SelfCodeAlign: un marco de IA abierto y transparente para la capacitación de LLM de código que supera a los modelos más grandes sin costos de destilación o anotación

La inteligencia artificial ha transformado la generación de código, y los modelos de lenguaje grande (LLM) para código ahora son parte integral de la ingeniería de software. Estos modelos admiten tareas de síntesis, depuración y optimización de código mediante el análisis de amplias bases de código. Sin embargo, el desarrollo de estos LLM centrados en código enfrenta desafíos importantes. La capacitación requiere datos de seguimiento de instrucciones de alta calidad, generalmente recopilados mediante anotaciones humanas que requieren mucha mano de obra o aprovechando el conocimiento de modelos propietarios más grandes. Si bien estos enfoques mejoran el rendimiento del modelo, introducen problemas relacionados con la accesibilidad, las licencias y los costos de los datos. A medida que crece la demanda de métodos transparentes, eficientes y escalables para entrenar estos modelos, las soluciones innovadoras que superan estos desafíos sin sacrificar el rendimiento se vuelven cruciales.
La destilación de conocimiento de modelos propietarios puede violar las restricciones de licencia, limitando su uso en proyectos de código abierto. Una limitación importante es que los datos seleccionados por humanos, aunque valiosos, son costosos y difíciles de escalar. Algunos métodos de código abierto, como OctoCoder y OSS-Instruct, han intentado superar estas limitaciones. Sin embargo, a menudo necesitan más puntos de referencia de desempeño y requisitos de transparencia. Estas limitaciones subrayan la necesidad de una solución que mantenga un alto rendimiento y se alinee con los valores y la transparencia del código abierto.
Investigadores de la Universidad de Illinois Urbana-Champaign, la Universidad Northeastern, la Universidad de California Berkeley, ServiceNow Research, Hugging Face, Roblox y Cursor AI introdujeron un enfoque novedoso llamado Alineación de código propio. Este enfoque permite a los LLM capacitarse de forma independiente, generando pares instrucción-respuesta de alta calidad sin intervención humana ni datos de modelos propietarios. A diferencia de otros modelos que se basan en anotaciones humanas o transferencia de conocimiento desde modelos grandes, SelfCodeAlign genera instrucciones de forma autónoma extrayendo diversos conceptos de codificación a partir de datos iniciales. Luego, el modelo utiliza estos conceptos para crear tareas únicas y produce múltiples respuestas. Estas respuestas se combinan con casos de prueba automatizados y se validan en un entorno de pruebas controlado. Solo las respuestas que se aprueban se utilizan para el ajuste final de la instrucción, lo que garantiza que los datos sean precisos y diversos.
La metodología de SelfCodeAlign comienza extrayendo fragmentos de código semilla de un gran corpus, centrándose en la diversidad y la calidad. El conjunto de datos inicial, “The Stack V1”, se filtra para seleccionar 250.000 funciones Python de alta calidad de un conjunto de 5 millones, mediante estrictos controles de calidad. Después de elegir estos fragmentos, el modelo los divide en conceptos de codificación fundamentales, como conversión de tipos de datos o coincidencia de patrones. Luego genera tareas y respuestas basadas en estos conceptos, asignando niveles de dificultad y categorías para garantizar la variedad. Este enfoque de varios pasos garantiza datos de alta calidad y minimiza los sesgos, lo que hace que el modelo se adapte a diversos desafíos de codificación.
La eficacia de SelfCodeAlign se probó rigurosamente con el modelo CodeQwen1.5-7B. Comparado con modelos como CodeLlama-70B, SelfCodeAlign superó muchas soluciones de última generación, logrando una puntuación HumanEval+ pass@1 del 67,1%, 16,5 puntos más que su modelo base, CodeQwen1.5-7B-OctoPack. El modelo funcionó consistentemente bien en varias tareas, incluida la generación de funciones y clases, programación de ciencia de datos y edición de código, lo que demuestra que SelfCodeAlign mejora el rendimiento en diferentes tamaños de modelos, desde parámetros 3B hasta 33B. En tareas de generación a nivel de clase, SelfCodeAlign logró una tasa de aprobación@1 del 27 % a nivel de clase y del 52,6 % a nivel de método, superando a muchos modelos propietarios optimizados con instrucciones. Estos resultados resaltan el potencial de SelfCodeAlign para producir modelos que no solo sean efectivos sino también de menor tamaño, lo que aumenta aún más la accesibilidad.
