Colapso del modelo en la era de los datos sintéticos: conocimientos analíticos y estrategias de mitigación

Los modelos de lenguajes grandes (LLM) y los generadores de imágenes enfrentan un desafío crítico conocido como colapso del modelo. Este fenómeno ocurre cuando el rendimiento de estos sistemas de IA se deteriora debido a la creciente presencia de datos generados por IA en sus conjuntos de datos de entrenamiento. A medida que evoluciona la IA generativa, la evidencia sugiere que reentrenar los modelos en sus resultados puede conducir a diversas anomalías en las generaciones posteriores. En los LLM, este proceso introduce defectos irreparables, lo que resulta en la producción de resultados sin sentido o galimatías. Si bien estudios recientes han demostrado empíricamente aspectos del colapso del modelo en diversos entornos, sigue siendo difícil lograr una comprensión teórica integral de este fenómeno. Los investigadores se enfrentan ahora a la urgente necesidad de abordar esta cuestión para garantizar el avance continuo y la fiabilidad de las tecnologías de IA generativa.
Los investigadores han realizado varios intentos para abordar los desafíos del colapso del modelo en grandes modelos de lenguaje y generadores de imágenes. Los LLM y los modelos de difusión actuales se entrenan predominantemente en conjuntos de datos de imágenes a escala web y de texto generados predominantemente por humanos, lo que potencialmente agota todos los datos limpios disponibles en Internet. A medida que los datos sintéticos generados por estos modelos se vuelven cada vez más frecuentes, trabajos recientes han demostrado empíricamente varios aspectos del colapso del modelo en diferentes entornos.
Han surgido enfoques teóricos para analizar el efecto del entrenamiento iterativo en datos autogenerados o mixtos. Estos incluyen estudios sobre la amplificación del sesgo en bucles de retroalimentación de datos, análisis del sesgo de muestreo finito y errores de aproximación de funciones en casos gaussianos, y la exploración de “bucles autoconsumidores” en modelos de visión. Algunos investigadores han investigado escenarios que involucran datos limpios y sintetizados, revelando que una proporción suficientemente alta de datos limpios puede ayudar a mantener la capacidad del generador para reflejar con precisión la verdadera distribución de los datos.
Es importante señalar que el fenómeno del colapso del modelo difiere de la autodestilación, que puede mejorar el rendimiento del modelo mediante procesos controlados de generación de datos. Por el contrario, el colapso del modelo ocurre cuando no hay control sobre el proceso de generación de datos, ya que se trata de datos sintetizados de diversas fuentes en la web.
Investigadores de Meta FAIR, Centro de Ciencia de Datos de la Universidad de Nueva York y el Instituto Courant de la Universidad de Nueva York, presentan un marco teórico para analizar el colapso del modelo en el contexto del aprendizaje supervisado de alta dimensión con regresión del kernel.. Los métodos kernel, a pesar de su simplicidad, ofrecen un enfoque poderoso para capturar características no lineales mientras permanecen dentro del dominio de la optimización convexa. Estos métodos han ganado recientemente una atención renovada como sustitutos de redes neuronales en varios regímenes, incluido el límite de ancho infinito y el régimen de entrenamiento perezoso.
El marco teórico propuesto se basa en investigaciones existentes sobre errores de generalización de leyes de potencia en algoritmos de núcleo de mínimos cuadrados regularizados. Considera el espectro de caída de potencia del núcleo (capacidad) y los coeficientes de la función objetivo (fuente), que se ha demostrado que dan lugar a una escala de ley de potencia de los errores de prueba en términos de tamaño del conjunto de datos y capacidad del modelo. Este enfoque se alinea con las leyes de escala observadas empíricamente en modelos de lenguaje grandes y otros sistemas de inteligencia artificial.
Utilizando conocimientos de estudios de diseño gaussiano y modelos de características aleatorias, este estudio teórico tiene como objetivo proporcionar una comprensión integral del colapso del modelo. El marco incorpora elementos de literatura no paramétrica, análisis espectral y escalamiento de errores de redes neuronales profundas para crear una base sólida para investigar los mecanismos subyacentes al colapso del modelo en entornos de regresión del kernel.
Este estudio teórico sobre el colapso del modelo en entornos de regresión del kernel ofrece varias contribuciones clave:
1. Se proporciona una caracterización exacta del error de prueba bajo reentrenamiento iterativo en datos sintetizados. Los investigadores derivan una fórmula analítica que descompone el error de prueba en tres componentes: el error del entrenamiento con datos limpios, un aumento en el sesgo debido a la generación de datos sintéticos y un factor de escala que crece con cada iteración de generación de datos.
2. El estudio revela que a medida que aumenta el número de generaciones de datos sintéticos, el aprendizaje se vuelve imposible debido a los efectos compuestos de la resintetización de datos.
