EMOVA: un novedoso LLM omnimodal para la integración perfecta de la visión, el lenguaje y el habla

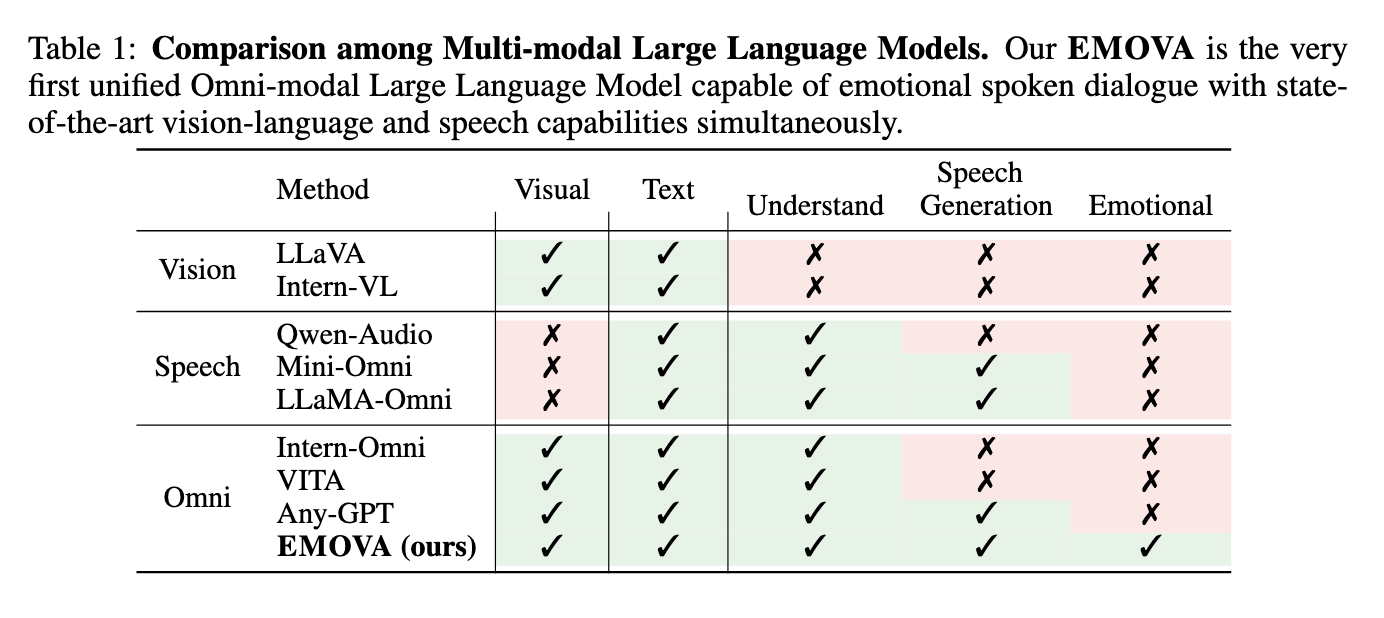
Los modelos de lenguaje grande (LLM) omnimodales están a la vanguardia de la investigación en inteligencia artificial y buscan unificar múltiples modalidades de datos, como la visión, el lenguaje y el habla. El objetivo principal es mejorar las capacidades interactivas de estos modelos, permitiéndoles percibir, comprender y generar resultados a través de diversas entradas, tal como lo haría un ser humano. Estos avances son fundamentales para crear sistemas de IA más completos para participar en interacciones naturales, responder a señales visuales, interpretar instrucciones vocales y proporcionar respuestas coherentes en formatos de texto y voz. Semejante hazaña implica diseñar modelos para gestionar tareas cognitivas de alto nivel integrando al mismo tiempo información sensorial y textual.
A pesar del progreso en modalidades individuales, los modelos de IA existentes necesitan ayuda para integrar las capacidades de visión y habla en un marco unificado. Los modelos actuales se centran en visión-lenguaje o en habla-lenguaje, y a menudo no logran lograr una comprensión perfecta de principio a fin de las tres modalidades simultáneamente. Esta limitación dificulta su aplicación en escenarios que demanden interacciones en tiempo real, como asistentes virtuales o robots autónomos. Además, los modelos de voz actuales dependen en gran medida de herramientas externas para generar salidas vocales, lo que introduce latencia y restringe la flexibilidad en el control del estilo del habla. El desafío sigue siendo diseñar un modelo que pueda superar estas barreras manteniendo un alto rendimiento en la comprensión y generación de contenido multimodal.
