Transformador diferencial: una arquitectura básica para modelos de lenguaje grandes que reduce el ruido de atención y logra ganancias significativas en eficiencia y precisión

La arquitectura Transformer ha permitido que los modelos de lenguajes grandes (LLM) realicen tareas complejas de generación y comprensión del lenguaje natural. En el núcleo de Transformer hay un mecanismo de atención diseñado para asignar importancia a varios tokens dentro de una secuencia. Sin embargo, este mecanismo distribuye la atención de manera desigual, a menudo asignando atención a contextos irrelevantes. Este fenómeno, conocido como “ruido de atención”, dificulta la capacidad del modelo para identificar y utilizar con precisión información clave de secuencias largas. Se vuelve especialmente problemático en aplicaciones como respuesta a preguntas, resúmenes y aprendizaje en contexto, donde una comprensión clara y precisa del contexto es fundamental.
Uno de los principales desafíos que enfrentan los investigadores es garantizar que estos modelos puedan identificar y centrarse correctamente en los segmentos más relevantes del texto sin distraerse con el contexto circundante. Este problema se vuelve más pronunciado al ampliar los modelos con respecto al tamaño y los tokens de entrenamiento. El ruido de la atención dificulta la recuperación de información clave y conduce a problemas como alucinaciones, donde los modelos generan información objetivamente incorrecta o no siguen una coherencia lógica. A medida que los modelos crecen, estos problemas se vuelven más difíciles de abordar, lo que hace crucial desarrollar nuevos métodos para eliminar o minimizar el ruido de atención.
Los métodos anteriores para abordar el ruido de la atención incluían modificaciones en la arquitectura, el régimen de entrenamiento o las estrategias de normalización. Sin embargo, estas soluciones a menudo tienen desventajas en cuanto a una mayor complejidad o una reducción de la eficiencia del modelo. Por ejemplo, algunas técnicas se basan en mecanismos de atención dinámica que ajustan el enfoque según el contexto, pero tienen dificultades para mantener un rendimiento constante en escenarios de contexto prolongado. Otros incorporan estrategias de normalización avanzadas, pero añaden complejidad y sobrecarga computacional. Como resultado, los investigadores han estado buscando formas más simples pero efectivas de mejorar el rendimiento de los LLM sin comprometer la escalabilidad o la eficiencia.
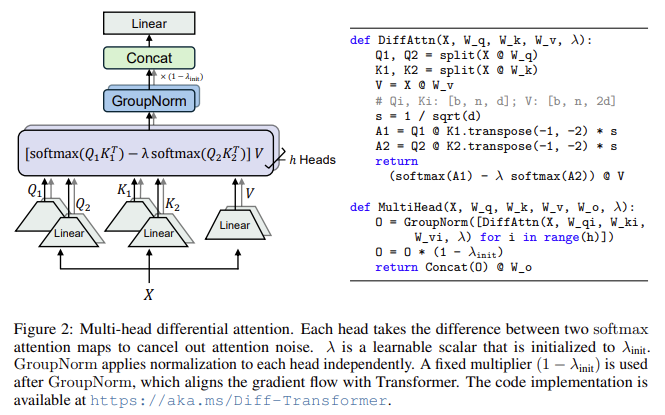
Los investigadores de Microsoft Research y la Universidad de Tsinghua han introducido una nueva arquitectura llamada Transformador diferencial (Transformador DIFF). Esta novedosa arquitectura aborda el problema del ruido de la atención mediante la introducción de un mecanismo de atención diferencial que filtra eficazmente el contexto irrelevante al tiempo que amplifica la atención a segmentos significativos. El mecanismo de atención diferencial opera dividiendo la consulta y los vectores clave en dos grupos y calculando dos mapas de atención softmax separados. La diferencia entre estos mapas sirve como puntuación de atención final, cancelando el ruido de modo común y permitiendo que el modelo gire con mayor precisión sobre la información deseada. Este enfoque está inspirado en conceptos de la ingeniería eléctrica, como los amplificadores diferenciales, donde el ruido común se cancela tomando la diferencia entre dos señales.
