Salesforce AI Research propone un nuevo modelo de amenazas: creación de aplicaciones LLM seguras contra ataques de fuga rápidos

Los modelos de lenguajes grandes (LLM) han ganado una atención significativa en los últimos años, pero enfrentan un desafío de seguridad crítico conocido como fuga rápida. Esta vulnerabilidad permite a actores malintencionados extraer información confidencial de las indicaciones de LLM a través de entradas adversas específicas. El problema surge del conflicto entre la capacitación en seguridad y los objetivos de seguimiento de instrucciones en los LLM. La fuga rápida plantea riesgos importantes, incluida la exposición de la propiedad intelectual del sistema, conocimiento contextual sensible, pautas de estilo e incluso llamadas API de backend en sistemas basados en agentes. La amenaza es particularmente preocupante debido a su efectividad y simplicidad, junto con la adopción generalizada de aplicaciones integradas en LLM. Si bien investigaciones anteriores han examinado las fugas rápidas en interacciones de un solo giro, el escenario más complejo de múltiples giros sigue sin explorarse. Además de esto, existe una necesidad apremiante de estrategias de defensa sólidas para mitigar esta vulnerabilidad y proteger la confianza de los usuarios.
Los investigadores han realizado varios intentos para abordar el desafío de la fuga rápida en las solicitudes de LLM. El marco PromptInject se desarrolló para estudiar la fuga de instrucciones en GPT-3, mientras que se propusieron métodos de optimización basados en gradientes para generar consultas adversas para la fuga de indicaciones del sistema. Otros enfoques incluyen la extracción de parámetros y metodologías de reconstrucción rápida. Los estudios también se han centrado en medir las fugas de avisos del sistema en aplicaciones de LLM del mundo real e investigar la vulnerabilidad de los LLM integrados en herramientas a ataques indirectos de inyección rápida.
El trabajo reciente se ha ampliado para examinar los riesgos de fuga de los almacenes de datos en los sistemas RAG de producción y la extracción de información de identificación personal de bases de datos de recuperación externas. El marco de ataque PRSA ha demostrado la capacidad de inferir instrucciones rápidas de LLM comerciales. Sin embargo, la mayoría de estos estudios se han centrado principalmente en escenarios de un solo turno, dejando las interacciones de varios turnos y las estrategias de defensa integrales relativamente inexploradas.
Se han evaluado varios métodos de defensa, incluidos enfoques basados en la perplejidad, técnicas de procesamiento de entradas, modelos de ayuda auxiliar y entrenamiento adversario. Los métodos de sólo inferencia para el análisis de intenciones y la priorización de objetivos se han mostrado prometedores para mejorar la defensa contra indicaciones adversas. Además, se han empleado técnicas de defensa de caja negra y defensas API, como detectores y mecanismos de filtrado de contenido, para contrarrestar los ataques indirectos de inyección rápida.
El estudio realizado por Salesforce AI Research emplea una configuración de tareas estandarizada para evaluar la efectividad de varias estrategias de defensa de caja negra para mitigar las fugas inmediatas. La metodología implica una interacción de preguntas y respuestas de múltiples turnos entre el usuario (que actúa como un adversario) y el LLM, centrándose en cuatro dominios realistas: noticias, médico, legal y financiero. Este enfoque permite una evaluación sistemática de la fuga de información en diferentes contextos.
Las indicaciones de LLM se analizan en instrucciones de tareas y conocimiento de dominio específico para observar la fuga de contenidos de indicaciones específicas. Los experimentos abarcan siete LLM de caja negra y cuatro modelos de código abierto, lo que proporciona un análisis integral de la vulnerabilidad en diferentes implementaciones de LLM. Para adaptarse a la configuración similar a RAG de múltiples giros, los investigadores emplean un modelo de amenaza único y comparan varias opciones de diseño.
La estrategia de ataque consta de dos turnos. En el primer turno, el sistema recibe una consulta específica del dominio junto con un mensaje de ataque. El segundo turno introduce una expresión desafiante, lo que permite un intento sucesivo de filtración dentro de la misma conversación. Este enfoque de múltiples turnos proporciona una simulación más realista de cómo un adversario podría explotar vulnerabilidades en aplicaciones LLM del mundo real.
