Kinetix: un universo abierto de tareas basadas en la física para el aprendizaje por refuerzo

El aprendizaje autosupervisado en conjuntos de datos fuera de línea ha permitido que modelos grandes alcancen capacidades notables tanto en dominios de texto como de imágenes. Aún así, es difícil lograr generalizaciones análogas para los agentes que actúan secuencialmente en problemas de toma de decisiones. Los entornos del aprendizaje por refuerzo (RL) clásico son en su mayoría estrechos y homogéneos y, en consecuencia, difíciles de generalizar.
Los métodos actuales de aprendizaje por refuerzo (RL) a menudo entrenan a los agentes en tareas fijas, lo que limita su capacidad de generalizar a nuevos entornos. Plataformas como mujoco y Gimnasio OpenAI centrarse en escenarios específicos, restringiendo la adaptabilidad del agente. RL se basa en los procesos de decisión de Markov (MDP), donde los agentes maximizan las recompensas acumuladas al interactuar con los entornos. El Diseño de Entorno No Supervisado (UED) aborda estas limitaciones introduciendo un marco profesor-alumno, donde el profesor diseña tareas para desafiar al agente y promover un aprendizaje eficiente. Ciertas métricas garantizan que las tareas no sean ni demasiado fáciles ni imposibles. Herramientas como JAX permiten un entrenamiento RL basado en GPU más rápido a través de la paralelización, mientras que los transformadores, utilizando mecanismos de atención, mejoran el rendimiento de los agentes modelando relaciones complejas en datos secuenciales o desordenados.
Para abordar estas limitaciones, un equipo de investigadores ha desarrollado Kinetixun espacio abierto de entornos RL basados en la física.
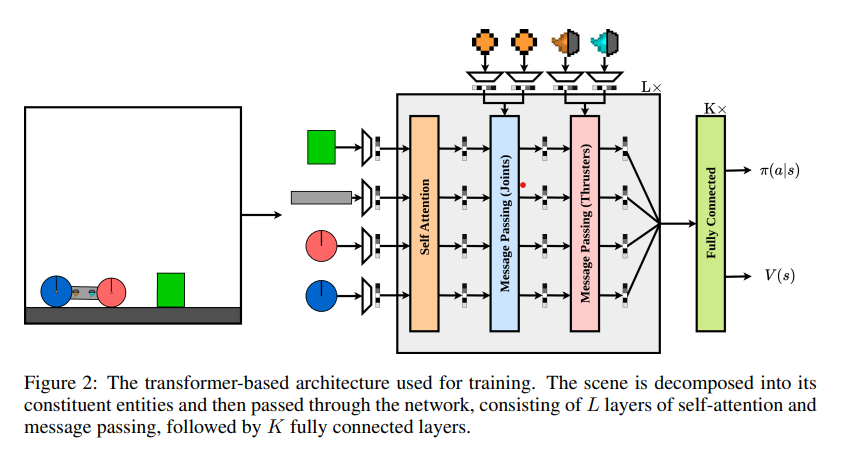
Kinetixpropuesto por un equipo de investigadores de Universidad de Oxfordpuede representar tareas que van desde la locomoción robótica y el agarre hasta videojuegos y entornos clásicos de RL. Kinetix utiliza un novedoso motor de física acelerado por hardware, jax2dque permite la simulación económica de miles de millones de pasos ambientales durante el entrenamiento. El agente entrenado exhibe fuertes capacidades de razonamiento físico, siendo capaz de resolver entornos invisibles diseñados por humanos. Además, ajustar este agente general en tareas de interés muestra un rendimiento significativamente mayor que entrenar a un agente RL tabula rasa. Jax2D aplica pasos de Euler discretos para velocidades de rotación y posicionales y utiliza impulsos y correcciones de orden superior para restringir secuencias instantáneas para una simulación eficiente de tareas físicas diversificadas. Kinetix es adecuado para espacios de acción continuos y multidiscretos y para una amplia gama de tareas de RL.
Los investigadores entrenaron a un agente general de RL en decenas de millones de tareas basadas en física 2D generadas procedimentalmente. El agente exhibió fuertes capacidades de razonamiento físico, siendo capaz de resolver entornos invisibles diseñados por humanos. Ajustar esto demuestra la viabilidad de una capacitación previa a gran escala y de calidad mixta para RL en línea.
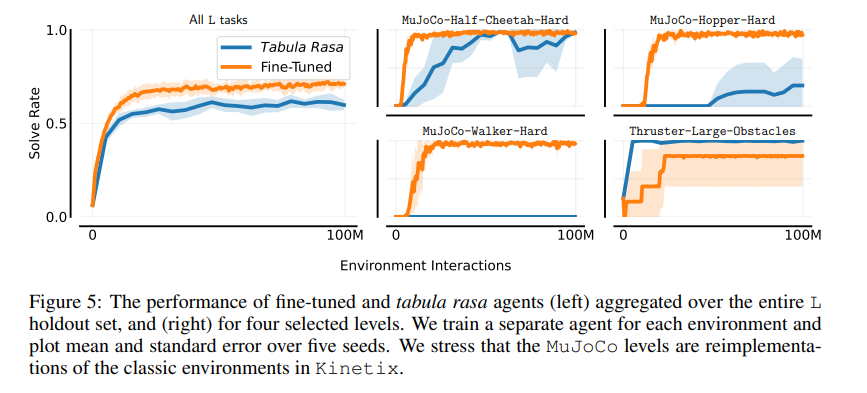
En conclusión, Kinetix es un descubrimiento que aborda las limitaciones de los entornos de RL tradicionales al proporcionar un espacio diverso y abierto para la capacitación, lo que conduce a una mejor generalización y rendimiento de los agentes de RL. Este trabajo puede servir como base para futuras investigaciones sobre la preformación en línea a gran escala de agentes generales de RL y el diseño de entornos no supervisados.
Mira el Página de papel y GitHub. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(SEMINARIO WEB GRATUITO sobre IA) Implementación del procesamiento inteligente de documentos con GenAI en servicios financieros y transacciones inmobiliarias– Del marco a la producción
Nazmi Syed es pasante de consultoría en MarktechPost y está cursando una licenciatura en ciencias en el Instituto Indio de Tecnología (IIT) Kharagpur. Tiene una profunda pasión por la ciencia de datos y explora activamente las amplias aplicaciones de la inteligencia artificial en diversas industrias. Fascinada por los avances tecnológicos, Nazmi está comprometida a comprender e implementar innovaciones de vanguardia en contextos del mundo real.
🐝🐝 Evento de LinkedIn, ‘Una plataforma, posibilidades multimodales’, donde el director ejecutivo de Encord, Eric Landau, y el director de ingeniería de productos, Justin Sharps, hablarán sobre cómo están reinventando el proceso de desarrollo de datos para ayudar a los equipos a construir rápidamente modelos de IA multimodales innovadores.