Se han adoptado varios enfoques para mejorar los modelos multimodales. Los modelos de lenguaje visual como LLaVA e Intern-VL emplean codificadores de visión para extraer e integrar características visuales con datos textuales. Los modelos de habla-lenguaje, como Whisper, utilizan codificadores de voz para extraer características continuas, lo que permite que el modelo comprenda las entradas vocales. Sin embargo, estos modelos están limitados por su dependencia de herramientas externas de texto a voz (TTS) para generar respuestas de voz. Este enfoque limita la capacidad del modelo para generar voz en tiempo real y con una variación emocional. Además, los intentos de modelos omnimodales, como AnyGPT, se basan en datos discretizados, lo que a menudo resulta en pérdida de información, especialmente en modalidades visuales, lo que reduce la efectividad del modelo en tareas visuales de alta resolución.
Investigadores de la Universidad de Ciencia y Tecnología de Hong Kong, la Universidad de Hong Kong, el Laboratorio Arca de Noé de Huawei, la Universidad China de Hong Kong, la Universidad Sun Yat-sen y la Universidad de Ciencia y Tecnología del Sur han presentado EMOVA (Asistente de voz emocionalmente omnipresente). ). Este modelo representa un avance significativo en la investigación de LLM al integrar perfectamente las capacidades de visión, lenguaje y habla. La arquitectura única de EMOVA incorpora un codificador de visión continua y un tokenizador de voz a unidad, lo que permite al modelo realizar un procesamiento de extremo a extremo de entradas visuales y de voz. Al emplear un tokenizador de voz desenredado semántico-acústico, EMOVA desacopla el contenido semántico (lo que se dice) del estilo acústico (cómo se dice), lo que le permite generar un discurso con varios tonos emocionales. Esta característica es crucial para los sistemas de diálogo hablado en tiempo real, donde la capacidad de expresar emociones a través del habla agrega profundidad a las interacciones.
El modelo EMOVA comprende múltiples componentes diseñados para manejar modalidades específicas de manera efectiva. El codificador de visión captura características visuales de alta resolución y las proyecta en el espacio de inserción del texto, mientras que el codificador de voz transforma la voz en unidades discretas que el LLM puede procesar. Un aspecto crítico del modelo es el mecanismo de desenmarañamiento semántico-acústico, que separa el