Conozca OpenCoder: un LLM de código fuente completamente abierto basado en el proceso de procesamiento de datos transparente y el conjunto de datos reproducibles

Los modelos de lenguajes grandes (LLM) han revolucionado varios dominios, con un impacto particularmente transformador en el desarrollo de software a través de tareas relacionadas con el código. La aparición de herramientas como ChatGPT, Copilot y Cursor ha cambiado fundamentalmente la forma en que trabajan los desarrolladores, mostrando el potencial de los LLM de código específico. Sin embargo, persiste un desafío importante en el desarrollo de LLM de código abierto, ya que su rendimiento va constantemente por detrás de los modelos de última generación. Esta brecha de rendimiento se debe principalmente a los conjuntos de datos de capacitación patentados que utilizan los principales proveedores de LLM, quienes mantienen un control estricto sobre estos recursos cruciales. La falta de acceso a datos de capacitación de alta calidad crea una barrera sustancial para la comunidad de investigación en general, lo que obstaculiza su capacidad para establecer líneas de base sólidas y desarrollar una comprensión más profunda de cómo funcionan los LLM de código de alto rendimiento.
Los esfuerzos de investigación anteriores en el modelado de lenguajes de código han adoptado varios enfoques para avanzar en las aplicaciones de IA en la ingeniería de software. Los modelos propietarios han demostrado impresionantes mejoras de rendimiento en múltiples pruebas comparativas relacionadas con el código, pero su naturaleza cerrada restringe significativamente una mayor innovación. La comunidad de investigación ha respondido desarrollando alternativas de código abierto como CodeGen, StarCoder, CodeLlama y DeepSeekCoder, que han ayudado a fomentar el avance continuo en este campo. Estos modelos se han evaluado a través de diversos puntos de referencia, incluida la recuperación de código, la traducción, la evaluación de la eficiencia y las tareas de finalización de código a nivel de repositorio. Recientemente, ha habido un impulso significativo hacia los LLM de código abierto, con proyectos como LLaMA, Mistral, Qwen y ChatGLM que lanzan no solo puntos de control de modelos sino también conjuntos de datos de capacitación completos. Particularmente dignas de mención son iniciativas totalmente abiertas como OLMo y StarCoderV2, que proporcionan una amplia documentación de sus procesos de capacitación, canales de datos y puntos de control intermedios, promoviendo la transparencia y la reproducibilidad en el campo.
Investigadores del INF y MAP presentes codificador abierto, una iniciativa sólida diseñada para abordar la brecha de transparencia en los modelos de lenguaje específicos de código a través de tres objetivos principales. El proyecto tiene como objetivo proporcionar a los investigadores un LLM de código de referencia totalmente transparente para estudiar la interpretabilidad mecánica y los patrones de distribución de datos, realizar investigaciones exhaustivas sobre metodologías de curación de datos de instrucción y preentrenamiento y permitir soluciones personalizadas a través de conocimientos detallados sobre el desarrollo de modelos. La investigación revela opciones de diseño cruciales en la curación de datos en diferentes etapas de capacitación, enfatizando la importancia de una limpieza exhaustiva de los datos, estrategias efectivas de deduplicación a nivel de archivos y una consideración cuidadosa de las métricas estrella de GitHub. Un hallazgo significativo indica que los datos de alta calidad se vuelven cada vez más cruciales durante la fase de recocido, mientras que un enfoque de ajuste de instrucciones en dos etapas resulta particularmente efectivo para desarrollar capacidades amplias seguidas de refinamientos específicos del código. Este enfoque integral posiciona a OpenCoder como un LLM de código completamente de código abierto, basado en procesos transparentes y conjuntos de datos reproducibles, destinado a avanzar en el campo de los estudios de inteligencia de código.
