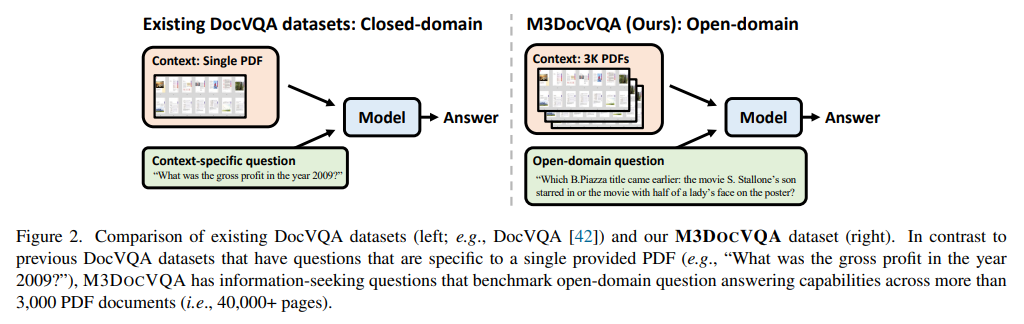
Investigadores de Bloomberg y UNC Chapel Hill presentan M3DocRAG: un novedoso marco RAG multimodal que se adapta de manera flexible a diversos contextos de documentos

Document Visual Question Answering (DocVQA) representa un campo que avanza rápidamente y tiene como objetivo mejorar la capacidad de la IA para interpretar, analizar y responder preguntas basadas en documentos complejos que integran texto, imágenes, tablas y otros elementos visuales. Esta capacidad es cada vez más valiosa en entornos financieros, sanitarios y jurídicos, ya que puede agilizar y respaldar los procesos de toma de decisiones que dependen de la comprensión de información densa y multifacética. Sin embargo, los métodos tradicionales de procesamiento de documentos a menudo necesitan ponerse al día cuando se enfrentan a este tipo de documentos, lo que destaca la necesidad de sistemas multimodales más sofisticados que puedan interpretar información distribuida en diferentes páginas y formatos variados.
El principal desafío en DocVQA es recuperar e interpretar con precisión información que abarca varias páginas o documentos. Los modelos convencionales tienden a centrarse en documentos de una sola página o a basarse en una simple extracción de texto, que puede ignorar información visual crítica como imágenes, gráficos y diseños complejos. Estas limitaciones obstaculizan la capacidad de la IA para comprender completamente documentos en escenarios del mundo real, donde la información valiosa a menudo está incorporada en diversos formatos en varias páginas. Estas limitaciones requieren técnicas avanzadas que integren eficazmente datos visuales y textuales en múltiples páginas de documentos.
Los enfoques DocVQA existentes incluyen sistemas de respuesta visual a preguntas (VQA) de una sola página y de generación aumentada de recuperación (RAG) que utilizan el reconocimiento óptico de caracteres (OCR) para extraer e interpretar texto. Sin embargo, estos métodos aún deben estar completamente equipados para manejar los requisitos multimodales de comprensión detallada de documentos. Los canales RAG basados en texto, si bien son funcionales, normalmente no retienen los matices visuales, lo que puede generar respuestas incompletas. Esta brecha en el rendimiento resalta la necesidad de desarrollar un enfoque multimodal capaz de procesar documentos extensos sin sacrificar la precisión o la velocidad.
Investigadores de UNC Chapel Hill y Bloomberg han presentado M3DocRAGun marco innovador diseñado para mejorar la capacidad de la IA para responder preguntas a nivel de documento en entornos multimodales, de varias páginas y de varios documentos. Este marco incluye un sistema RAG multimodal que incorpora de manera efectiva texto y elementos visuales, lo que permite una comprensión y respuesta de preguntas precisas en varios tipos de documentos. El diseño de M3DocRAG le permitirá trabajar de manera eficiente en escenarios de dominio cerrado y abierto, haciéndolo adaptable en múltiples sectores y aplicaciones.
