Este aprendizaje automático revela cómo los LLM de modelos de lenguaje grandes operan como cadenas de Markov para desbloquear su potencial oculto

Los modelos de lenguajes grandes (LLM) han demostrado capacidades notables en una amplia gama de tareas de procesamiento del lenguaje natural (PLN), como la traducción automática y la respuesta a preguntas. Sin embargo, sigue existiendo un desafío importante para comprender los fundamentos teóricos de su desempeño. Específicamente, falta un marco integral que explique cómo los LLM generan secuencias de texto coherentes y contextualmente relevantes. Este desafío se ve agravado por limitaciones como el tamaño fijo del vocabulario y las ventanas de contexto, que limitan la comprensión completa de las secuencias de tokens que los LLM pueden procesar. Abordar este desafío es esencial para optimizar la eficiencia de los LLM y ampliar su aplicabilidad en el mundo real.
Estudios anteriores se han centrado en el éxito empírico de los LLM, en particular los construidos sobre la arquitectura del transformador. Si bien estos modelos funcionan bien en tareas que involucran la generación secuencial de tokens, las investigaciones existentes han simplificado sus arquitecturas para el análisis teórico o han descuidado las dependencias temporales inherentes a las secuencias de tokens. Esto limita el alcance de sus hallazgos y deja lagunas en nuestra comprensión de cómo los LLM se generalizan más allá de sus datos de capacitación. Además, ningún marco ha derivado con éxito límites de generalización teórica para los LLM cuando manejan secuencias dependientes temporalmente, lo cual es crucial para su aplicación más amplia en tareas del mundo real.
Un equipo de investigadores de ENS Paris-Saclay, Inria Paris, Imperial College London y Huawei Noah’s Ark Lab presenta un marco novedoso al modelar LLM como cadenas de Markov de estado finito, donde cada secuencia de entrada de tokens corresponde a un estado y transiciones entre Los estados están determinados por la predicción del modelo del siguiente token. Esta formulación captura la gama completa de posibles secuencias de tokens, proporcionando una forma estructurada de analizar el comportamiento de LLM. Al formalizar los LLM a través de este marco probabilístico, el estudio ofrece información sobre sus capacidades de inferencia, específicamente la distribución estacionaria de secuencias de tokens y la velocidad a la que el modelo converge a esta distribución. Este enfoque representa un avance significativo en la comprensión de cómo funcionan los LLM, ya que proporciona una base más interpretable y teóricamente fundamentada.
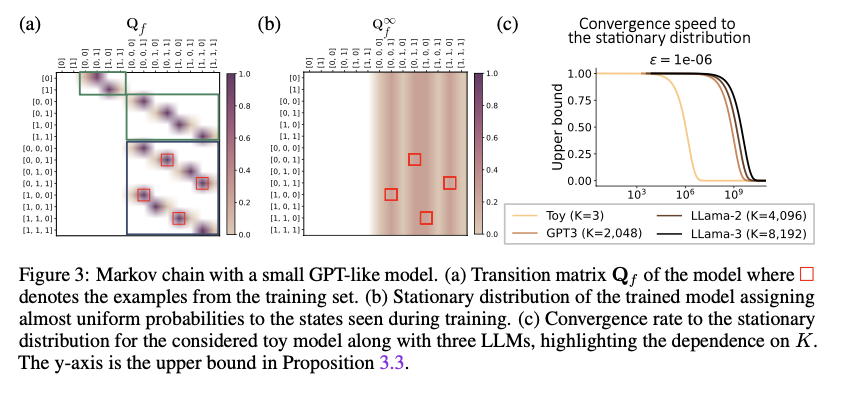
Este método construye una representación en cadena de Markov de LLM definiendo una matriz de transición Qf, que es dispersa y estructurada en bloques, y captura las posibles secuencias de salida del modelo. El tamaño de la matriz de transición es O (T^k), donde T es el tamaño del vocabulario y K es el tamaño de la ventana de contexto. La distribución estacionaria derivada de esta matriz indica el comportamiento de predicción a largo plazo del LLM en todas las secuencias de entrada. Los investigadores también exploran la influencia de la temperatura en la capacidad del LLM para atravesar el espacio de estados de manera eficiente, mostrando que temperaturas más altas conducen a una convergencia más rápida. Estos conocimientos se validaron mediante experimentos con modelos similares a GPT, lo que confirmó las predicciones teóricas.
La evaluación experimental de varios LLM confirmó que modelarlos como cadenas de Markov conduce a una exploración más eficiente del espacio de estados y una convergencia más rápida a una distribución estacionaria. Los ajustes de temperatura más altos mejoraron notablemente la velocidad de convergencia, mientras que los modelos con ventanas de contexto más grandes requirieron más pasos para estabilizarse. Además, el marco superó los enfoques frecuentistas tradicionales en el aprendizaje de matrices de transición, especialmente para espacios estatales grandes. Estos resultados resaltan la solidez y eficiencia de este enfoque al proporcionar conocimientos más profundos sobre el comportamiento del LLM, particularmente en la generación de secuencias coherentes aplicables a tareas del mundo real.
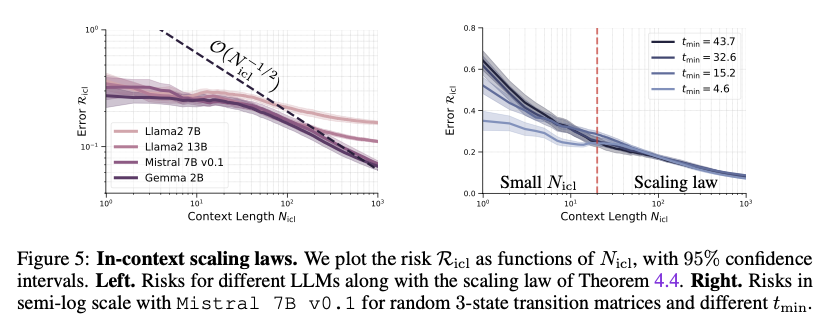
Este estudio presenta un marco teórico que modela los LLM como cadenas de Markov, ofreciendo un enfoque estructurado para comprender sus mecanismos de inferencia. Al derivar límites de generalización y validar experimentalmente el marco, los investigadores demuestran que los LLM aprenden muy eficientemente secuencias de tokens. Este enfoque mejora significativamente el diseño y la optimización de los LLM, lo que conduce a una mejor generalización y un mejor rendimiento en una variedad de tareas de PNL. El marco proporciona una base sólida para futuras investigaciones, particularmente al examinar cómo los LLM procesan y generan secuencias coherentes en diversas aplicaciones del mundo real.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 50.000 ml
(Próximo evento: 17 de octubre de 202) RetrieveX: la conferencia de recuperación de datos GenAI (promovida)
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasiona la ciencia de datos y el aprendizaje automático, y aporta una sólida formación académica y experiencia práctica en la resolución de desafíos interdisciplinarios de la vida real.
(Próximo evento: 17 de octubre de 202) RetrieveX: la conferencia de recuperación de datos de GenAI: únase a más de 300 ejecutivos de GenAI de Bayer, Microsoft, Flagship Pioneering, para aprender cómo crear una búsqueda de IA rápida y precisa en el almacenamiento de objetos. (Promovido)