Este artículo de IA de KAIST, UCL y KT investiga la adquisición y retención de conocimiento fáctico en modelos de lenguaje grandes

Los modelos de lenguaje grande (LLM) han atraído una atención significativa por su capacidad para comprender y generar texto similar al humano. Estos modelos poseen la capacidad única de codificar conocimiento fáctico de manera efectiva, gracias a la gran cantidad de datos con los que están entrenados. Esta capacidad es crucial en diversas aplicaciones, que van desde tareas de procesamiento del lenguaje natural (PNL) hasta formas más avanzadas de inteligencia artificial. Sin embargo, comprender cómo estos modelos adquieren y retienen información objetiva durante el entrenamiento previo es un desafío complejo. Esta investigación investiga el intrincado proceso a través del cual los LLM internalizan el conocimiento y explora cómo estos modelos pueden optimizarse para mantener y generalizar el conocimiento que adquieren.
Uno de los principales problemas que enfrentan los investigadores en la formación de LLM es la pérdida de conocimiento fáctico con el tiempo. Cuando se utilizan grandes conjuntos de datos en la capacitación previa, los LLM luchan por retener los detalles de hechos específicos, especialmente cuando se introduce nueva información en etapas posteriores de la capacitación. Además, los LLM a menudo tienen dificultades para recordar conocimientos poco comunes o de cola larga, lo que afecta significativamente su capacidad para generalizar sobre diversos temas. Esta pérdida de retención afecta la precisión de los modelos cuando se aplican a escenarios complejos o que se encuentran con poca frecuencia, lo que presenta una barrera considerable para mejorar el desempeño de los LLM.
Se han introducido varios métodos para abordar estos desafíos, centrándose en mejorar la adquisición y retención de conocimientos fácticos en los LLM. Estos métodos incluyen la ampliación del tamaño de los modelos y el entrenamiento previo de conjuntos de datos, el uso de técnicas de optimización avanzadas y la modificación del tamaño de los lotes para manejar mejor los datos durante el entrenamiento. También se ha propuesto la deduplicación de conjuntos de datos para reducir la redundancia en los datos de entrenamiento, lo que lleva a un aprendizaje más eficiente. A pesar de estos esfuerzos, persisten los problemas fundamentales del olvido rápido y la dificultad del modelo para generalizar hechos menos frecuentes, y las soluciones actuales sólo han logrado mejoras incrementales.
Investigadores de KAIST, UCL y KT han introducido un enfoque novedoso para estudiar la adquisición y retención de conocimientos fácticos en los LLM. Diseñaron un experimento que sistemáticamente inyectaba nuevos conocimientos fácticos en el modelo durante el entrenamiento previo. Al analizar la capacidad del modelo para memorizar y generalizar este conocimiento en diversas condiciones, los investigadores pretendieron descubrir la dinámica que gobierna cómo los LLM aprenden y olvidan. Su enfoque implicó monitorear el desempeño del modelo a través de diferentes puntos de control y observar el efecto de factores como el tamaño del lote, la duplicación de datos y la paráfrasis en la retención de conocimientos. Este experimento ofreció información valiosa sobre la optimización de las estrategias de entrenamiento para mejorar la memoria a largo plazo en los LLM.
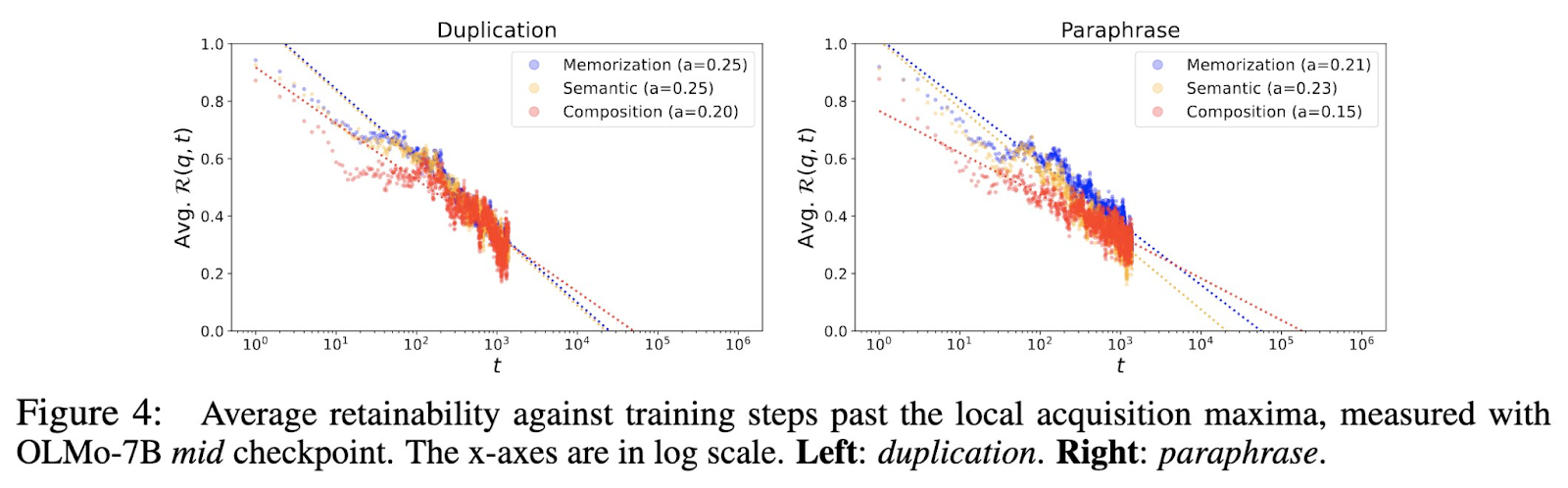
