Lograr una separación causal de los datos puramente observacionales sin intervenciones

La separación causal es un campo crítico en el aprendizaje automático que se centra en aislar factores causales latentes de conjuntos de datos complejos, especialmente en escenarios donde la intervención directa no es factible. Esta capacidad de deducir estructuras causales sin intervenciones es particularmente valiosa en campos como la visión por computadora, las ciencias sociales y las ciencias de la vida, ya que permite a los investigadores predecir cómo se comportarían los datos en diversos escenarios hipotéticos. El desenredo causal mejora la interpretabilidad y generalización del aprendizaje automático, lo cual es crucial para aplicaciones que requieren conocimientos predictivos sólidos.
El principal desafío en el desenredo causal es identificar factores causales latentes sin depender de datos intervencionistas, donde los investigadores manipulan cada factor de forma independiente para observar sus efectos. Esta limitación plantea restricciones importantes en escenarios donde las intervenciones podrían ser más prácticas debido a barreras éticas, de costos o logísticas. Por lo tanto, persiste una cuestión persistente: ¿cuánto pueden aprender los investigadores sobre estructuras causales a partir de datos puramente observacionales cuando no es posible un control directo sobre las variables ocultas? Los métodos tradicionales de inferencia causal tienen dificultades en este contexto, ya que a menudo requieren suposiciones o restricciones específicas que pueden aplicarse sólo en ocasiones.
Los métodos existentes suelen depender de datos intervencionistas, suponiendo que los investigadores puedan manipular cada variable de forma independiente para revelar la causalidad. Estos métodos también se basan en supuestos restrictivos como la mezcla lineal o estructuras paramétricas, lo que limita su aplicabilidad a conjuntos de datos que carecen de restricciones predefinidas. Algunas técnicas intentan eludir estas limitaciones utilizando datos de vistas múltiples o imponiendo restricciones estructurales adicionales a las variables latentes. Sin embargo, estos enfoques siguen siendo limitados en escenarios exclusivamente observacionales, ya que deben generalizarse mejor a los casos en los que no se dispone de datos intervencionistas o estructurados.
Investigadores del Broad Institute del MIT y Harvard han introducido un enfoque novedoso para abordar la separación causal utilizando únicamente datos de observación sin asumir un acceso intervencionista ni restricciones estructurales estrictas. Su método utiliza modelos no lineales que incorporan ruido gaussiano aditivo y una función de mezcla lineal desconocida para identificar factores causales. Este enfoque innovador aprovecha las asimetrías dentro de la distribución conjunta de los datos observados para derivar estructuras causales significativas. Al centrarse en las asimetrías distributivas naturales de los datos, este método permite a los investigadores detectar relaciones causales hasta una transformación por capas, lo que marca un importante paso adelante en el aprendizaje de representaciones causales sin intervenciones.
La metodología propuesta combina el emparejamiento de puntuaciones con programación cuadrática para inferir estructuras causales de manera eficiente. Utilizando funciones de puntuación estimadas a partir de datos observados, el enfoque aísla los factores causales mediante una optimización iterativa en un programa cuadrático. La flexibilidad de este método le permite integrar varias herramientas de estimación de puntuación, lo que lo hace adaptable a diferentes conjuntos de datos de observación. Los investigadores ingresan estimaciones de puntuación en los algoritmos 1 y 2 para capturar y refinar las capas causales. Este marco permite que el modelo funcione con cualquier técnica de estimación de puntuación, proporcionando una solución versátil y escalable a problemas complejos de desenredo causal.