En cuanto a la eficiencia, en el punto de referencia EvalPerf, que evalúa la eficiencia del código, el modelo logró una puntuación de rendimiento diferencial (DPS) del 79,9%. Esto indica que las soluciones generadas por SelfCodeAlign igualaron o superaron la eficiencia del 79,9 % de soluciones comparables en varias pruebas de nivel de eficiencia. Además, SelfCodeAlign logró una tasa de aprobación del 39 % en tareas de edición de código, sobresaliendo en cambios de codificación correctivos, adaptativos y perfectivos. Este desempeño consistente en diversos puntos de referencia enfatiza la efectividad del enfoque de datos autogenerados de SelfCodeAlign.
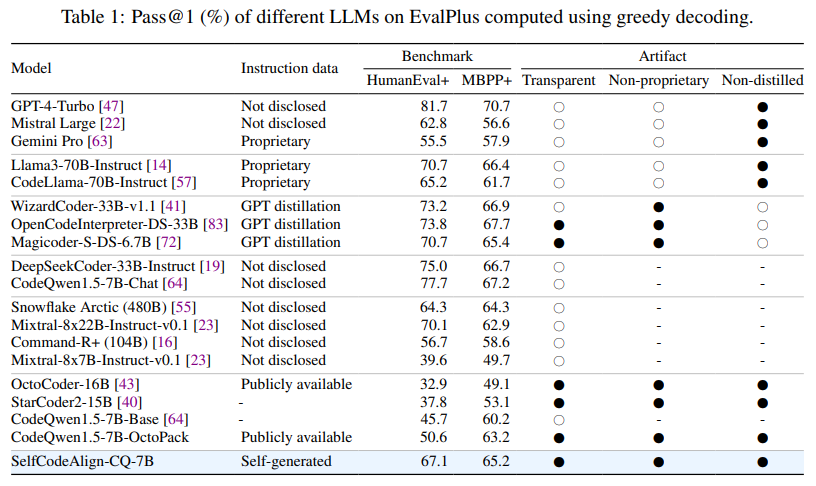
Las principales conclusiones del éxito de SelfCodeAlign son transformadoras para el campo de los LLM de código:
- Transparencia y accesibilidad: SelfCodeAlign es un enfoque totalmente transparente y de código abierto que no requiere datos de modelo patentados, lo que lo hace ideal para investigadores centrados en la IA ética y la reproducibilidad.
- Ganancias de eficiencia: con un DPS del 79,9 % en los puntos de referencia de eficiencia, SelfCodeAlign demuestra que los modelos más pequeños y entrenados de forma independiente pueden lograr resultados impresionantes a la par con modelos propietarios mucho más grandes.
- Versatilidad en todas las tareas: el modelo destaca en varias tareas de codificación, incluidas la síntesis de código, la depuración y las aplicaciones de ciencia de datos, lo que subraya su utilidad para múltiples dominios en la ingeniería de software.
- Beneficios de costos y licencias: la capacidad de SelfCodeAlign para operar sin costosos datos anotados por humanos o destilación LLM patentada lo hace altamente escalable y económicamente viable, abordando las limitaciones comunes en los métodos tradicionales de ajuste de instrucciones.
- Adaptabilidad para investigaciones futuras: el proceso del modelo puede adaptarse a campos más allá de la codificación, lo que resulta prometedor para la adaptación en diferentes dominios técnicos.

En conclusión, SelfCodeAlign proporciona una solución innovadora a los desafíos de entrenar modelos de seguimiento de instrucciones en la generación de código. Al eliminar la necesidad de anotaciones humanas y la dependencia de modelos propietarios, SelfCodeAlign ofrece una alternativa escalable, transparente y de alto rendimiento que podría redefinir cómo se desarrollan los LLM de código. La investigación demuestra que la autoalineación autónoma, sin destilación, puede producir resultados comparables a modelos grandes y costosos, lo que marca un avance significativo en los LLM de código abierto para la generación de código.
Mira el Papel y Página de GitHub. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(Oportunidad de Patrocinio con nosotros) Promocione su investigación/producto/seminario web con más de 1 millón de lectores mensuales y más de 500.000 miembros de la comunidad
A Sana Hassan, pasante de consultoría en Marktechpost y estudiante de doble titulación en IIT Madras, le apasiona aplicar la tecnología y la inteligencia artificial para abordar los desafíos del mundo real. Con un gran interés en resolver problemas prácticos, aporta una nueva perspectiva a la intersección de la IA y las soluciones de la vida real.
Escuche nuestros últimos podcasts de IA y vídeos de investigación de IA aquí ➡️