3. Para los espectros de ley de potencia de la matriz de covarianza, los investigadores establecen nuevas leyes de escala que demuestran cuantitativamente el impacto negativo del entrenamiento en datos generados sintéticamente.
4. El estudio propone un parámetro de regularización de crestas óptimo que corrige el valor sugerido en la teoría clásica para datos limpios. Esta corrección se adapta a la presencia de datos sintetizados en el conjunto de entrenamiento.
5. Se identifica un fenómeno de cruce único en el que el ajuste apropiado del parámetro de regularización puede mitigar los efectos del entrenamiento en datos falsos, pasando de una tasa de error rápida en el régimen sin ruido a una tasa más lenta que depende de la cantidad de datos verdaderos utilizados en el generación inicial de datos falsos.
Estos hallazgos proporcionan un marco teórico integral para comprender y potencialmente mitigar los efectos del colapso del modelo en entornos de regresión del kernel, ofreciendo conocimientos que podrían ser valiosos para mejorar la solidez de grandes modelos de lenguaje y otros sistemas de inteligencia artificial.
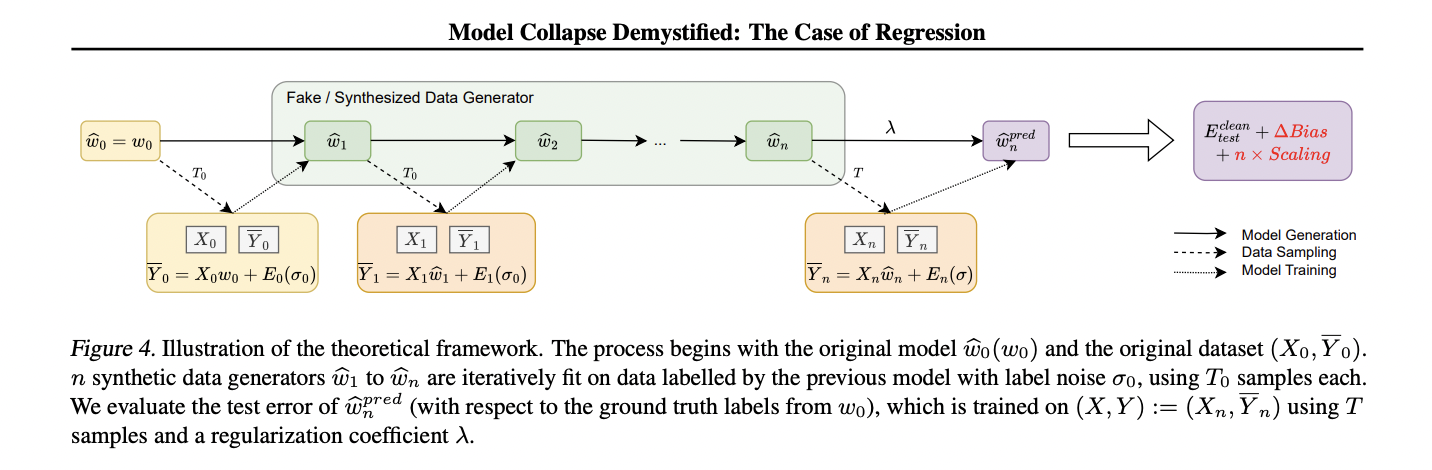
Este marco para analizar el colapso del modelo en entornos de regresión kernel se basa en una configuración cuidadosamente construida que equilibra la manejabilidad analítica con la capacidad de exhibir una amplia gama de fenómenos. El núcleo de este marco es un modelo de distribución de datos PΣ,w0,σ2, donde las entradas x se extraen de una distribución gaussiana multivariada N(0, Σ), y las etiquetas y se generan mediante una función de verdad lineal con ruido añadido.
El estudio introduce un proceso de generación de datos falso que crea iterativamente nuevos modelos. Partiendo de la distribución original PΣ,w0,σ2
0, cada generación posterior PΣ,wbn,σ2
n se crea ajustando un modelo a datos muestreados de la generación anterior. Este proceso simula el efecto del entrenamiento sobre datos cada vez más sintéticos.
El modelo descendente, que es el foco del análisis, es un predictor de regresión de cresta wb
pred n. Este predictor se entrena con datos de la enésima generación de la distribución de datos falsos, pero se evalúa con la distribución de datos verdadera. Los investigadores examinan la dinámica del error de prueba Etest(wb
pred n) a medida que aumenta el número de generaciones n.
Si bien el marco se presenta en términos de regresión lineal para mayor claridad, los autores señalan que se puede extender a los métodos kernel. Esta extensión implica reemplazar la entrada x con un mapa de características inducido por un núcleo K, lo que permite que el marco capture relaciones no lineales en los datos.