significado del contenido hablado de sus atributos de estilo, como el tono o el tono emocional. Esto permite a los investigadores introducir un módulo de estilo liviano para controlar la salida del habla, lo que hace que EMOVA sea capaz de expresar diversas emociones y estilos de habla personalizados. Además, la integración de la modalidad de texto como puente para alinear datos de imagen y voz elimina la necesidad de conjuntos de datos omnimodales especializados, que a menudo son difíciles de obtener.
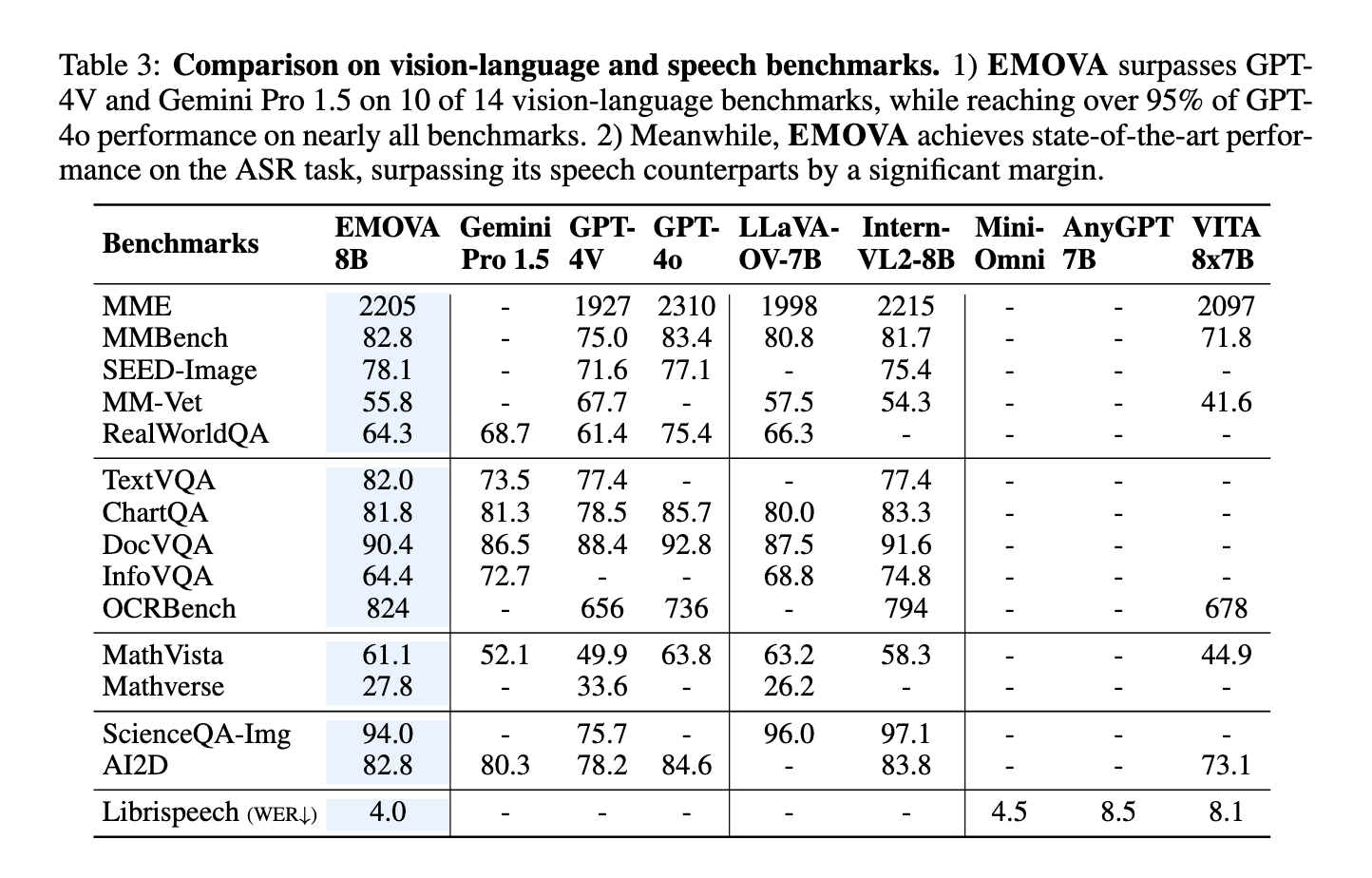
El rendimiento de EMOVA ha sido evaluado en múltiples puntos de referencia, lo que demuestra sus capacidades superiores en comparación con los modelos existentes. En tareas de habla y lenguaje, EMOVA logró una notable precisión del 97 %, superando a otros modelos de última generación como AnyGPT y Mini-Omni por un margen del 2,8 %. En tareas de visión y lenguaje, EMOVA obtuvo una puntuación del 96 % en el conjunto de datos de MathVision, superando a modelos de la competencia como Intern-VL y LLaVA en un 3,5 %. Además, la capacidad del modelo para mantener una alta precisión en tareas de habla y visión simultáneamente no tiene precedentes, ya que la mayoría de los modelos existentes suelen sobresalir en una modalidad a expensas de la otra. Este desempeño integral convierte a EMOVA en el primer LLM capaz de respaldar diálogos hablados en tiempo real y emocionalmente ricos, al tiempo que logra resultados de vanguardia en múltiples dominios.
En resumen, EMOVA aborda una brecha crítica en la integración de capacidades de visión, lenguaje y habla dentro de un único modelo de IA. A través de su innovador desenredo semántico-acústico y su eficiente estrategia de alineación omnimodal, no solo funciona excepcionalmente bien en los puntos de referencia estándar, sino que también introduce flexibilidad en el control emocional del habla, lo que la convierte en una herramienta versátil para interacciones avanzadas de IA. Este avance allana el camino para una mayor investigación y desarrollo en modelos de lenguajes grandes omnimodales, estableciendo un nuevo estándar para futuros avances en este campo.
Mira el Papel y Proyecto. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Está interesado en promocionar su empresa, producto, servicio o evento ante más de 1 millón de desarrolladores e investigadores de IA? ¡Colaboremos!
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.