Datos previos al entrenamiento
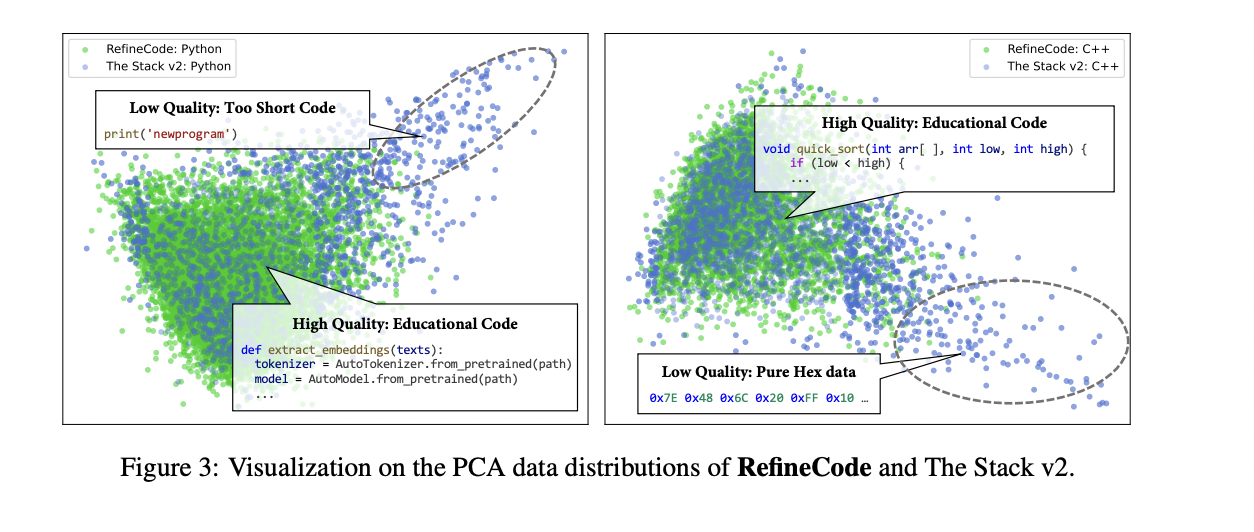
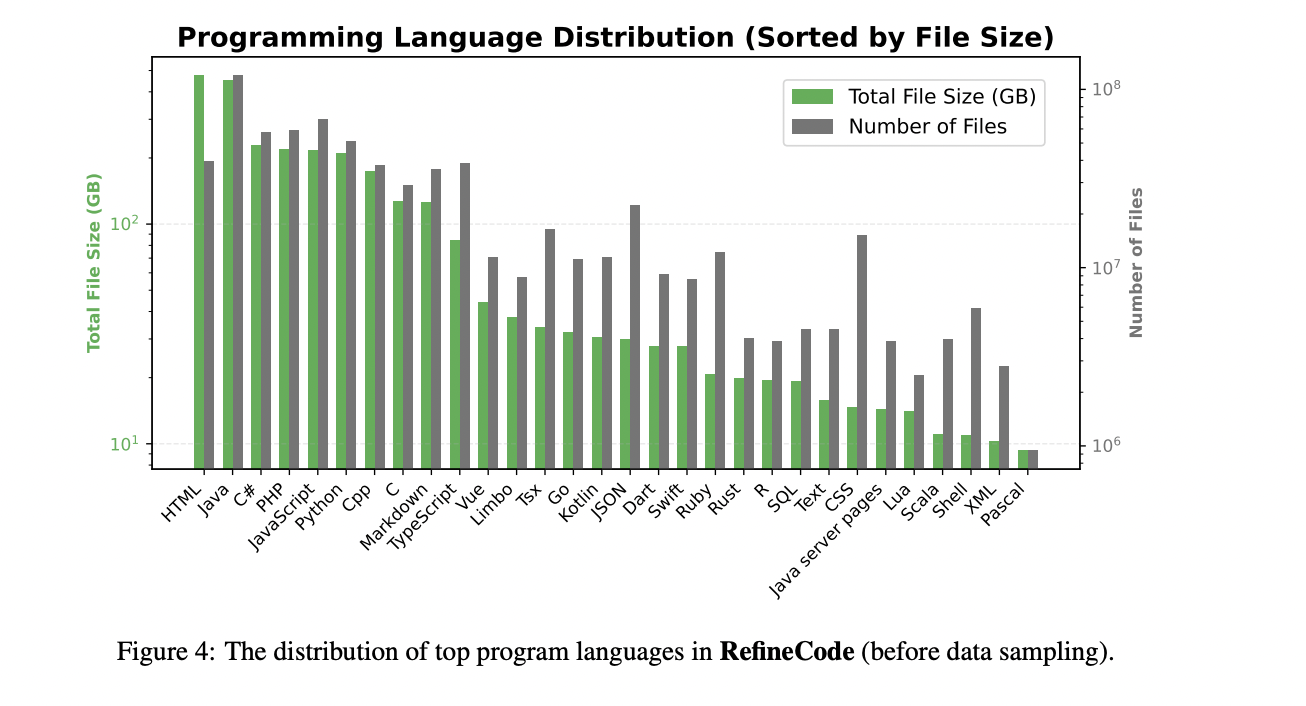
OpenCoder comienza con un sofisticado proceso de procesamiento de datos centrado en RefineCode, un conjunto de datos reproducible y de alta calidad que comprende 960 mil millones de tokens en 607 lenguajes de programación. El proceso de preparación de datos sigue un enfoque meticuloso de cinco pasos para garantizar una calidad y diversidad óptimas. La fase de preprocesamiento inicialmente excluye archivos de más de 8 MB y restringe la selección a extensiones de archivo de lenguaje de programación específicas. El proceso de deduplicación emplea métodos exactos y difusos, utilizando valores hash SHA256 y técnicas LSH para eliminar contenido duplicado y al mismo tiempo preservar archivos con mayor número de estrellas y tiempos de confirmación recientes. La fase de transformación aborda problemas generalizados mediante la eliminación de avisos de derechos de autor y la reducción de la información de identificación personal (PII). La etapa de filtrado implementa tres categorías distintas de reglas: filtrado de lenguaje natural, filtrado de código general y filtrado específico de lenguaje para ocho lenguajes de programación principales. Finalmente, la fase de muestreo de datos mantiene el equilibrio de distribución al reducir la resolución de lenguajes sobrerrepresentados como Java y HTML, lo que en última instancia produce aproximadamente 730 mil millones de tokens para