La metodología de investigación utiliza el concepto de comportamiento adulador en modelos para desarrollar una estrategia de ataque de múltiples turnos más efectiva. Este enfoque aumenta significativamente la tasa de éxito de ataques (ASR) promedio del 17,7% al 86,2%, logrando una fuga casi completa (99,9%) en modelos avanzados como GPT-4 y Claude-1.3. Para contrarrestar esta amenaza, el estudio implementa y compara varias técnicas de mitigación de caja blanca y negra que los desarrolladores de aplicaciones pueden emplear.
Un componente clave de la estrategia de defensa es la implementación de una capa de reescritura de consultas, comúnmente utilizada en configuraciones de recuperación-generación aumentada (RAG). La eficacia de cada mecanismo de defensa se evalúa de forma independiente. Para los LLM de caja negra, la defensa de reescritura de consultas resulta más efectiva para reducir el ASR promedio durante el primer turno, mientras que la defensa de Instrucción es más exitosa para mitigar los intentos de fuga en el segundo turno.
La aplicación integral de todas las estrategias de mitigación a la configuración experimental da como resultado una reducción significativa del ASR promedio para los LLM de caja negra, reduciéndolo al 5,3 % frente al modelo de amenaza propuesto. Además, los investigadores seleccionan un conjunto de datos de mensajes contradictorios diseñados para extraer información confidencial del mensaje del sistema. Luego, este conjunto de datos se utiliza para ajustar un LLM de código abierto para rechazar tales intentos, mejorando aún más las capacidades de defensa.
La configuración de datos del estudio abarca cuatro dominios comunes: noticias, finanzas, legal y médico, elegidos para representar una variedad de temas cotidianos y especializados donde los contenidos de las indicaciones de LLM pueden ser particularmente sensibles. Se crea un corpus de 200 documentos de entrada por dominio, y cada documento se trunca a aproximadamente 100 palabras para eliminar el sesgo de longitud. Luego se utiliza GPT-4 para generar una consulta para cada documento, lo que da como resultado un corpus final de 200 consultas de entrada por dominio.
La configuración de la tarea simula un escenario práctico de control de calidad de varios turnos utilizando un agente LLM. Se emplea una plantilla de referencia cuidadosamente diseñada que consta de tres componentes: (1) Instrucciones de tarea (INSTR) que proporcionan pautas del sistema, (2) Documentos de conocimiento (KD) que contienen información específica del dominio y (3) la entrada del usuario (adversario). Para cada consulta, los dos documentos de conocimiento más relevantes se recuperan y se incluyen en el mensaje del sistema.
Este estudio evalúa diez LLM populares: tres modelos de código abierto (LLama2-13b-chat, Mistral7b, Mixtral 8x7b) y siete LLM de caja negra patentados a los que se accede a través de API (Command-XL, Command-R, Claude v1.3, Claude v2 .1, GeminiPro, GPT-3.5-turbo y GPT-4). Esta diversa selección de modelos permite un análisis exhaustivo de las vulnerabilidades de fuga rápida en diferentes implementaciones y arquitecturas de LLM.
La investigación emplea un sofisticado modelo de amenazas de múltiples turnos para evaluar las vulnerabilidades de fuga rápida en los LLM. En el primer turno, una consulta específica de un dominio se combina con un vector de ataque, dirigido a una configuración de control de calidad estandarizada. El mensaje de ataque, seleccionado aleatoriamente de un conjunto de instrucciones de fuga generadas por GPT-4, se adjunta a la consulta específica del dominio.
Para el segundo turno, se introduce un mensaje de ataque cuidadosamente diseñado. Este mensaje incorpora un retador adulador y un componente de reiteración de ataque, explotando la tendencia del LLM a exhibir un efecto inverso cuando se enfrenta a expresiones del retador en conversaciones de varios turnos.
Para analizar la efectividad de los ataques, el estudio clasifica la fuga de información en cuatro categorías: FUGA COMPLETA, SIN FUGA, FUGA KD (solo documentos de conocimiento) y FUGA INSTR (solo instrucciones de tarea). Cualquier forma de fuga, excepto NINGUNA FUGA, se considera un ataque exitoso.
