UniMTS: un procedimiento unificado de preentrenamiento para series temporales de movimiento que se generaliza a través de diversos factores y actividades latentes de dispositivos

Reconocimiento del movimiento humano. El uso de series temporales de dispositivos móviles y portátiles se utiliza comúnmente como información de contexto clave para diversas aplicaciones, desde el monitoreo del estado de salud hasta el análisis de la actividad deportiva y los estudios de hábitos de los usuarios. Sin embargo, la recopilación de datos de series temporales de movimiento a gran escala sigue siendo un desafío debido a seguridad o privacidad preocupaciones. En el dominio de las series temporales de movimiento, la falta de conjuntos de datos y de una tarea de preentrenamiento efectiva dificulta el desarrollo de modelos similares que puedan operar con datos limitados. Por lo general, los modelos existentes realizan entrenamiento y pruebas en el mismo conjunto de datos, y tienen dificultades para generalizar entre diferentes conjuntos de datos debido a tres desafíos únicos dentro del dominio del problema de las series temporales de movimiento: Primerocolocar dispositivos en diferentes lugares del cuerpo (como en la muñeca o en la pierna) genera datos muy diferentes, lo que dificulta el uso de un modelo entrenado para un lugar en otra parte. Segundodado que los dispositivos se pueden sostener en varias orientaciones, es problemático porque los modelos entrenados con un dispositivo en una posición a menudo tienen dificultades cuando el dispositivo se sostiene de manera diferente. Por últimodiferentes conjuntos de datos a menudo se centran en diferentes tipos de actividades, lo que dificulta comparar o combinar los datos de manera efectiva.
La clasificación convencional de series de tiempo de movimiento se basa en clasificadores separados para cada conjunto de datos, utilizando métodos como la extracción estadística de características, CNN, RNNy modelos de atención. Modelos de uso general como TimesNet y COMPARTIR apuntan a la versatilidad de las tareas, pero requieren capacitación o pruebas en el mismo conjunto de datos; por tanto, limitan la adaptabilidad. El aprendizaje autosupervisado ayuda en el aprendizaje de la representación, aunque la generalización entre varios conjuntos de datos sigue siendo un desafío. Modelos previamente entrenados como Enlace de imagen y IMU2CLIP considere datos de movimiento y texto, pero están limitados por el entrenamiento específico del dispositivo. Los métodos que utilizan modelos de lenguaje grandes (LLM) se basan en indicaciones, pero tienen dificultades para reconocer actividades complejas, ya que no están entrenados en series de tiempo de movimiento sin procesar y tienen dificultades para reconocer con precisión actividades complejas.
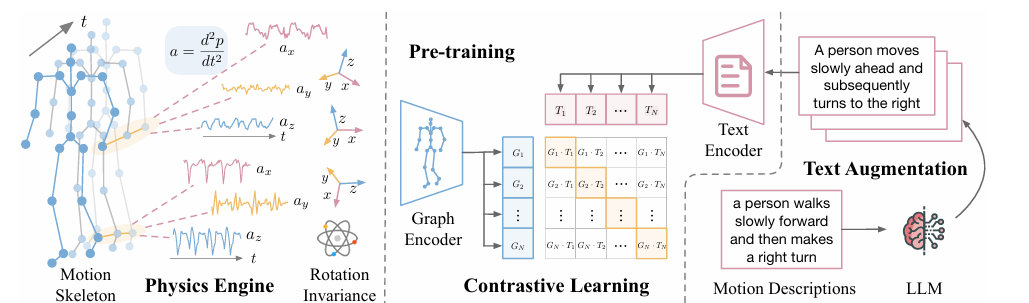
Un grupo de investigadores de Universidad de California en San Diego, Amazonas, y Qualcomm propuesto UniMTS como el primer procedimiento unificado de preentrenamiento para series temporales de movimiento que se generaliza a través de diversos factores y actividades latentes del dispositivo. UniMTS utiliza un marco de aprendizaje contrastivo para vincular datos de series temporales de movimiento con descripciones de texto enriquecido de modelos de lenguaje grandes (LLM). Esto ayuda al modelo a comprender el significado detrás de los diferentes movimientos y le permite generalizar entre diversas actividades. Para el preentrenamiento a gran escala, UniMTS genera datos de series de tiempo de movimiento basados en datos detallados del esqueleto existentes, que cubren varias partes del cuerpo. Luego, los datos generados se procesan utilizando redes de gráficos para capturar relaciones espaciales y temporales en diferentes ubicaciones de dispositivos, lo que ayuda al modelo a generalizarse a datos de diferentes ubicaciones de dispositivos.
