Lógica del pensamiento: mejora del razonamiento lógico en modelos de lenguaje grandes mediante el aumento de la lógica proposicional

Los modelos de lenguaje grandes (LLM) han logrado avances significativos en diversas tareas de procesamiento del lenguaje natural, pero todavía tienen dificultades con las matemáticas y el razonamiento lógico complejo. La estimulación de la cadena de pensamiento (CoT) ha surgido como un enfoque prometedor para mejorar las capacidades de razonamiento mediante la incorporación de pasos intermedios. Sin embargo, los LLM a menudo exhiben razonamientos infieles, donde las conclusiones no se alinean con la cadena de razonamiento generada. Este desafío ha llevado a los investigadores a explorar topologías de razonamiento y métodos neurosimbólicos más sofisticados. Estos enfoques tienen como objetivo simular procesos de razonamiento humano e integrar el razonamiento simbólico con los LLM. A pesar de estos avances, los métodos existentes enfrentan limitaciones, particularmente el problema de la pérdida de información durante la extracción de expresiones lógicas, lo que puede conducir a procesos de razonamiento intermedio incorrectos.
Los investigadores han desarrollado varios enfoques para mejorar las capacidades de razonamiento de los LLM. Las indicaciones de CoT y sus variantes, como CoT de disparo cero y CoT con autoconsistencia, han mejorado el razonamiento lógico al dividir problemas complejos en pasos intermedios. Otros métodos, como las indicaciones de menor a mayor y Divide y vencerás, se centran en la descomposición del problema. El árbol de pensamientos y el gráfico de pensamientos introducen topologías de razonamiento más complejas. Los enfoques neurosimbólicos combinan los LLM con el razonamiento simbólico para abordar el razonamiento infiel. Estos incluyen LReasoner, LogicAsker, Logic-LM, SatLM y LINC, que integran formalización lógica, solucionadores simbólicos y LLM para mejorar las capacidades de razonamiento y superar los problemas de pérdida de información.
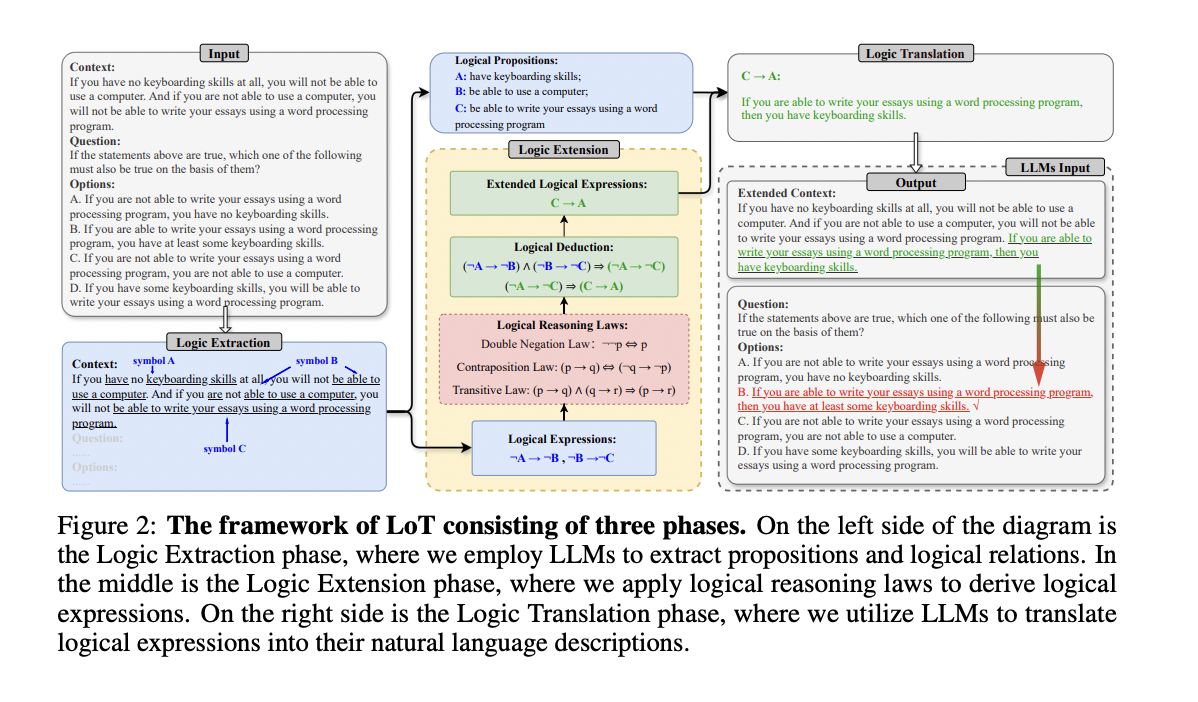
Investigadores de la Universidad de Ciencia y Tecnología de China, el Instituto de Automatización, la Academia China de Ciencias, la Universidad de Beihang y JD.com presentes Lógica del pensamiento (LoT)un método de estimulación único diseñado para abordar el problema de la pérdida de información en los enfoques neurosimbólicos existentes. LoT extrae proposiciones y expresiones lógicas del contexto de entrada, las expande utilizando leyes de razonamiento lógico y traduce las expresiones expandidas nuevamente al lenguaje natural. Luego, esta descripción lógica ampliada se adjunta al mensaje de entrada original, lo que guía el proceso de razonamiento del LLM. Al preservar el mensaje original y agregar información lógica en lenguaje natural, LoT evita la dependencia total de solucionadores simbólicos y mitiga la pérdida de información. El método es compatible con las técnicas de estimulación existentes, lo que permite una integración perfecta. Los experimentos realizados en cinco conjuntos de datos de razonamiento lógico demuestran la eficacia de LoT para mejorar significativamente el rendimiento de varios métodos de estimulación, incluidos la cadena de pensamiento, la autoconsistencia y el árbol de pensamientos.