El transformador DIFF consta de varias capas que contienen un módulo de atención diferencial y una red de retroalimentación. Conserva la macroestructura del Transformer original, lo que garantiza la compatibilidad con las arquitecturas existentes al tiempo que introduce innovaciones a nivel micro. El modelo incorpora mejoras como pre-RMSNorm y SwiGLU, tomadas de la arquitectura LLaMA, que contribuyen a mejorar la estabilidad y la eficiencia durante el entrenamiento.
El transformador DIFF supera a los transformadores tradicionales en varias áreas clave. Por ejemplo, logra un rendimiento de modelado de lenguaje comparable utilizando solo el 65 % del tamaño del modelo y los tokens de entrenamiento requeridos por los Transformers convencionales. Esto se traduce en una reducción del 38 % en la cantidad de parámetros y una disminución del 36 % en la cantidad de tokens de capacitación necesarios, lo que resulta directamente en un modelo más eficiente en el uso de recursos. Cuando se amplía, un transformador DIFF con 7,8 mil millones de parámetros logra una pérdida de modelado de lenguaje similar a un transformador de 13,1 mil millones de parámetros, igualando así el rendimiento y utilizando un 59,5% menos de parámetros. Esto demuestra la escalabilidad del transformador DIFF, lo que permite un manejo eficaz de tareas de PNL a gran escala con costos computacionales significativamente más bajos.
En una serie de pruebas, DIFF Transformer demostró una capacidad notable para la recuperación de información clave, superando al Transformer tradicional hasta en un 76 % en tareas en las que la información clave estaba integrada en la primera mitad de un contexto largo. En un experimento “Needle-In-A-Haystack”, donde se colocaron respuestas relevantes en diferentes posiciones dentro de contextos de hasta 64.000 tokens, el transformador DIFF mantuvo constantemente una alta precisión, incluso cuando había distractores presentes. En comparación, el Transformer tradicional experimentó una disminución constante en la precisión a medida que aumentaba la longitud del contexto, lo que destaca la capacidad superior del Transformer DIFF para mantener el enfoque en el contenido relevante.
El transformador DIFF redujo significativamente las tasas de alucinaciones en comparación con los modelos convencionales. En una evaluación detallada utilizando conjuntos de datos de respuesta a preguntas como Qasper, HotpotQA y 2WikiMultihopQA, DIFF Transformer logró una precisión un 13 % mayor en la respuesta a preguntas de un solo documento y una mejora del 21 % en la respuesta a preguntas de varios documentos. Logró una ganancia promedio de precisión del 19% en tareas de resúmenes de texto, reduciendo efectivamente la generación de resúmenes engañosos o incorrectos. Estos resultados subrayan la solidez del transformador DIFF en diversas aplicaciones de PNL.
El mecanismo de atención diferencial también mejora la estabilidad del transformador DIFF cuando se trata de permutaciones de orden de contexto. Al mismo tiempo, los transformadores tradicionales exhiben una gran variación en el rendimiento cuando cambia el orden del contexto. El transformador DIFF mostró una fluctuación mínima en el rendimiento, lo que indica una mayor solidez a la sensibilidad de los pedidos. En una evaluación comparativa, la desviación estándar de la precisión del transformador DIFF en permutaciones de orden múltiple fue inferior al 2 %, mientras que la variación del transformador tradicional fue superior al 10 %. Esta estabilidad hace que DIFF Transformer sea particularmente adecuado para aplicaciones que involucran aprendizaje en contexto, donde la capacidad del modelo para utilizar información de un contexto cambiante es crucial.


En conclusión, DIFF Transformer presenta un enfoque innovador para abordar el ruido de la atención en modelos de lenguaje grandes. Al implementar un mecanismo de atención diferencial, el modelo puede lograr una precisión y solidez superiores con menos recursos, posicionándolo como una solución prometedora para la investigación académica y aplicaciones del mundo real.
Mira el Papel y Implementación de código. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 50.000 ml
(Próximo evento: 17 de octubre de 202) RetrieveX: la conferencia de recuperación de datos GenAI (promovida)
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como empresario e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
(Próximo evento: 17 de octubre de 202) RetrieveX: la conferencia de recuperación de datos de GenAI: únase a más de 300 ejecutivos de GenAI de Bayer, Microsoft, Flagship Pioneering, para aprender cómo crear una búsqueda de IA rápida y precisa en el almacenamiento de objetos. (Promovido)