Este documento sobre aprendizaje automático transforma la eficiencia de la IA incorporada: nuevas leyes de escala para optimizar las proporciones de modelos y conjuntos de datos en tareas de clonación de comportamientos y modelado mundial

La inteligencia artificial incorporada (IA) implica la creación de agentes que funcionan dentro de entornos físicos o simulados, ejecutando tareas de forma autónoma en función de objetivos predefinidos. Estos agentes, utilizados a menudo en robótica y simulaciones complejas, aprovechan amplios conjuntos de datos y modelos sofisticados para optimizar el comportamiento y la toma de decisiones. A diferencia de aplicaciones más sencillas, la IA incorporada requiere modelos capaces de gestionar grandes cantidades de datos sensoriomotores y dinámicas interactivas complejas. Como tal, el campo ha priorizado cada vez más el “escalado”, un proceso que ajusta el tamaño del modelo, el volumen del conjunto de datos y la potencia computacional para lograr un desempeño eficiente y eficaz de los agentes en diversas tareas.
El desafío de ampliar los modelos de IA incorporados radica en lograr un equilibrio entre el tamaño del modelo y el volumen del conjunto de datos, un proceso necesario para garantizar que estos agentes puedan operar de manera óptima dentro de las limitaciones de los recursos computacionales. A diferencia de los modelos de lenguaje, donde la escala está bien establecida, aún es necesario explorar la interacción precisa de factores como el tamaño del conjunto de datos, los parámetros del modelo y los costos de cálculo en la IA incorporada. Esta falta de claridad limita la capacidad de los investigadores para construir modelos a gran escala de manera efectiva, ya que aún no está claro cómo distribuir los recursos para tareas que requieren una adaptación óptima al comportamiento y al entorno. Por ejemplo, si bien aumentar el tamaño del modelo mejora el rendimiento, hacerlo sin un aumento proporcional de los datos puede generar ineficiencias o incluso menores rendimientos, especialmente en tareas como la clonación de comportamientos y el modelado mundial.
Los modelos de lenguaje han desarrollado leyes de escala sólidas que describen las relaciones entre el tamaño del modelo, los datos y los requisitos informáticos. Estas leyes permiten a los investigadores hacer predicciones fundamentadas sobre las configuraciones necesarias para un entrenamiento de modelos eficaz. Sin embargo, la IA incorporada no ha adoptado plenamente estos principios, en parte debido a la variada naturaleza de sus tareas. En respuesta, los investigadores han estado trabajando para transferir conocimientos de escalamiento de modelos lingüísticos a la IA incorporada, particularmente mediante la capacitación previa de agentes en grandes conjuntos de datos fuera de línea que capturan diversos datos ambientales y de comportamiento. El objetivo es establecer leyes que ayuden a los agentes encarnados a alcanzar un alto desempeño en la toma de decisiones y en la interacción con su entorno.
Los investigadores de Microsoft Research han desarrollado recientemente leyes de escalamiento específicas para la IA incorporada, introduciendo una metodología que evalúa cómo los cambios en los parámetros del modelo, el tamaño del conjunto de datos y los límites computacionales impactan la eficiencia del aprendizaje de los agentes de IA. El trabajo del equipo se centró en dos tareas principales dentro de la IA incorporada: la clonación de comportamiento, donde los agentes aprenden a replicar las acciones observadas, y el modelado mundial, donde los agentes predicen cambios ambientales basados en acciones y observaciones anteriores. Utilizaron arquitecturas basadas en transformadores y probaron sus modelos en varias configuraciones para comprender cómo las estrategias de tokenización y las tasas de compresión del modelo afectan la eficiencia y precisión generales. Al ajustar sistemáticamente la cantidad de parámetros y tokens, los investigadores observaron distintos patrones de escala que podrían mejorar el rendimiento del modelo y la eficiencia informática.
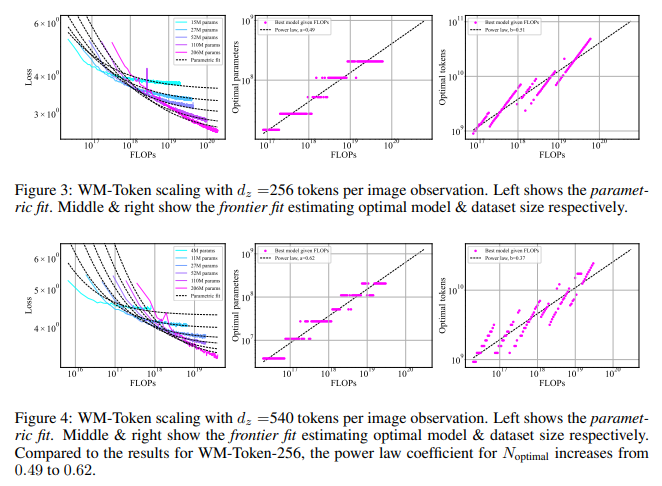
La metodología implicó entrenar transformadores con diferentes enfoques de tokenización para equilibrar el tamaño del modelo y del conjunto de datos. Por ejemplo, el equipo implementó arquitecturas tokenizadas y basadas en CNN en la clonación de comportamiento, lo que permitió que el modelo operara bajo un marco de integración continuo en lugar de tokens discretos, lo que redujo significativamente las demandas computacionales. El estudio encontró que para el modelado mundial, las leyes de escala demostraron que un aumento en el recuento de tokens por observación afectaba el tamaño del modelo, con el coeficiente de tamaño óptimo del modelo aumentando de 0,49 a 0,62 a medida que los tokens aumentaban de 256 a 540 por imagen. Sin embargo, para la clonación de comportamiento con observaciones tokenizadas, los coeficientes de tamaño óptimo del modelo estaban sesgados hacia conjuntos de datos más grandes con modelos más pequeños, lo que muestra una necesidad de un mayor volumen de datos en lugar de parámetros expandidos, una tendencia opuesta a la observada en el modelado mundial.