preentrenamiento. El análisis comparativo mediante visualización PCA demuestra que RefineCode logra una distribución de incrustación más concentrada en comparación con conjuntos de datos anteriores, lo que indica mayor calidad y coherencia.


Pre-entrenamiento
La arquitectura OpenCoder abarca dos variantes de modelo: un modelo de 1.500 millones de parámetros y un modelo de 8.000 millones de parámetros. La versión 1.5B presenta 24 capas con 2240 dimensiones ocultas y 14 cabezales de atención, mientras que la versión 8B sigue la arquitectura Llama-3.1-8B con 32 capas, 4096 dimensiones ocultas y 8 cabezales de atención. Ambos modelos utilizan la función de activación SwiGLU y emplean un tamaño de vocabulario de 96.640. El proceso de formación sigue un sofisticado proceso que abarca múltiples fases. Durante el entrenamiento previo, ambos modelos se entrenan en un conjunto de datos multilingüe masivo que incluye chino, inglés y 607 lenguajes de programación. El modelo 1.500 millones procesa 2 billones de tokens en cuatro épocas, seguido de un entrenamiento de recocido en 100 mil millones de tokens adicionales. El modelo 8B se entrena con 2,5 billones de tokens durante 3,5 épocas, con una fase de decadencia posterior que utiliza 100 mil millones de tokens. Ambos modelos emplean el programa de aprendizaje WSD con hiperparámetros cuidadosamente ajustados. La capacitación se lleva a cabo en grandes clústeres de GPU: el modelo 1.5B requiere 28.034 horas de GPU en los H800 y el modelo 8B consume 96.000 horas de GPU en los H100.
