una aceleración de 175 veces en el tiempo de entrenamiento en comparación con el GRU tradicional para una longitud de secuencia de 512, mientras que minLSTM mostró una mejora de 235 veces. Para secuencias aún más largas de longitud 4096, la aceleración fue aún más pronunciada, con minGRU y minLSTM logrando aceleraciones de 1324x y 1361x, respectivamente. Estas mejoras hacen que los RNN mínimos sean muy adecuados para aplicaciones que requieren una capacitación rápida y eficiente. Los modelos también tuvieron un desempeño competitivo con arquitecturas modernas como Mamba en pruebas empíricas, lo que demuestra que los RNN simplificados pueden lograr resultados similares o incluso superiores con una sobrecarga computacional mucho menor.
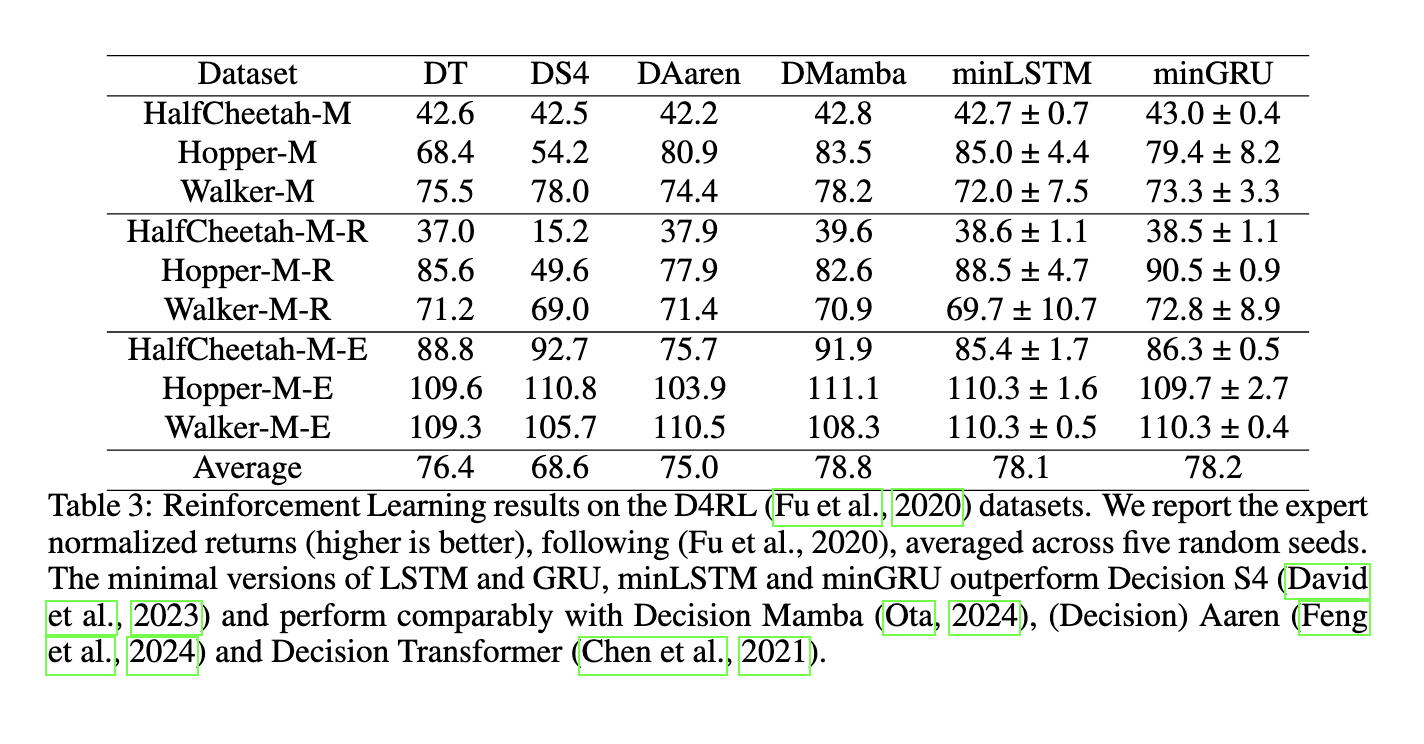
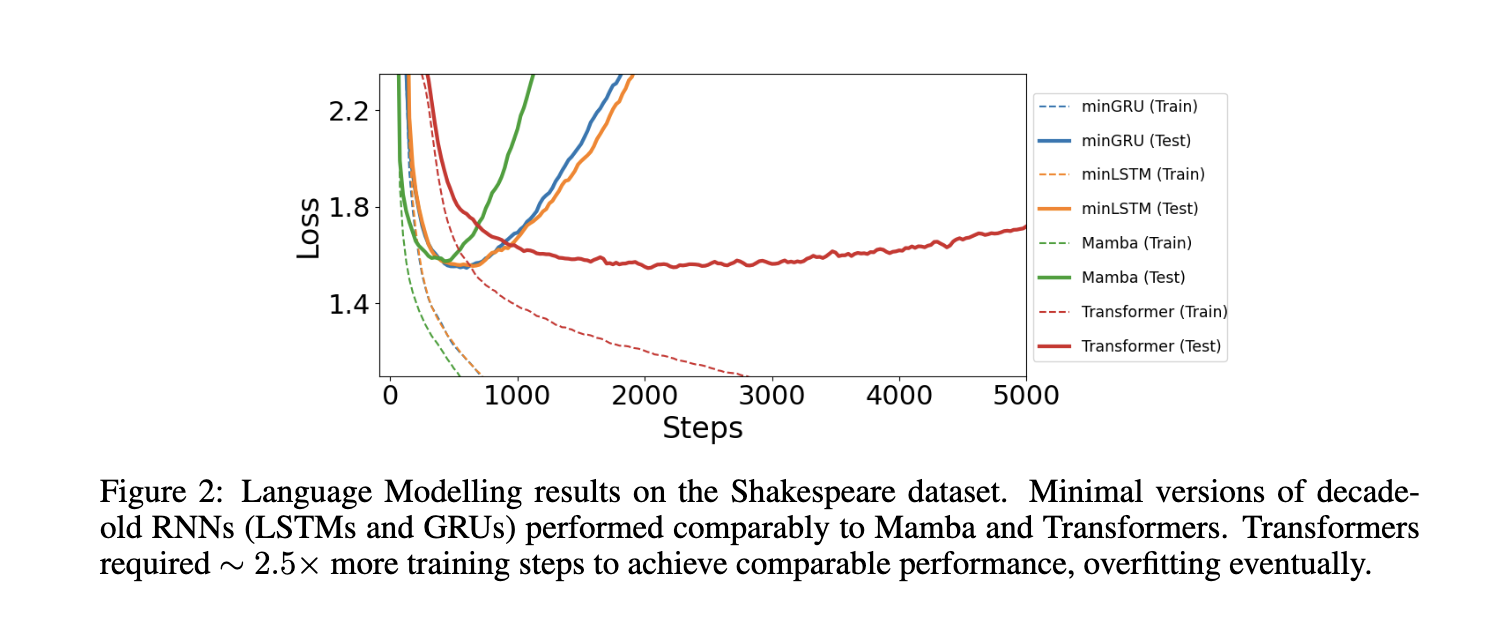
Los investigadores probaron además los modelos mínimos en tareas de aprendizaje por refuerzo y modelado del lenguaje. En los experimentos de aprendizaje por refuerzo, los modelos mínimos superaron a los métodos existentes como Decision S4 y tuvieron un rendimiento comparable a Mamba y Decision Transformer. Por ejemplo, en el conjunto de datos Hopper-Medium, el modelo minLSTM logró una puntuación de rendimiento de 85,0, mientras que minGRU obtuvo una puntuación de 79,4, lo que indica resultados sólidos en distintos niveles de calidad de datos. De manera similar, en las tareas de modelado de lenguaje, minGRU y minLSTM lograron pérdidas de entropía cruzada comparables a los modelos basados en transformadores: minGRU alcanzó una pérdida de 1,548 y minLSTM logró una pérdida de 1,555 en el conjunto de datos de Shakespeare. Estos resultados resaltan la eficiencia y robustez de los modelos mínimos en diversas aplicaciones basadas en secuencias.
En conclusión, la introducción por parte del equipo de investigación de LSTM y GRU mínimos aborda las ineficiencias computacionales de los RNN tradicionales al tiempo que mantiene un sólido rendimiento empírico. Al simplificar los modelos y aprovechar la capacitación paralela, las versiones mínimas ofrecen una alternativa viable a las arquitecturas modernas más complejas. Los hallazgos sugieren que con algunas modificaciones, los RNN tradicionales aún pueden ser efectivos para tareas de modelado de secuencias largas, lo que convierte a estos modelos mínimos en una solución prometedora para futuras investigaciones y aplicaciones en el campo.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Está interesado en promocionar su empresa, producto, servicio o evento ante más de 1 millón de desarrolladores e investigadores de IA? ¡Colaboremos!
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.