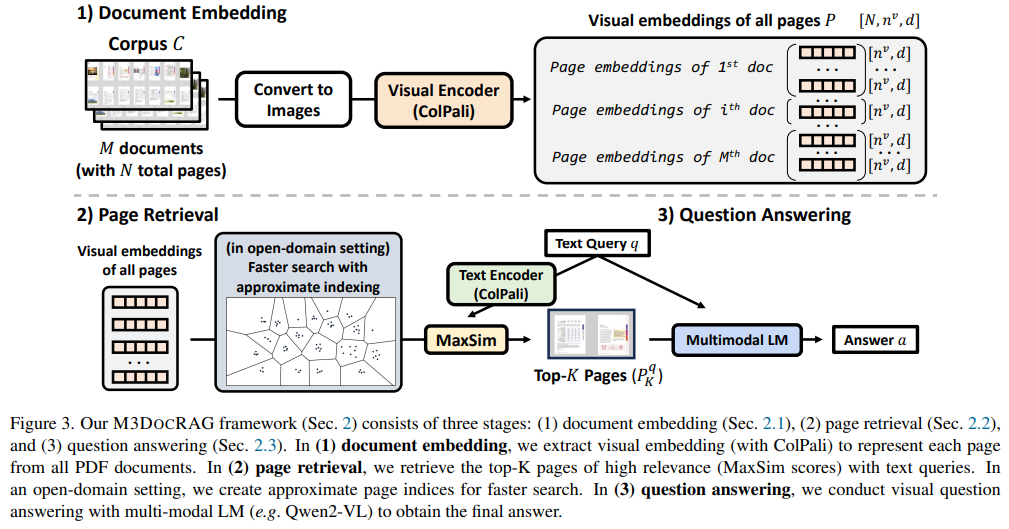
El marco M3DocRAG opera a través de tres etapas principales. Primero, convierte todas las páginas del documento en imágenes y aplica incrustaciones visuales para codificar los datos de la página, asegurando que se conserven las características visuales y textuales. En segundo lugar, utiliza modelos de recuperación multimodal para identificar las páginas más relevantes de un corpus de documentos, utilizando métodos de indexación avanzados para optimizar la velocidad y relevancia de la búsqueda. Finalmente, un modelo de lenguaje multimodal procesa estas páginas recuperadas para generar respuestas precisas a las preguntas de los usuarios. Las incrustaciones visuales garantizan que la información esencial se conserve en varias páginas, abordando las limitaciones principales de los sistemas RAG anteriores de solo texto. M3DocRAG puede operar en conjuntos de documentos a gran escala, manejando hasta 40.000 páginas repartidas en 3.368 documentos PDF con una latencia de recuperación reducida a menos de 2 segundos por consulta, según el método de indexación.
Los resultados de las pruebas empíricas muestran el sólido desempeño de M3DocRAG en tres puntos de referencia clave de DocVQA: M3D OC VQA, MMLongBench-Doc y MP-DocVQA. Estos puntos de referencia simulan desafíos del mundo real, como el razonamiento de varias páginas y la respuesta a preguntas de dominio abierto. M3DocRAG logró una puntuación F1 del 36,5 % en el punto de referencia M3D OC VQA de dominio abierto y un rendimiento de vanguardia en MP-DocVQA, que requiere responder preguntas en un solo documento. La capacidad del sistema para recuperar respuestas con precisión a través de diferentes modalidades de evidencia (texto, tablas, imágenes) respalda su sólido desempeño. La flexibilidad de M3DocRAG se extiende al manejo de escenarios complejos donde las respuestas dependen de evidencia de varias páginas o contenido no textual.
Los hallazgos clave de esta investigación resaltan las ventajas del sistema M3DocRAG sobre los métodos existentes en varias áreas cruciales:
- Eficiencia: M3DocRAG reduce la latencia de recuperación a menos de 2 segundos por consulta para conjuntos de documentos grandes mediante indexación optimizada, lo que permite tiempos de respuesta rápidos.
- Exactitud: El sistema mantiene una alta precisión en diversos formatos y longitudes de documentos al integrar la recuperación multimodal con el modelado de lenguaje, logrando los mejores resultados en pruebas comparativas como M3D OC VQA y MP-DocVQA.
- Escalabilidad: M3DocRAG gestiona eficazmente la respuesta a preguntas de dominio abierto para grandes conjuntos de datos, manejando hasta 3368 documentos o más de 40 000 páginas, lo que establece un nuevo estándar de escalabilidad en DocVQA.
- Versatilidad: este sistema se adapta a diversas configuraciones de documentos en contextos de dominio cerrado (documento único) o de dominio abierto (documentos múltiples) y recupera respuestas de manera eficiente a través de diferentes tipos de evidencia.

En conclusión, M3DocRAG se destaca como una solución innovadora en el campo DocVQA, diseñada para superar las limitaciones tradicionales de los modelos de comprensión de documentos. Aporta una capacidad multimodal, de varias páginas y de varios documentos para la respuesta a preguntas basada en IA, lo que hace avanzar el campo al admitir una recuperación eficiente y precisa en escenarios de documentos complejos. Al incorporar características textuales y visuales, M3DocRAG cierra una brecha significativa en la comprensión de documentos, ofreciendo una solución escalable y adaptable que puede impactar numerosos sectores donde el análisis integral de documentos es fundamental. Este trabajo fomenta la exploración futura en recuperación y generación multimodal, estableciendo un punto de referencia para aplicaciones DocVQA sólidas, escalables y listas para el mundo real.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(Revista/Informe AI) Lea nuestro último informe sobre ‘MODELOS DE LENGUAS PEQUEÑAS‘
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como emprendedor e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
Escuche nuestros últimos podcasts de IA y vídeos de investigación de IA aquí ➡️