El marco de LoT comprende tres fases clave: extracción lógica, extensión lógica y traducción lógica. En la fase de Extracción Lógica, los LLM identifican oraciones con relaciones de razonamiento condicional y extraen símbolos proposicionales y expresiones lógicas del contexto de entrada. La fase de Extensión Lógica emplea un programa Python para expandir estas expresiones lógicas utilizando leyes de razonamiento predefinidas. Finalmente, la fase de traducción lógica utiliza LLM para convertir las expresiones lógicas expandidas nuevamente en descripciones en lenguaje natural. Luego, estas descripciones se incorporan al mensaje de entrada original, creando un mensaje nuevo e integral para los LLM. Este proceso preserva el contexto original al tiempo que lo aumenta con información lógica adicional, guiando eficazmente el proceso de razonamiento del LLM sin depender únicamente de solucionadores simbólicos ni correr el riesgo de perder información.
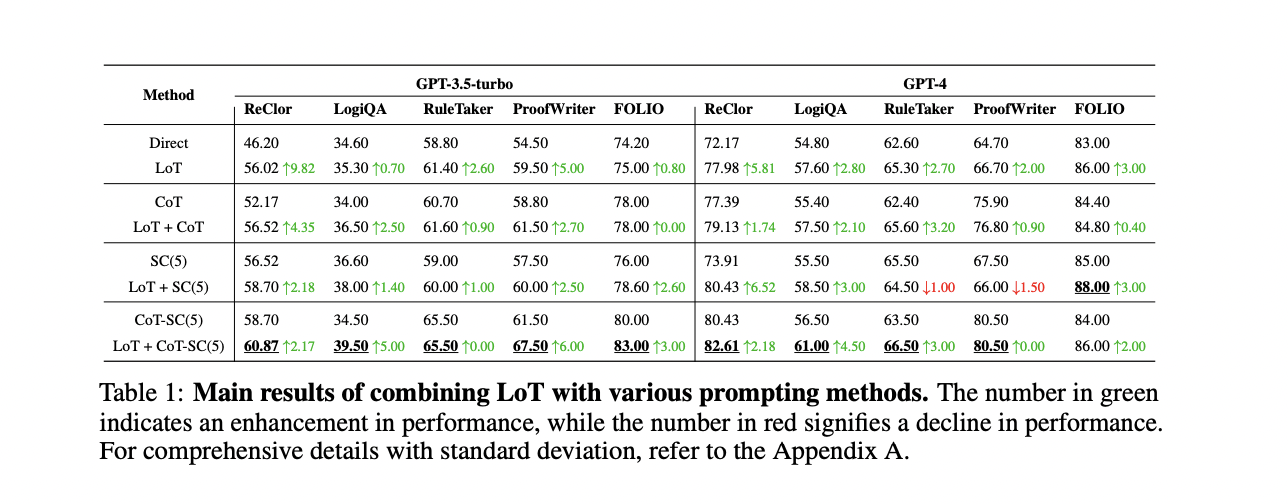
Las indicaciones de LoT mejoran significativamente el rendimiento de los métodos existentes en cinco conjuntos de datos de razonamiento lógico. LoT+CoT-SC(5) supera consistentemente a otros métodos, y LoT+SC logra la mayor precisión en el conjunto de datos FOLIO con GPT-4. LoT mejora los métodos de referencia en 35 de 40 comparaciones, lo que demuestra su perfecta integración y eficacia. Se producen mejoras menores al combinar LoT con CoT o CoT-SC debido a capacidades superpuestas. Se observan algunas limitaciones en los conjuntos de datos de RuleTaker y ProofWriter con GPT-4, atribuidas a problemas de extracción de información. En general, el rendimiento independiente de LoT iguala o supera a CoT, lo que destaca sus sólidas capacidades de razonamiento lógico.

LoT es un sólido enfoque de mejora simbólica que aborda la pérdida de información en métodos neurosimbólicos. Al derivar información lógica ampliada del contexto de entrada utilizando lógica proposicional, LoT aumenta las indicaciones originales para mejorar las capacidades de razonamiento lógico de los LLM. Su compatibilidad con técnicas de estimulación existentes como Cadena de Pensamiento, Autoconsistencia y Árbol de Pensamientos permite una integración perfecta. Los experimentos demuestran que LoT mejora significativamente el rendimiento de varios métodos de estimulación en múltiples conjuntos de datos de razonamiento lógico. El trabajo futuro se centrará en explorar relaciones lógicas adicionales y leyes de razonamiento, así como en respaldar más métodos de estimulación para mejorar aún más las capacidades de razonamiento lógico de LoT.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
Asjad es consultor interno en Marktechpost. Está cursando B.Tech en ingeniería mecánica en el Instituto Indio de Tecnología, Kharagpur. Asjad es un entusiasta del aprendizaje automático y el aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en la atención médica.