La metodología de los investigadores fue exhaustiva e implicó una evaluación detallada en múltiples etapas de capacitación previa. Realizaron los experimentos utilizando conocimiento ficticio que el modelo no había encontrado antes para garantizar la precisión del análisis. Se probaron varias condiciones, incluida inyectar el mismo conocimiento factual repetidamente, parafrasearlo o presentarlo solo una vez. Para medir la eficacia de la retención de conocimientos, el equipo evaluó el rendimiento del modelo examinando los cambios en la probabilidad de recordar hechos específicos a lo largo del tiempo. Descubrieron que los lotes más grandes ayudaban al modelo a mantener el conocimiento fáctico de manera más efectiva, mientras que los datos duplicados conducían a un olvido más rápido. Al utilizar una variedad de condiciones de prueba, el equipo de investigación pudo determinar las estrategias más efectivas para capacitar a los LLM para retener y generalizar conocimientos.
El desempeño de la metodología propuesta reveló varios hallazgos clave. En primer lugar, la investigación demostró que los modelos más grandes, como aquellos con 7 mil millones de parámetros, exhibían una mejor retención del conocimiento fáctico que los modelos más pequeños con sólo 1 mil millones de parámetros. Curiosamente, la cantidad de datos de entrenamiento utilizados no afectó significativamente la retención, lo que contradice la creencia de que más datos conducen a un mejor rendimiento del modelo. En cambio, los investigadores descubrieron que los modelos entrenados con un conjunto de datos deduplicados eran más sólidos y con tasas de olvido más lentas. Por ejemplo, los modelos expuestos a conocimiento parafraseado mostraron un mayor grado de generalización, lo que significa que podían aplicar el conocimiento de manera más flexible en diferentes contextos.
Otro hallazgo clave fue la relación entre el tamaño del lote y la retención de conocimientos. Los modelos entrenados con lotes más grandes, como 2048, demostraron una mayor resistencia al olvido que aquellos entrenados con lotes más pequeños de 128. El estudio también descubrió una relación de ley de potencia entre los pasos de entrenamiento y el olvido, lo que demuestra que el conocimiento fáctico se degrada más rápidamente en los modelos. entrenado con datos duplicados. Por otro lado, los modelos expuestos a un mayor volumen de hechos únicos retuvieron este conocimiento por más tiempo, lo que subraya la importancia de la calidad del conjunto de datos sobre la mera cantidad. Por ejemplo, la constante de caída para los datos duplicados en la última etapa de preentrenamiento fue 0,21, en comparación con 0,16 para los datos parafraseados, lo que indica un olvido más lento cuando se deduplicó el conjunto de datos.
La investigación ofrece un enfoque prometedor para abordar los problemas del olvido y la mala generalización en los LLM. Los hallazgos sugieren que optimizar el tamaño del lote y la deduplicación durante la fase previa a la capacitación puede mejorar significativamente la retención del conocimiento fáctico en los LLM. Estas mejoras pueden hacer que los modelos sean más confiables en una gama más amplia de tareas, especialmente cuando se trata de conocimientos menos comunes o de cola larga. En última instancia, este estudio proporciona una comprensión más clara de los mecanismos detrás de la adquisición de conocimientos en los LLM, abriendo nuevas vías para futuras investigaciones para perfeccionar los métodos de capacitación y mejorar aún más las capacidades de estos poderosos modelos.
Esta investigación ha proporcionado información valiosa sobre cómo los grandes modelos lingüísticos adquieren y retienen conocimientos. Al identificar factores como el tamaño del modelo, el tamaño del lote y la calidad del conjunto de datos, el estudio ofrece soluciones prácticas para mejorar el rendimiento del LLM. Estos hallazgos resaltan la importancia de técnicas de capacitación eficientes y subrayan el potencial de optimizar los LLM para que sean aún más efectivos en el manejo de tareas lingüísticas complejas y diversas.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. No olvides unirte a nuestro SubReddit de más de 50.000 ml
Suscríbase al boletín de ML de más rápido crecimiento con más de 26.000 suscriptores.
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.