MIO: un nuevo modelo básico multimodal basado en tokens para la comprensión y generación autorregresiva de extremo a extremo de voz, texto, imágenes y videos

Los modelos multimodales tienen como objetivo crear sistemas que puedan integrarse y utilizar perfectamente múltiples modalidades para proporcionar una comprensión integral de los datos proporcionados. Dichos sistemas tienen como objetivo replicar la percepción y la cognición similares a las humanas mediante el procesamiento de interacciones multimodales complejas. Al aprovechar estas capacidades, los modelos multimodales están allanando el camino para sistemas de IA más sofisticados que pueden realizar diversas tareas, como respuesta visual a preguntas, generación de voz y narración interactiva.
A pesar de los avances en los modelos multimodales, aún es necesario revisar los enfoques actuales. Muchos modelos existentes no pueden procesar y generar datos en diferentes modalidades o centrarse únicamente en uno o dos tipos de entrada, como texto e imágenes. Esto conduce a un alcance de aplicación limitado y un rendimiento reducido al manejar escenarios complejos del mundo real que requieren integración entre múltiples modalidades. Además, la mayoría de los modelos no pueden crear contenido entrelazado (combinando texto con elementos visuales o de audio), lo que dificulta su versatilidad y utilidad en aplicaciones prácticas. Abordar estos desafíos es esencial para desbloquear el verdadero potencial de los modelos multimodales y permitir el desarrollo de sistemas de IA robustos capaces de comprender el mundo e interactuar con él de manera más integral.
Los métodos actuales en la investigación multimodal generalmente se basan en codificadores y módulos de alineación separados para procesar diferentes tipos de datos. Por ejemplo, modelos como EVA-CLIP y CLAP utilizan codificadores para extraer características de imágenes y alinearlas con representaciones de texto a través de módulos externos como Q-Former. Otros enfoques incluyen modelos como SEED-LLaMA y AnyGPT, que se centran en combinar texto e imágenes pero no admiten interacciones multimodales integrales. Si bien GPT-4o ha logrado avances en el soporte de entradas y salidas de datos de cualquier tipo, es de código cerrado y carece de capacidades para generar secuencias entrelazadas que involucren más de dos modalidades. Estas limitaciones han llevado a los investigadores a explorar nuevas arquitecturas y metodologías de formación que puedan unificar la comprensión y la generación en diversos formatos.
El equipo de investigación de la Universidad de Beihang, AIWaves, la Universidad Politécnica de Hong Kong, la Universidad de Alberta y varios institutos de renombre, en un esfuerzo de colaboración, han introducido un modelo novedoso llamado MIO (entrada y salida multimodal), diseñado para superar los modelos existentes. limitaciones. MIO es un modelo básico multimodal de código abierto capaz de procesar texto, voz, imágenes y videos en un marco unificado. El modelo admite la generación de secuencias entrelazadas que involucran múltiples modalidades, lo que lo convierte en una herramienta versátil para interacciones multimodales complejas. A través de un proceso integral de capacitación de cuatro etapas, MIO alinea tokens discretos en cuatro modalidades y aprende a generar resultados multimodales coherentes. Las empresas que desarrollan este modelo incluyen MAP y AIWaves, que han contribuido significativamente al avance de la investigación de IA multimodal.