Después del entrenamiento
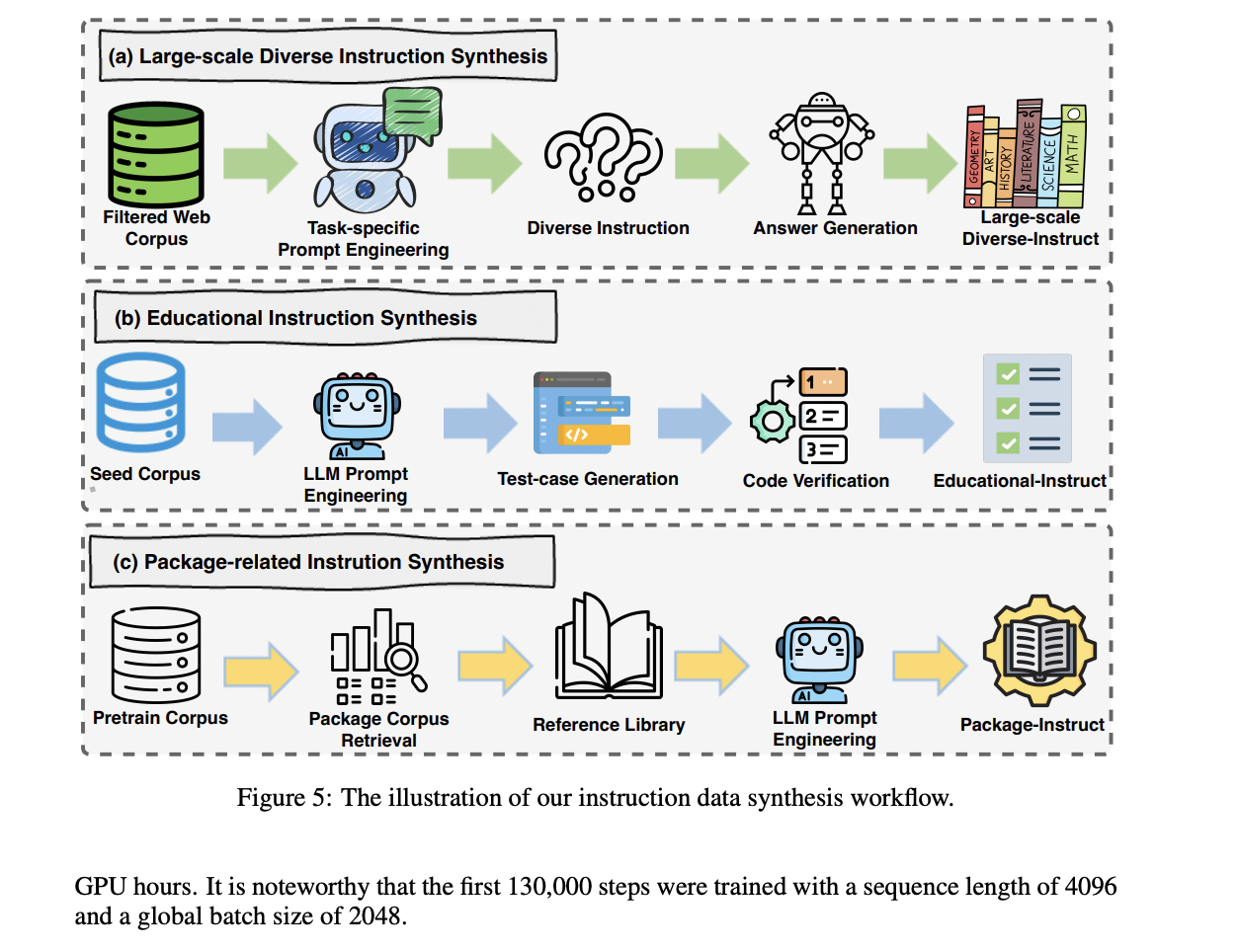
La fase posterior al entrenamiento de OpenCoder implica un enfoque extenso y sofisticado para el ajuste de instrucciones, mediante el uso de múltiples fuentes de datos y métodos de síntesis. El proceso comienza con la recopilación de corpus de instrucción de código abierto de varias fuentes como Evol-Instruct, Infinity-Instruct y McEval, con un cuidadoso muestreo del lenguaje y filtrado basado en LLM para extraer contenido relevante para el código. Las consultas de usuarios reales de WildChat y Code-290k-ShareGpt se incorporan después de una limpieza exhaustiva y una mejora de la calidad mediante la regeneración de LLM. La arquitectura implementa tres enfoques de síntesis de instrucciones especializadas: Síntesis de la instrucción educativa emplea un modelo de puntuación para identificar datos semilla de alta calidad y genera casos de prueba para su validación; La síntesis de instrucciones relacionadas con paquetes aborda el desafío del uso de paquetes obsoletos incorporando documentación actual de bibliotecas populares de Python; y la síntesis de instrucción diversa a gran escala utiliza un marco integral que incluye limpieza de contexto, especificación de tareas, ingeniería rápida y refinamiento de respuestas. Cada componente está diseñado para garantizar que el conjunto de datos de instrucción final sea diverso, práctico y esté alineado con las prácticas de programación actuales.