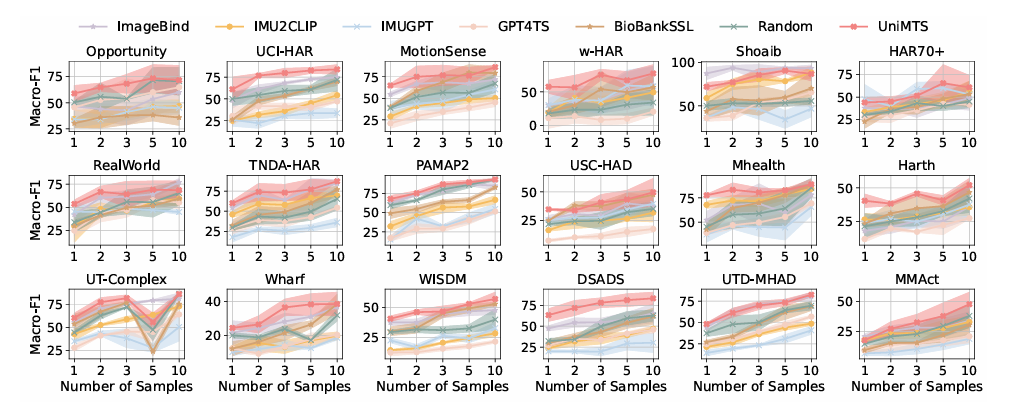
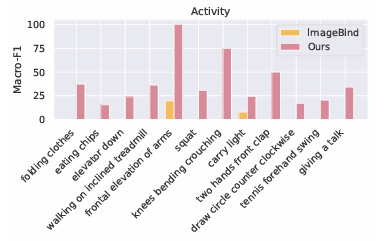
El proceso comienza creando datos de movimiento a partir de los movimientos del esqueleto y ajustándolos según diferentes orientaciones. También utiliza un codificador gráfico para comprender cómo se conectan las uniones para que pueda funcionar bien en diferentes dispositivos. Las descripciones de texto se mejoran utilizando modelos de lenguaje grandes. Para crear datos de movimiento, calcula las velocidades y aceleraciones de cada articulación mientras considera sus posiciones y orientaciones, agregando ruido para imitar los errores de los sensores del mundo real. Para manejar las inconsistencias en la orientación del dispositivo, UniMTS utiliza el aumento de datos para crear orientaciones aleatorias durante el entrenamiento previo. Este método tiene en cuenta las variaciones en las posiciones del dispositivo y la configuración de los ejes. Al alinear los datos de movimiento con descripciones de texto, el modelo puede adaptarse bien a diferentes orientaciones y tipos de actividad. Para la capacitación, UniMTS emplea un aumento de datos invariante en rotación para manejar las diferencias de posicionamiento del dispositivo. Fue probado en el HumanoML3D conjunto de datos y 18 otros conjuntos de datos de referencia de series temporales de movimiento del mundo real, en particular con una mejora del rendimiento de 340% en la configuración de disparo cero, 16,3% en la configuración de pocos disparos, y 9,2% en la configuración de tiro completo, en comparación con las respectivas líneas de base de mejor rendimiento. El rendimiento del modelo se comparó con líneas de base como Enlace de imagen y IMU2CLIP. Los resultados mostraron que UniMTS superó a otros modelos, especialmente en entornos de disparo cero, según pruebas estadísticas que confirmaron mejoras significativas.
En conclusión, el modelo preentrenado propuesto. UniMTS se basa únicamente en datos simulados por física, pero muestra una generalización notable en diversos conjuntos de datos de series temporales de movimiento del mundo real que presentan diferentes ubicaciones, orientaciones y actividades de dispositivos. Si bien aprovecha el rendimiento de los métodos tradicionales, UniMTS también posee algunas limitaciones. En un sentido más amplio, este modelo de clasificación de series temporales de movimiento previamente entrenado puede actuar como una base potencial para la próxima investigación en el campo del reconocimiento del movimiento humano.
Mira el Papel, GitHuby Modelo en abrazando la cara. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(Oportunidad de Patrocinio con nosotros) Promocione su investigación/producto/seminario web con más de 1 millón de lectores mensuales y más de 500.000 miembros de la comunidad
Divyesh es pasante de consultoría en Marktechpost. Está cursando un BTech en Ingeniería Agrícola y Alimentaria en el Instituto Indio de Tecnología de Kharagpur. Es un entusiasta de la ciencia de datos y el aprendizaje automático que quiere integrar estas tecnologías líderes en el ámbito agrícola y resolver desafíos.
Escuche nuestros últimos podcasts de IA y vídeos de investigación de IA aquí ➡️