El proceso de capacitación único de MIO consta de cuatro etapas para optimizar su comprensión multimodal y sus capacidades de generación. La primera etapa, el entrenamiento previo de alineación, garantiza que las representaciones de datos no textuales del modelo estén alineadas con su espacio lingüístico. A esto le sigue un entrenamiento previo entrelazado, que incorpora diversos tipos de datos, incluidos datos entrelazados de video-texto e imagen-texto, para mejorar la comprensión contextual del modelo. La tercera etapa, el preentrenamiento mejorado del habla, se centra en mejorar las capacidades relacionadas con el habla manteniendo al mismo tiempo un rendimiento equilibrado en otras modalidades. Finalmente, la cuarta etapa implica un ajuste supervisado utilizando una variedad de tareas multimodales, incluida la narración visual y el razonamiento en cadena de pensamiento visual. Este riguroso enfoque de capacitación permite a MIO comprender en profundidad los datos multimodales y generar contenido entrelazado que combina a la perfección texto, voz e información visual.
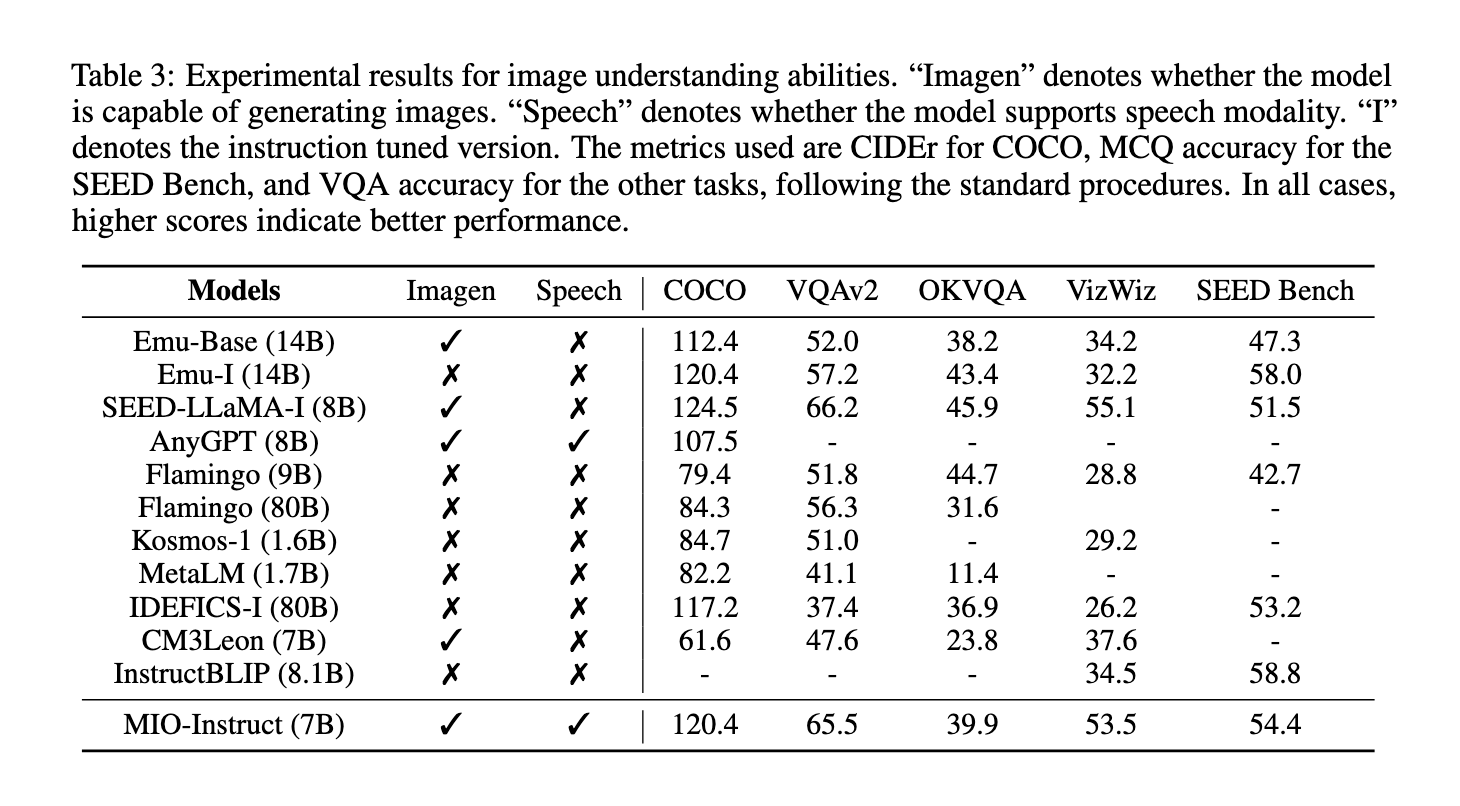
Los resultados experimentales muestran que MIO logra un rendimiento de vanguardia en varios puntos de referencia, superando a los modelos multimodales duales y cualquiera a cualquier existentes. En tareas visuales de respuesta a preguntas, MIO alcanzó una precisión del 65,5 % en VQAv2 y del 39,9 % en OK-VQA, superando a otros modelos como Emu-14B y SEED-LLaMA. En evaluaciones relacionadas con el habla, MIO demostró capacidades superiores, logrando una tasa de error de palabras (WER) del 4,2 % en reconocimiento automático de voz (ASR) y del 10,3 % en tareas de texto a voz (TTS). El modelo también se destacó en tareas de comprensión de videos, con una precisión superior del 42,6 % en MSVDQA y del 35,5 % en MSRVTT-QA. Estos resultados resaltan la solidez y eficiencia de MIO en el manejo de interacciones multimodales complejas, incluso en comparación con modelos más grandes como IDEFICS-80B. Además, el desempeño de MIO en la generación de video-texto entrelazado y el razonamiento en cadena de pensamiento visual muestra sus habilidades únicas para generar resultados multimodales coherentes y contextualmente relevantes.

En general, MIO presenta un avance significativo en el desarrollo de modelos básicos multimodales, proporcionando una solución sólida y eficiente para integrar y generar contenido a través de texto, voz, imágenes y videos. Su proceso de formación integral y su rendimiento superior en varios puntos de referencia demuestran su potencial para establecer nuevos estándares en la investigación de IA multimodal. La colaboración entre la Universidad de Beihang, AIWaves, la Universidad Politécnica de Hong Kong y muchos otros institutos de renombre ha dado como resultado una poderosa herramienta que cierra la brecha entre la comprensión y la generación multimodal, allanando el camino para futuras innovaciones en inteligencia artificial.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Quiere estar frente a más de 1 millón de lectores de IA? Trabaja con nosotros aquí
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.