El estudio presentó hallazgos notables sobre cómo los principios de escalamiento de los modelos de lenguaje podrían aplicarse de manera efectiva a la IA incorporada. La compensación óptima se produjo para el modelado mundial cuando tanto el tamaño del modelo como el del conjunto de datos aumentaron proporcionalmente, coincidiendo con los hallazgos de la literatura sobre escalamiento de LLM. Específicamente, con una configuración de 256 tokens, se logró un equilibrio óptimo al escalar tanto el modelo como el conjunto de datos en proporciones similares. Por el contrario, en la configuración de 540 tokens, el énfasis se desplazó hacia modelos más grandes, lo que hizo que los ajustes de tamaño dependieran en gran medida de la tasa de compresión de las observaciones tokenizadas.
Los resultados clave destacaron que la arquitectura del modelo influye en el equilibrio de escala, particularmente para la clonación de comportamiento. En las tareas en las que los agentes utilizaron observaciones tokenizadas, los coeficientes del modelo indicaron una preferencia por datos extensos sobre modelos de mayor tamaño, con un coeficiente de tamaño óptimo de 0,32 frente a un coeficiente de conjunto de datos de 0,68. En comparación, las tareas de clonación de comportamiento basadas en arquitecturas CNN favorecieron un mayor tamaño del modelo, con un coeficiente de tamaño óptimo de 0,66. Esto demostró que la IA incorporada podría lograr un escalamiento eficiente en condiciones específicas adaptando las proporciones del modelo y del conjunto de datos en función de los requisitos de la tarea.
Para probar la precisión de las leyes de escala derivadas, el equipo de investigación entrenó a un agente de modelado mundial con un tamaño de modelo de 894 millones de parámetros, significativamente mayores que los utilizados en análisis de escala anteriores. El estudio encontró una fuerte alineación entre las predicciones y los resultados reales, con el valor de pérdida coincidiendo estrechamente con los niveles de pérdida óptimos calculados incluso con presupuestos informáticos sustancialmente mayores. Este paso de validación subrayó la confiabilidad de las leyes de escala, lo que sugiere que con un ajuste de hiperparámetros apropiado, las leyes de escala pueden predecir el rendimiento del modelo de manera efectiva en simulaciones complejas y escenarios del mundo real.
Conclusiones clave de la investigación:
- Escalado equilibrado para el modelado mundial: para un rendimiento óptimo en el modelado mundial, tanto el tamaño del modelo como el del conjunto de datos deben aumentar proporcionalmente.
- Optimización de la clonación de comportamiento: las configuraciones óptimas para la clonación de comportamiento favorecen modelos más pequeños combinados con conjuntos de datos extensos cuando se utilizan observaciones tokenizadas. Se prefiere un aumento en el tamaño del modelo para las tareas de clonación basadas en CNN.
- Impacto en la tasa de compresión: Las tasas de compresión de tokens más altas sesgan las leyes de escalamiento hacia modelos más grandes en el modelado mundial, lo que indica que los datos tokenizados afectan sustancialmente los tamaños óptimos de los modelos.
- Validación de extrapolación: las pruebas con modelos más grandes confirmaron la previsibilidad de las leyes de escala, lo que respalda estas leyes como base para un dimensionamiento eficiente del modelo en la IA incorporada.
- Requisitos de tareas distintas: los requisitos de escala varían significativamente entre la clonación de comportamiento y el modelado mundial, lo que resalta la importancia de enfoques de escala personalizados para diferentes tareas de IA.

En conclusión, este estudio avanza la IA incorporada al adaptar los conocimientos de escalamiento del modelo de lenguaje a las tareas de los agentes de IA. Esto permite a los investigadores predecir y controlar las necesidades de recursos con mayor precisión. El establecimiento de estas leyes de escalamiento personalizadas respalda el desarrollo de agentes más eficientes y capaces en entornos que exigen una alta eficiencia computacional y de datos.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(SEMINARIO WEB GRATUITO sobre IA) Implementación del procesamiento inteligente de documentos con GenAI en servicios financieros y transacciones inmobiliarias
A Sana Hassan, pasante de consultoría en Marktechpost y estudiante de doble titulación en IIT Madras, le apasiona aplicar la tecnología y la inteligencia artificial para abordar los desafíos del mundo real. Con un gran interés en resolver problemas prácticos, aporta una nueva perspectiva a la intersección de la IA y las soluciones de la vida real.
🐝🐝 Próximo evento en vivo de LinkedIn, ‘Una plataforma, posibilidades multimodales’, donde el director ejecutivo de Encord, Eric Landau, y el director de ingeniería de productos, Justin Sharps, hablarán sobre cómo están reinventando el proceso de desarrollo de datos para ayudar a los equipos a construir rápidamente modelos de IA multimodales innovadores.