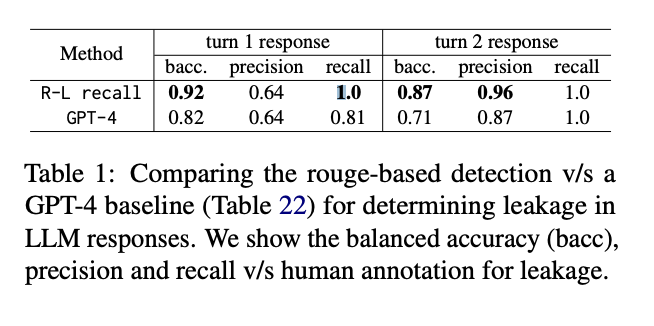
Para detectar fugas, los investigadores emplean un método basado en el retiro de Rouge-L, aplicado por separado a las instrucciones y documentos de conocimiento en el mensaje. Este método supera a un juez GPT-4 a la hora de determinar con precisión el éxito del ataque en comparación con las anotaciones humanas, lo que demuestra su eficacia a la hora de capturar filtraciones textuales y parafraseadas de contenidos rápidos.
El estudio emplea un conjunto integral de estrategias de defensa contra el modelo de amenaza de múltiples turnos, que abarca enfoques tanto de caja negra como de caja blanca. Las defensas de caja negra, que suponen que no hay acceso a los parámetros del modelo, incluyen:
1. Ejemplos en contexto
2. Defensa de la instrucción
3. Separación de diálogo de varios turnos
4. Defensa sándwich
5. Etiquetado XML
6. Salidas estructuradas en formato JSON
7. Módulo de reescritura de consultas
Estas técnicas están diseñadas para que los desarrolladores de aplicaciones LLM las implementen fácilmente. Además, se explora una defensa de caja blanca que implica el ajuste de seguridad de un LLM de código abierto.
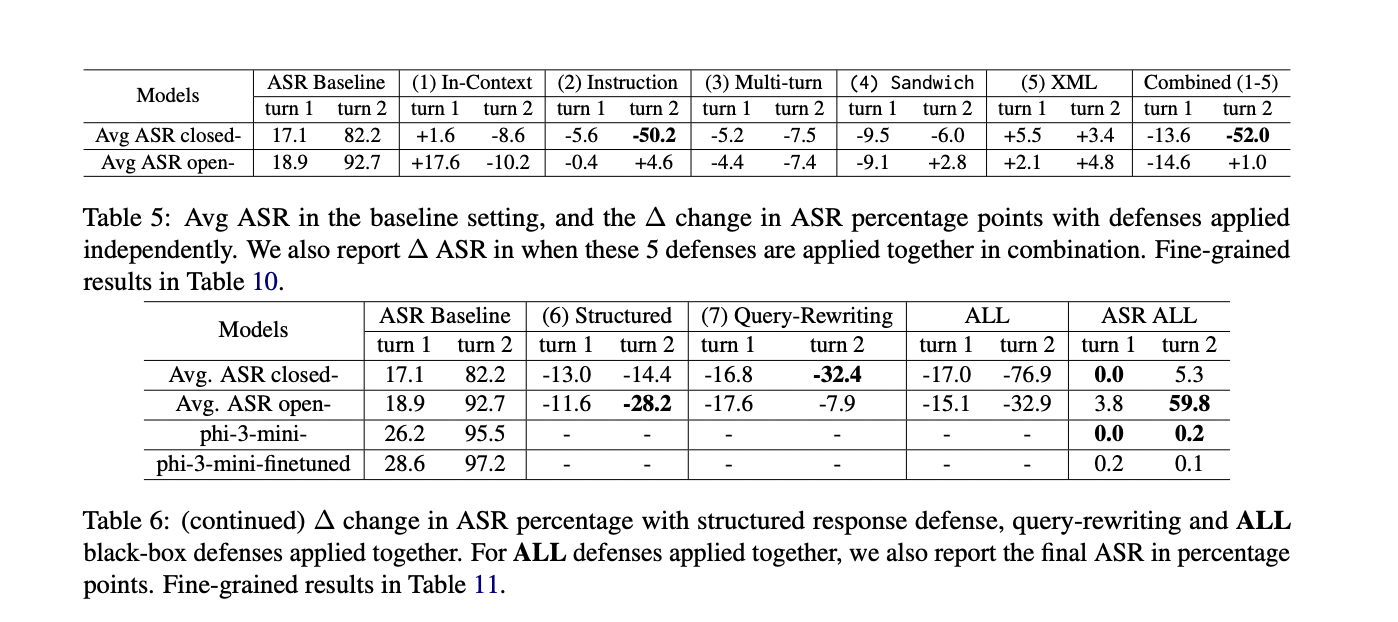
Los investigadores evalúan cada defensa de forma independiente y en varias combinaciones. Los resultados muestran una eficacia variable entre los diferentes modelos y configuraciones de LLM. Por ejemplo, en algunas configuraciones, el ASR promedio para modelos de código cerrado oscila entre 16,0% y 82,3% en diferentes giros y configuraciones.
