Investigadores del MIT desarrollaron transformadores heterogéneos preentrenados (HPT): un enfoque de IA escalable para el aprendizaje robótico a partir de datos heterogéneos

En el mundo actual, desarrollar políticas robóticas es difícil. A menudo requiere recopilar datos específicos para cada robot, tarea y entorno, y las políticas aprendidas no se generalizan más allá de estas configuraciones específicas. Los avances recientes en la recopilación de datos a gran escala y de código abierto han hecho posible la capacitación previa sobre datos diversos, de alta calidad y a gran escala. Sin embargo, en robótica, la heterogeneidad plantea un desafío porque los robots difieren en forma física, sensores y entornos operativos. Tanto la propiocepción como la información de la visión son importantes para comportamientos complejos, ricos en contactos y de largo horizonte en robótica. Un aprendizaje deficiente de dicha información puede conducir a comportamientos de sobreajuste, como repetir movimientos para una escena, tarea o incluso trayectoria en particular.
Los métodos actuales de aprendizaje robótico implican recopilar datos de una única realización de robot para una tarea específica y entrenar el modelo sobre ella. Este es un enfoque extenso y la principal limitación es que el modelo no se puede generalizar para diversas tareas y robots. Métodos como la formación previa y el aprendizaje por transferencia utilizan datos de diversos campos, como visión por computadora y lenguaje natural, para ayudar a los modelos a aprender y adaptarse a tareas más nuevas. Trabajos recientes muestran que se pueden usar pequeñas capas de proyección para combinar los espacios de características previamente entrenados de los modelos de base. A diferencia de otros campos, la robótica tiene menos cantidad y diversidad de datos pero mucha más heterogeneidad. Además, los avances recientes combinan datos multimodales (imágenes, lenguaje, audio) para un mejor aprendizaje de representación.
Un grupo de investigadores de MIT CSAIL y Meta realizó una investigación detallada y propuso un marco llamado Transformadores heterogéneos preentrenados (HPT). Es una familia de arquitectura diseñada para aprender de forma escalable a partir de datos en realizaciones heterogéneas. La función principal de HPT es crear una comprensión o representación compartida de tareas que pueden ser utilizadas por diferentes robots en diversas condiciones. En lugar de entrenar a un robot desde cero para cada nueva tarea o entorno, HPT permite que los robots utilicen conocimientos aprendidos previamente, lo que hace que el proceso de capacitación sea más rápido y eficiente. Esta arquitectura combina las entradas de propiocepción y visión de distintas realizaciones en una breve secuencia de tokens, que luego se procesan para controlar robots para diversas tareas.
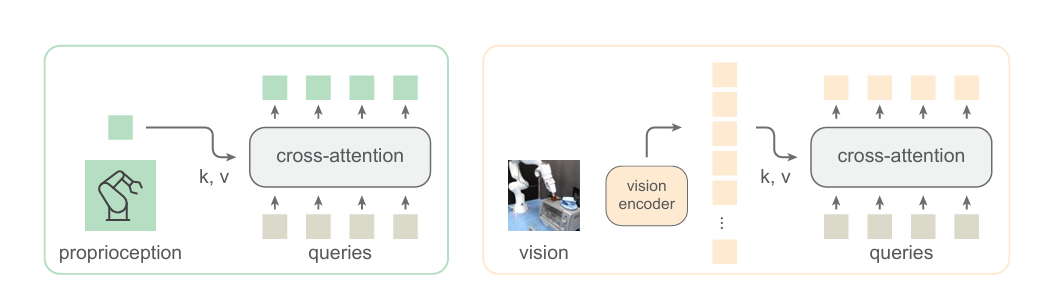
La arquitectura de HPT consta del vástago específico de la realización, el tronco compartido y los cabezales específicos de la tarea. HPT se inspira en el aprendizaje de datos multimodales y utiliza tokenizadores específicos de cada realización, conocidos como provenirpara combinar varias entradas de sensores, como vistas de cámara y datos de movimientos corporales. El trompa es un modelo compartido y previamente entrenado en conjuntos de datos y se transfiere cuando se adapta a nuevas realizaciones y tareas que se desconocen durante los tiempos de entrenamiento previo. Además, utiliza decodificadores de acciones específicas de tareas para producir resultados de acción conocidos como cabezas. Después de tokenizar cada realización, HPT opera en un espacio compartido de una secuencia corta de tokens latentes.
Se investigaron los comportamientos de escalamiento y los diversos diseños de preformación de políticas utilizando más de 50 yofuentes de datos individuales y un tamaño de modelo de más de mil millones parámetros. En el proceso de capacitación previa se incorporaron muchos conjuntos de datos incorporados disponibles en diferentes realizaciones, como robots reales, simulaciones y videos de humanos en Internet. Los resultados mostraron que el marco HPT funciona bien no sólo con costosas operaciones de robots del mundo real sino también con otros tipos de realizaciones. Supera varias líneas de base y mejora el desempeño de las políticas afinadas en más de 20% en tareas invisibles en múltiples puntos de referencia de simuladores y entornos del mundo real.
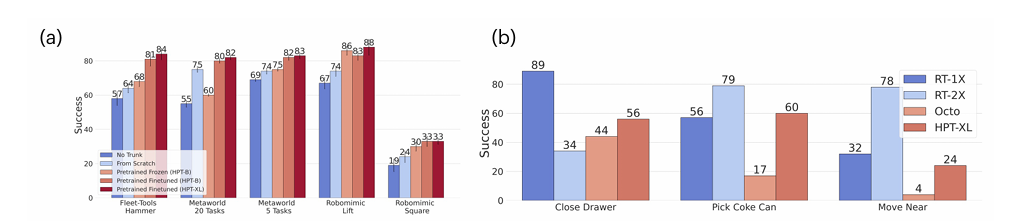
En conclusión, el marco propuesto aborda la heterogeneidad y mitiga los desafíos relacionados con el aprendizaje robótico aprovechando modelos previamente entrenados. El método muestra mejoras significativas en generalización y rendimiento en muchas tareas y realizaciones robóticas. Aunque la arquitectura del modelo y el procedimiento de entrenamiento pueden funcionar con diferentes configuraciones, el entrenamiento previo con datos variados puede tardar más en converger. ¡Esta perspectiva hacia la robótica puede inspirar trabajos futuros en el manejo de la naturaleza heterogénea de los datos robóticos para modelos básicos robóticos!
Mira el Papel, Proyecto, y Blog del MIT. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(Oportunidad de Patrocinio con nosotros) Promocione su investigación/producto/seminario web con más de 1 millón de lectores mensuales y más de 500.000 miembros de la comunidad
Divyesh es pasante de consultoría en Marktechpost. Está cursando un BTech en Ingeniería Agrícola y Alimentaria en el Instituto Indio de Tecnología de Kharagpur. Es un entusiasta de la ciencia de datos y el aprendizaje automático que quiere integrar estas tecnologías líderes en el ámbito agrícola y resolver desafíos.
Escuche nuestros últimos podcasts de IA y vídeos de investigación de IA aquí ➡️