Este marco teórico desarrollado en este estudio arroja varios resultados importantes que arrojan luz sobre la dinámica del colapso del modelo en entornos de regresión kernel:
1. Para la regresión no regularizada, el error de prueba del modelo descendente crece linealmente con el número de generaciones de datos sintéticos, lo que indica una clara degradación del rendimiento.
2. En el caso regularizado, el error de prueba se descompone en tres componentes: sesgo, varianza y un término adicional que crece con el número de generaciones. Esta descomposición proporciona una imagen clara de cómo se manifiesta el colapso del modelo en el error de prueba.
3. El estudio revela que la fuerza del generador de datos falsos, representada por el tamaño de muestra T0, juega un papel crucial a la hora de determinar el impacto en el rendimiento del modelo descendente. Cuando T0 es suficientemente grande (régimen subparametrizado), sólo se ve afectado el término de varianza. Sin embargo, cuando T0 es pequeño (régimen sobreparametrizado), tanto los términos de sesgo como de varianza se ven afectados negativamente.
4. En ausencia de ruido en las etiquetas, el estudio demuestra que aún puede ocurrir un colapso del modelo debido a datos insuficientes en el proceso de generación de datos sintéticos. Esto es particularmente pronunciado cuando los generadores de datos falsos son independientes entre generaciones, lo que lleva a un crecimiento exponencial del término de sesgo.
5. La investigación proporciona fórmulas explícitas para el error de prueba en varios escenarios, incluidas estructuras de covarianza de características isotrópicas y anisotrópicas. Estas fórmulas permiten un análisis detallado de cómo los diferentes parámetros influyen en la gravedad del colapso del modelo.
Estos resultados en conjunto brindan una comprensión teórica integral del colapso del modelo, ofreciendo información sobre sus mecanismos y posibles estrategias de mitigación a través de procesos apropiados de regularización y generación de datos.
Los resultados revelan que el colapso del modelo representa una modificación de las leyes de escala típicas cuando es inducido por datos falsos. Para una presentación más clara, los hallazgos asumen una condición en la que el tamaño de la muestra inicial es mayor o igual a la dimensionalidad más dos. El estudio examina la generación de datos falsos con múltiples iteraciones, centrándose en un predictor de crestas basado en una muestra de datos falsos. Este predictor utiliza un parámetro de regularización adaptado de forma adaptativa. El error de prueba de este predictor sigue una ley de escala específica bajo ciertos límites matemáticos. Estos resultados ofrecen información importante sobre cómo se comportan y funcionan los modelos entrenados con datos falsos, particularmente en términos de sus tasas de error y cómo estas tasas escalan con diferentes parámetros.
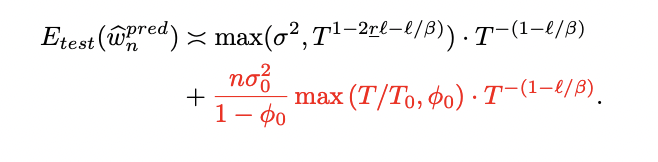