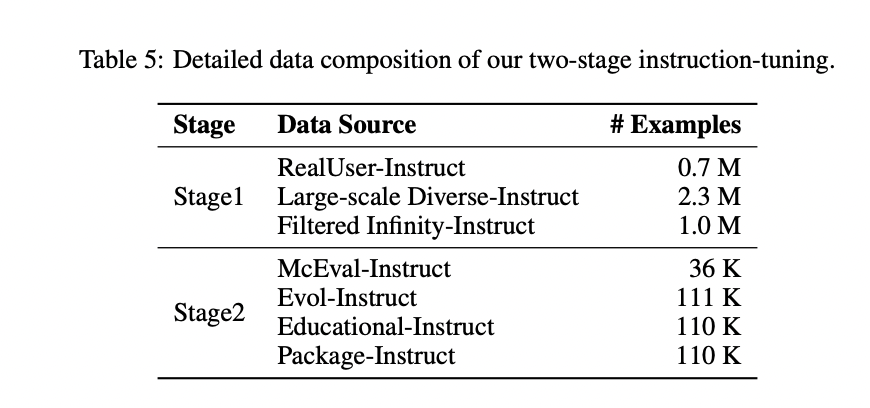
OpenCoder emplea un proceso estratégico de ajuste de instrucciones de dos etapas para desarrollar capacidades integrales tanto en informática teórica como en tareas prácticas de codificación. La primera etapa se centra en el conocimiento teórico, utilizando una combinación de RealUser-Instruct (0,7 millones de ejemplos), Large-scale Diverse-Instruct (2,3 millones de ejemplos) y Filtered Infinity-Instruct (1,0 millones de ejemplos) para construir una base sólida en informática. conceptos científicos como algoritmos, estructuras de datos y principios de redes. La segunda etapa pasa al dominio práctico de la codificación, incorporando McEval-Instruct (36.000 ejemplos), Evol-Instruct (111.000 ejemplos), Educational-Instruct (110.000 ejemplos) y Package-Instruct (110.000 ejemplos). Esta etapa enfatiza la exposición a muestras de código de GitHub de alta calidad, lo que garantiza que el modelo pueda generar código sintáctica y semánticamente correcto mientras mantiene el formato y la estructura adecuados. Este enfoque de doble fase permite a OpenCoder equilibrar la comprensión teórica con las capacidades prácticas de codificación, creando un sistema de generación de código más versátil y eficaz.
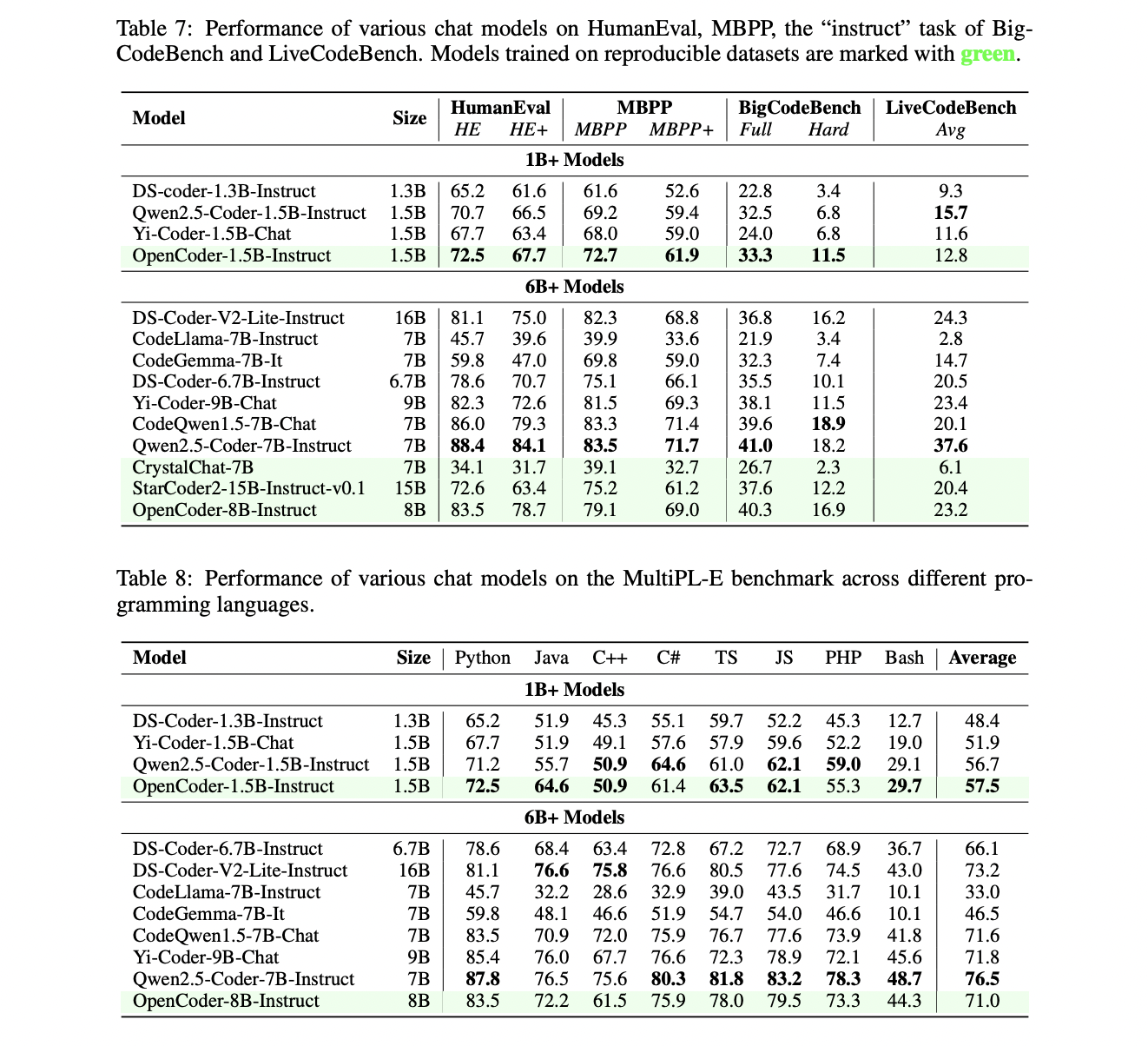
La evaluación de OpenCoder demuestra su rendimiento excepcional en múltiples puntos de referencia, evaluando tanto modelos base como versiones ajustadas a las instrucciones. Los modelos base se evaluaron principalmente en cuanto a las capacidades de finalización de código a través de puntos de referencia establecidos como HumanEval, MBPP (incluidas sus versiones mejoradas HumanEval+ y MBPP+) y BigCodeBench. Estas evaluaciones midieron la competencia del modelo en la comprensión y aplicación de estructuras de datos y algoritmos de Python, y en el manejo de interacciones complejas de bibliotecas.
Los modelos ajustados a las instrucciones se sometieron a pruebas más exhaustivas en cinco puntos de referencia principales. LiveCodeBench evaluó la capacidad del modelo para resolver problemas algorítmicos complejos desde plataformas como Código Leet y Fuerzas del código. MultiPL-E evaluó las capacidades de generación de código en múltiples lenguajes de programación, incluido C++, Java, PHP y TypeScript. McEval evaluó minuciosamente 40 lenguajes de programación