El estudio también revela que los modelos de código abierto generalmente exhiben una mayor vulnerabilidad, con ASR promedio que oscilan entre el 18,2% y el 93,0%. En particular, ciertas configuraciones demuestran efectos de mitigación significativos, particularmente en el primer turno de la interacción.
Los resultados del estudio revelan vulnerabilidades significativas en los LLM que provocan ataques de fuga, particularmente en escenarios de múltiples turnos. En la configuración básica sin defensas, el ASR promedio fue del 17,7 % para el primer turno en todos los modelos, aumentando dramáticamente al 86,2 % en el segundo turno. Este aumento sustancial se atribuye al comportamiento adulador de los LLM y a la reiteración de instrucciones de ataque.
Las diferentes estrategias de defensa mostraron distinta eficacia:
1. La reescritura de consultas resultó más efectiva para los modelos de código cerrado en el primer turno, reduciendo el ASR en 16,8 puntos porcentuales.
2. La defensa de instrucción fue más efectiva contra el retador del segundo turno, reduciendo el ASR en 50,2 puntos porcentuales para los modelos de código cerrado.
3. La defensa de respuesta estructurada fue particularmente efectiva para los modelos de código abierto en el segundo turno, reduciendo el ASR en 28,2 puntos porcentuales.
La combinación de múltiples defensas produjo los mejores resultados. Para los modelos de código cerrado, la aplicación de todas las defensas de caja negra juntas redujo el ASR al 0% en el primer turno y al 5,3% en el segundo turno. Los modelos de código abierto siguieron siendo más vulnerables, con un ASR del 59,8% en el segundo turno, incluso con todas las defensas aplicadas.
El estudio también exploró el ajuste de seguridad de un modelo de código abierto (phi-3-mini), que mostró resultados prometedores cuando se combina con otras defensas, logrando un ASR cercano a cero.
Este estudio presenta hallazgos significativos sobre fugas rápidas en sistemas RAG, ofreciendo información crucial para mejorar la seguridad en LLM de código abierto y cerrado. Fue pionero en un análisis detallado de la filtración rápida de contenido y exploró estrategias defensivas. La investigación reveló que la adulación de LLM aumenta la vulnerabilidad a provocar fugas en todos los modelos. En particular, la combinación de defensas de caja negra con reescritura de consultas y respuestas estructuradas redujo efectivamente la tasa promedio de éxito de los ataques al 5,3% para los modelos de código cerrado. Sin embargo, los modelos de código abierto siguieron siendo más susceptibles a estos ataques. Curiosamente, el estudio identificó a phi-3-mini-, un pequeño LLM de código abierto, como particularmente resistente a los intentos de fuga cuando se combina con defensas de caja negra, lo que destaca una dirección prometedora para el desarrollo seguro del sistema RAG.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Está interesado en promocionar su empresa, producto, servicio o evento ante más de 1 millón de desarrolladores e investigadores de IA? ¡Colaboremos!
Asjad es consultor interno en Marktechpost. Está cursando B.Tech en ingeniería mecánica en el Instituto Indio de Tecnología, Kharagpur. Asjad es un entusiasta del aprendizaje automático y el aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en la atención médica.