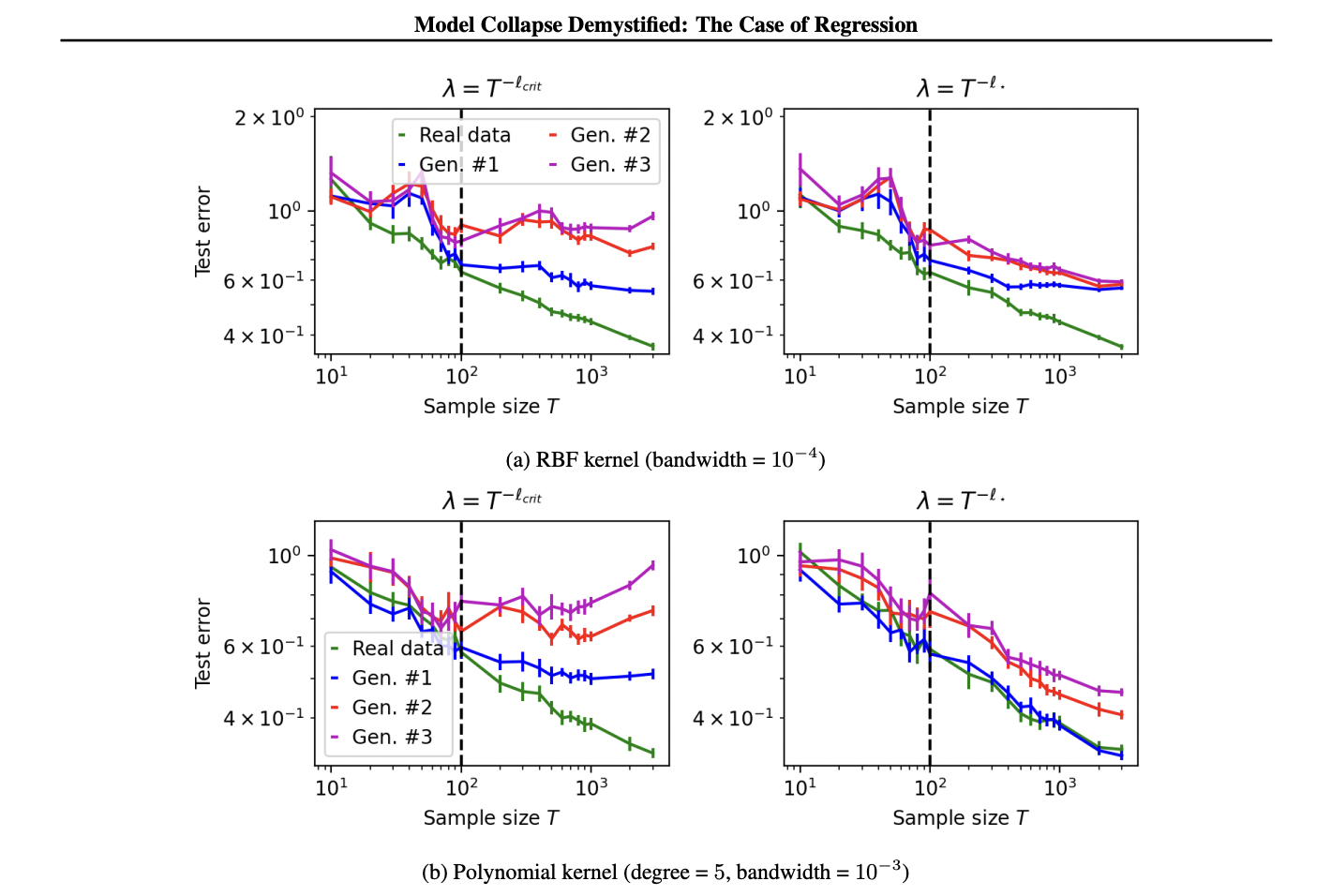
El estudio realiza experimentos utilizando datos reales y simulados para validar empíricamente los resultados teóricos. Para datos simulados, se realiza una regresión de cresta lineal ordinaria en un espacio de 300 dimensiones, explorando diferentes estructuras para la matriz de covarianza de entrada. El generador de datos falsos se construye según un proceso específico y se ajustan modelos de crestas aguas abajo para varios tamaños de muestra. Los conjuntos de prueba consisten en pares de datos limpios de la distribución real, con experimentos repetidos para generar barras de error.
Los experimentos con datos reales se centran en la regresión de la cresta del núcleo utilizando el conjunto de datos MNIST, un punto de referencia popular en el aprendizaje automático. El problema de clasificación se convierte en regresión modificando etiquetas con ruido añadido. Los datos de entrenamiento falsos se generan mediante la regresión de crestas del núcleo con RBF y núcleos polinomiales. Los investigadores examinan diferentes tamaños de muestras y ajustan modelos de crestas del núcleo aguas abajo. Estos experimentos también se repiten varias veces para tener en cuenta las variaciones en el ruido de las etiquetas.
Los resultados se presentan a través de varias figuras, que ilustran el rendimiento del modelo en diferentes condiciones, incluidas configuraciones isotrópicas y de ley de potencia, así como escenarios sobreparametrizados. Los hallazgos de experimentos con datos reales y simulados brindan apoyo empírico a las predicciones teóricas realizadas anteriormente en el estudio.
Este estudio marca un cambio significativo en la comprensión de las tasas de error de las pruebas a medida que el mundo entra en la “era de los datos sintéticos”. Proporciona información analítica sobre el fenómeno del colapso del modelo, revelándolo como una modificación de las leyes de escala habituales inducidas por datos de entrenamiento sintéticos. Los hallazgos sugieren que la proliferación de contenido generado por IA podría potencialmente obstaculizar futuros procesos de aprendizaje, aumentando potencialmente el valor de los datos no generados por IA. En la práctica, la investigación indica que los datos generados por IA alteran la regularización óptima para los modelos posteriores, lo que sugiere que los modelos entrenados con datos mixtos pueden mejorar inicialmente pero luego disminuir su rendimiento. Esto requiere una reevaluación de los enfoques de formación actuales en la era de los datos sintéticos.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de 52k+ ML.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Asjad es consultor interno en Marktechpost. Está cursando B.Tech en ingeniería mecánica en el Instituto Indio de Tecnología, Kharagpur. Asjad es un entusiasta del aprendizaje automático y el aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en la atención médica.