Una nueva investigación de Google DeepMind revela un nuevo tipo de vulnerabilidad que podría filtrar las indicaciones del usuario en el modelo MoE

El mecanismo de enrutamiento de los modelos MoE plantea un gran desafío en materia de privacidad. Optimice el rendimiento del modelo de lenguaje grande LLM activando selectivamente solo una fracción de sus parámetros totales y al mismo tiempo haciéndolo altamente susceptible a la extracción de datos adversarios a través de interacciones dependientes del enrutamiento. Este riesgo, presente más obviamente con el mecanismo ECR, permitiría a un atacante desviar las entradas del usuario colocando sus consultas diseñadas en el mismo lote de procesamiento que la entrada objetivo. El MoE Tiebreak Leakage Attack explota dichas propiedades arquitectónicas, revelando una falla profunda en el diseño de privacidad que, por lo tanto, debe abordarse cuando dichos modelos MoE se implementen generalmente para aplicaciones en tiempo real que requieren eficiencia y seguridad en el uso de datos.
Los modelos actuales de MoE emplean activación y enrutamiento selectivo de tokens para mejorar la eficiencia al distribuir el procesamiento entre múltiples “expertos”, reduciendo así la demanda computacional en comparación con los LLM densos. Sin embargo, dicha activación selectiva introduce vulnerabilidades porque sus decisiones de enrutamiento dependientes de los lotes hacen que los modelos sean susceptibles a la fuga de información. El principal problema con las estrategias de enrutamiento es que tratan los tokens de manera determinista y no garantizan la independencia entre lotes. Esta dependencia por lotes permite a los adversarios explotar la lógica de enrutamiento, obtener acceso a entradas privadas y exponer una falla de seguridad fundamental en modelos optimizados para la eficiencia computacional a expensas de la privacidad.
Los investigadores de Google DeepMind abordan estas vulnerabilidades con MoE Tiebreak Leakage Attack, un método sistemático que manipula el comportamiento de enrutamiento de MoE para inferir las indicaciones del usuario. Este enfoque de ataque inserta entradas diseñadas junto con un aviso de la víctima que explota el comportamiento determinista del modelo en términos de desempate, donde se observa un cambio observable en la salida cuando la suposición es correcta, lo que hace que se filtren tokens de aviso. Tres componentes fundamentales comprenden este proceso de ataque: (1) adivinación de tokens, en la que un atacante investiga posibles tokens de aviso; (2) manipulación experta del buffer, a través de la cual se utilizan secuencias de relleno para controlar el comportamiento de enrutamiento; y (3) recuperación de ruta de enrutamiento para comprobar la exactitud de las conjeturas a partir de variaciones en las diferencias de salida en varios pedidos por lotes. Esto revela un vector de ataque de canal lateral de las arquitecturas MoE no examinado previamente y requiere consideraciones centradas en la privacidad durante la optimización de los modelos.
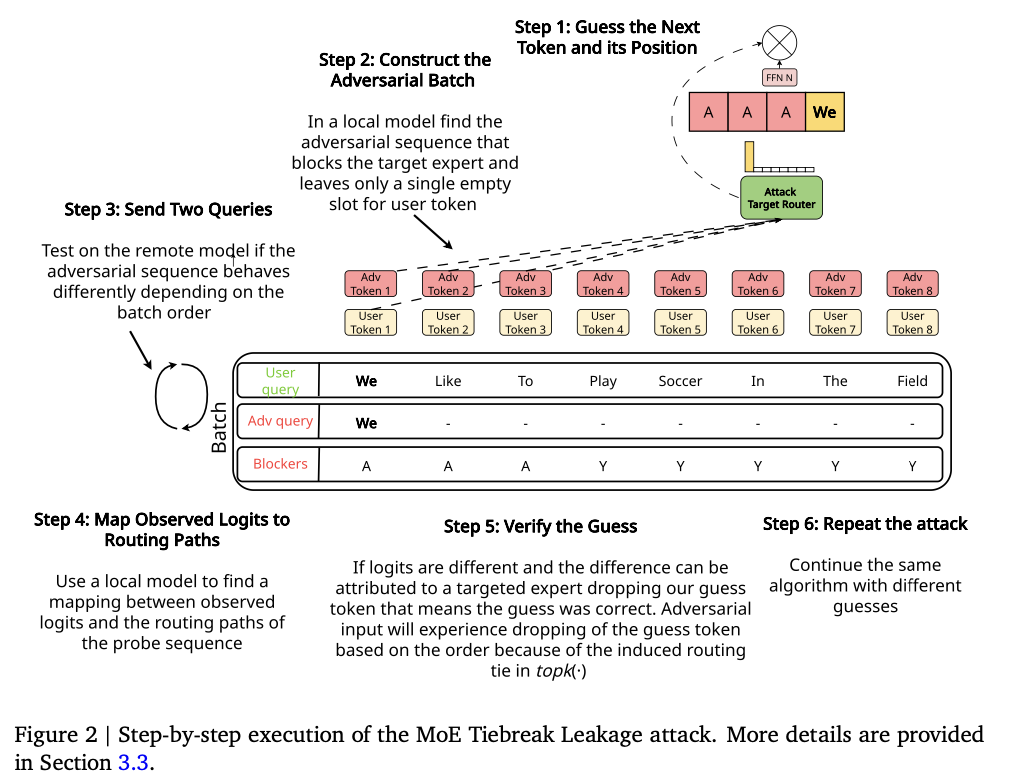
El ataque de fuga de desempate de MoE se experimenta en un modelo Mixtral de ocho expertos con enrutamiento basado en ECR, utilizando la implementación PyTorch CUDA top-k. La técnica reduce el conjunto de vocabulario y las secuencias de relleno artesanal de una manera que afecta las capacidades de los expertos sin hacer que el recorrido sea impredecible. Algunos de los pasos técnicos más críticos son los siguientes:
- Sondeo y verificación de tokens: hizo uso de un mecanismo iterativo de adivinación de tokens en el que las suposiciones del atacante se alinean con el mensaje de la víctima al observar diferencias en el enrutamiento, lo que indica una suposición correcta.
- Control de la capacidad de los expertos: los investigadores emplearon secuencias de relleno para controlar la capacidad del búfer de los expertos. Esto se hizo para que los tokens específicos se enviaran a los expertos previstos.
- Análisis de rutas y mapeo de salidas: utilizando un modelo local que compara las salidas de dos lotes configurados de manera adversa, se identificaron rutas de enrutamiento con un comportamiento de token mapeado para cada entrada de la sonda para verificar que las extracciones sean exitosas.
La evaluación se realizó en mensajes de diferentes longitudes y configuraciones de tokens con una precisión muy alta en la recuperación de tokens y un enfoque escalable para detectar vulnerabilidades de privacidad en arquitecturas dependientes de enrutamiento.
El ataque de fuga de desempate del MoE fue sorprendentemente efectivo: recuperó 4.833 de 4.838 tokens, con una tasa de precisión superior al 99,9%. Los resultados fueron consistentes en todas las configuraciones, con relleno estratégico y controles de enrutamiento precisos que facilitaron una extracción rápida casi completa. Al utilizar consultas de modelos locales para la mayoría de las interacciones, el ataque optimiza la eficiencia sin depender en gran medida de las consultas del modelo de destino para mejorar significativamente la practicidad de las aplicaciones en el mundo real y establecer la escalabilidad del enfoque para diversas configuraciones y ajustes de MoE.

Este trabajo identifica una vulnerabilidad de privacidad crítica dentro de los modelos MoE al aprovechar el potencial del enrutamiento dependiente de lotes en arquitecturas basadas en ECR para extraer datos contradictorios. La recuperación sistemática de mensajes sensibles de los usuarios a través del comportamiento de enrutamiento determinista habilitado por el ataque de fuga de desempate del MoE muestra la necesidad de un diseño seguro dentro de los protocolos de enrutamiento. Las optimizaciones futuras del modelo deberían tener en cuenta los posibles riesgos de privacidad, como los que pueden introducirse mediante la aleatoriedad o la aplicación de la independencia de lotes en el enrutamiento, para disminuir estas vulnerabilidades. Este trabajo enfatiza la importancia de incorporar evaluaciones de seguridad en las decisiones arquitectónicas para los modelos MoE, especialmente cuando las aplicaciones del mundo real dependen cada vez más de los LLM para manejar información confidencial.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(Oportunidad de Patrocinio con nosotros) Promocione su investigación/producto/seminario web con más de 1 millón de lectores mensuales y más de 500.000 miembros de la comunidad
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasiona la ciencia de datos y el aprendizaje automático, y aporta una sólida formación académica y experiencia práctica en la resolución de desafíos interdisciplinarios de la vida real.
Escuche nuestros últimos podcasts de IA y vídeos de investigación de IA aquí ➡️