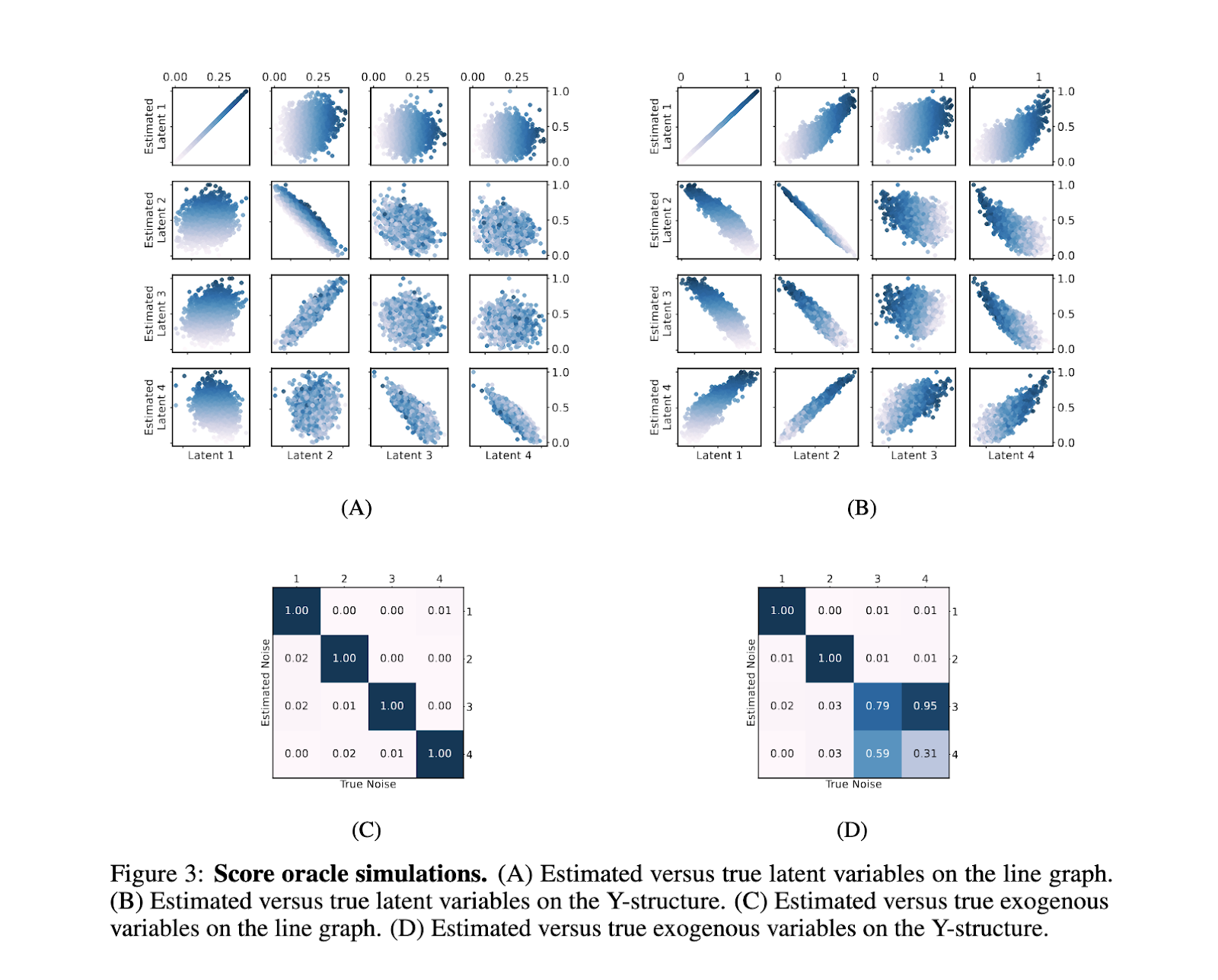
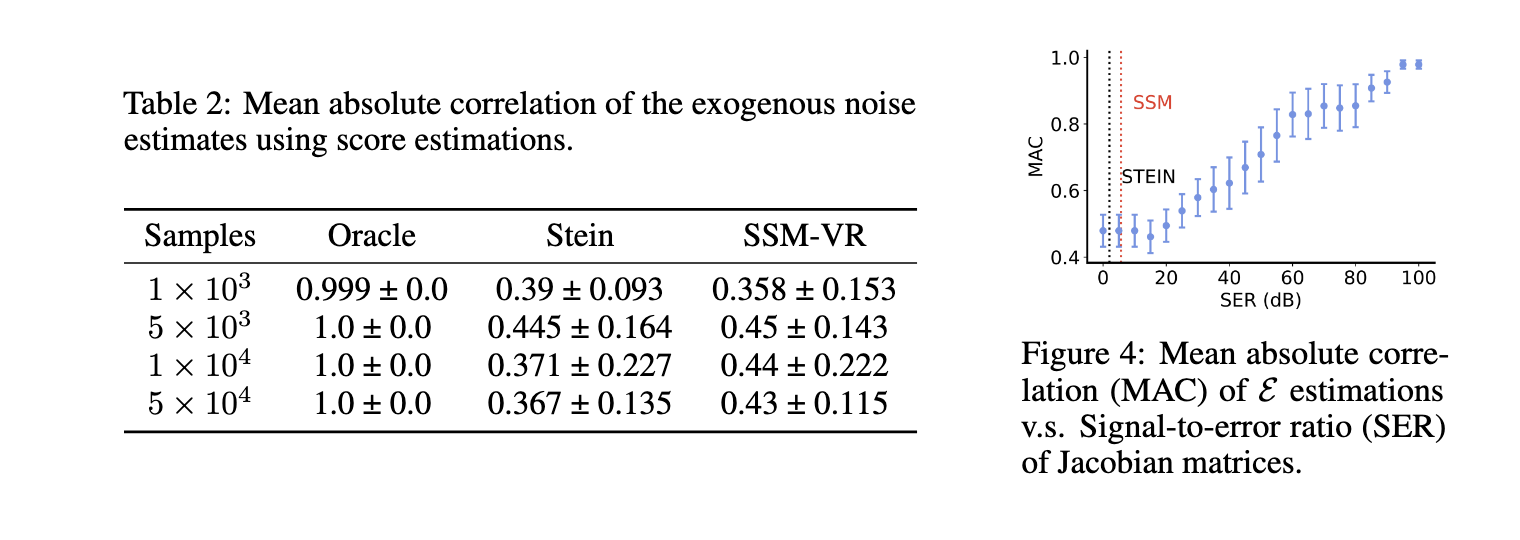
La evaluación cuantitativa del método arrojó resultados prometedores, lo que demuestra su eficacia práctica y fiabilidad. Por ejemplo, utilizando un gráfico causal de cuatro nodos en dos configuraciones (un gráfico lineal y una estructura en Y), los investigadores generaron 2.000 muestras observacionales y calcularon puntuaciones con funciones de enlace de verdad sobre el terreno. En el gráfico de líneas, el algoritmo logró un desenredo perfecto de todas las variables, mientras que en la estructura Y, desenredó con precisión las variables E1 y E2, aunque se produjo cierta mezcla con E3 y E4. Los valores de correlación absoluta media (MAC) entre las variables de ruido verdaderas y estimadas resaltaron la eficacia del modelo para representar con precisión las estructuras causales. El algoritmo mantuvo una alta precisión en pruebas con estimaciones de puntuación ruidosas, validando su solidez frente a condiciones de datos del mundo real. Estos resultados subrayan la capacidad del modelo para aislar estructuras causales en datos observacionales, verificando las predicciones teóricas de la investigación.
Esta investigación marca un avance significativo en el desentrañamiento causal al permitir la identificación de factores causales sin depender de datos intervencionistas. El enfoque aborda el problema persistente de lograr la identificabilidad de los datos de observación, ofreciendo un método flexible y eficiente para la inferencia causal. Este estudio abre nuevas posibilidades para el descubrimiento causal en varios dominios, lo que permite interpretaciones más precisas y profundas en campos donde las intervenciones directas son desafiantes o imposibles. Al mejorar el aprendizaje de la representación causal, la investigación allana el camino para aplicaciones más amplias del aprendizaje automático en campos que requieren un análisis de datos sólido e interpretable.
Mira el Papel y Detalles. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(Próximo evento en vivo de LinkedIn) ‘Una plataforma, posibilidades multimodales’, donde el director ejecutivo de Encord, Eric Landau, y el director de ingeniería de productos, Justin Sharps, hablarán sobre cómo están reinventando el proceso de desarrollo de datos para ayudar a los equipos a construir rápidamente modelos de IA multimodales innovadores.
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.
Escuche nuestros últimos podcasts de IA y vídeos de investigación de IA aquí ➡️