con aproximadamente 2000 muestras, donde OpenCoder-8B-Instruct demostró un rendimiento multilingüe superior en comparación con modelos de código abierto de tamaño similar. De manera similar, MdEval probó las capacidades de depuración del modelo en 18 idiomas con 1.2K muestras, mostrando las capacidades efectivas de identificación y corrección de errores de OpenCoder.
Los resultados indican consistentemente que OpenCoder logra un rendimiento de vanguardia entre los modelos de código abierto, sobresaliendo particularmente en la generación de código multilingüe y tareas de depuración. Estas evaluaciones integrales validan la efectividad del enfoque de ajuste de instrucciones en dos etapas de OpenCoder y su sofisticada arquitectura.
código abierto representa un avance significativo en los modelos de lenguaje de código abierto, logrando un rendimiento comparable al de las soluciones propietarias manteniendo una total transparencia. Mediante el lanzamiento de sus materiales de capacitación integrales, que incluyen canales de datos, conjuntos de datos y protocolos detallados, OpenCoder establece un nuevo estándar para la investigación reproducible en código AI. Los extensos estudios de ablación realizados en varias fases de capacitación brindan información valiosa para el desarrollo futuro, lo que convierte a OpenCoder no solo en una herramienta poderosa, sino también en una base para avanzar en el campo de la inteligencia de código.
Mira el Documento, proyecto, página de GitHub y modelos en Hugging Face. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(SEMINARIO WEB GRATUITO sobre IA) Implementación del procesamiento inteligente de documentos con GenAI en servicios financieros y transacciones inmobiliarias
Asjad es consultor interno en Marktechpost. Está cursando B.Tech en ingeniería mecánica en el Instituto Indio de Tecnología, Kharagpur. Asjad es un entusiasta del aprendizaje automático y el aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en la atención médica.
🐝🐝 Próximo evento en vivo de LinkedIn, ‘Una plataforma, posibilidades multimodales’, donde el director ejecutivo de Encord, Eric Landau, y el director de ingeniería de productos, Justin Sharps, hablarán sobre cómo están reinventando el proceso de desarrollo de datos para ayudar a los equipos a construir rápidamente modelos de IA multimodales innovadores.