Salesforce AI Research presenta LaTRO: un marco autorrecompensado para mejorar las capacidades de razonamiento en modelos de lenguaje grandes

Ahora se están entrenando modelos de lenguaje grande (LLM), útiles para responder preguntas y generar contenido, para manejar tareas que requieren razonamiento avanzado, como la resolución de problemas complejos en matemáticas, ciencias y deducción lógica. Mejorar las capacidades de razonamiento dentro de los LLM es un enfoque central de la investigación en IA, cuyo objetivo es potenciar los modelos para llevar a cabo procesos de pensamiento secuencial. La mejora de esta área podría permitir aplicaciones más sólidas en diversos campos al permitir que los modelos naveguen a través de tareas de razonamiento complejas de forma independiente.
Un desafío persistente en el desarrollo de LLM es optimizar sus capacidades de razonamiento sin retroalimentación externa. Los LLM actuales se desempeñan bien en tareas relativamente simples, pero necesitan ayuda con el razonamiento secuencial o de varios pasos, donde se deriva una respuesta a través de una serie de pasos lógicos conectados. Esta limitación restringe la utilidad de los LLM en tareas que requieren una progresión lógica de ideas, como resolver problemas matemáticos complejos o analizar datos de forma estructurada. En consecuencia, desarrollar capacidades de razonamiento autosuficientes en los LLM se ha vuelto esencial para ampliar su funcionalidad y efectividad en tareas donde el razonamiento es clave.
Los investigadores han experimentado con varios métodos de tiempo de inferencia para abordar estos desafíos y mejorar el razonamiento. Un enfoque destacado es el estímulo de la Cadena de Pensamiento (CoT), que anima al modelo a dividir un problema complejo en partes manejables, tomando cada decisión paso a paso. Este método permite que los modelos sigan un enfoque estructurado hacia la resolución de problemas, lo que los hace más adecuados para tareas que requieren lógica y precisión. Otros enfoques, como el árbol del pensamiento y el programa del pensamiento, permiten a los LLM explorar múltiples caminos de razonamiento, proporcionando diversos enfoques para la resolución de problemas. Si bien son efectivos, estos métodos se centran principalmente en mejoras en el tiempo de ejecución y no mejoran fundamentalmente la capacidad de razonamiento durante la fase de entrenamiento del modelo.
Los investigadores de Salesforce AI Research han introducido un nuevo marco llamado LaTent Reasoning Optimization (LaTRO). LaTRO es un enfoque innovador que transforma el proceso de razonamiento en un problema de muestreo latente, ofreciendo una mejora intrínseca a las capacidades de razonamiento del modelo. Este marco permite a los LLM perfeccionar sus vías de razonamiento a través de un mecanismo de autorrecompensa, que les permite evaluar y mejorar sus respuestas sin depender de recompensas externas o comentarios supervisados. Al centrarse en una estrategia de superación personal, LaTRO mejora el rendimiento del razonamiento a nivel de entrenamiento, creando un cambio fundamental en la forma en que los modelos entienden y abordan tareas complejas.
La metodología de LaTRO se basa en muestrear rutas de razonamiento a partir de una distribución latente y optimizar estas rutas mediante técnicas variacionales. LaTRO utiliza un mecanismo único de autorrecompensa en su núcleo al muestrear múltiples rutas de razonamiento para una pregunta determinada. Cada ruta se evalúa en función de su probabilidad de producir una respuesta correcta, y luego el modelo ajusta sus parámetros para priorizar las rutas con mayores tasas de éxito. Este proceso iterativo permite que el modelo mejore simultáneamente su capacidad para generar rutas de razonamiento de calidad y evaluar la eficacia de estas rutas, fomentando así un ciclo continuo de superación personal. A diferencia de los enfoques convencionales, LaTRO no depende de modelos de recompensa externos, lo que lo convierte en un marco más autónomo y adaptable para mejorar el razonamiento en los LLM. Además, al trasladar la optimización del razonamiento a la fase de entrenamiento, LaTRO reduce efectivamente las demandas computacionales durante la inferencia, lo que la convierte en una solución que ahorra recursos.

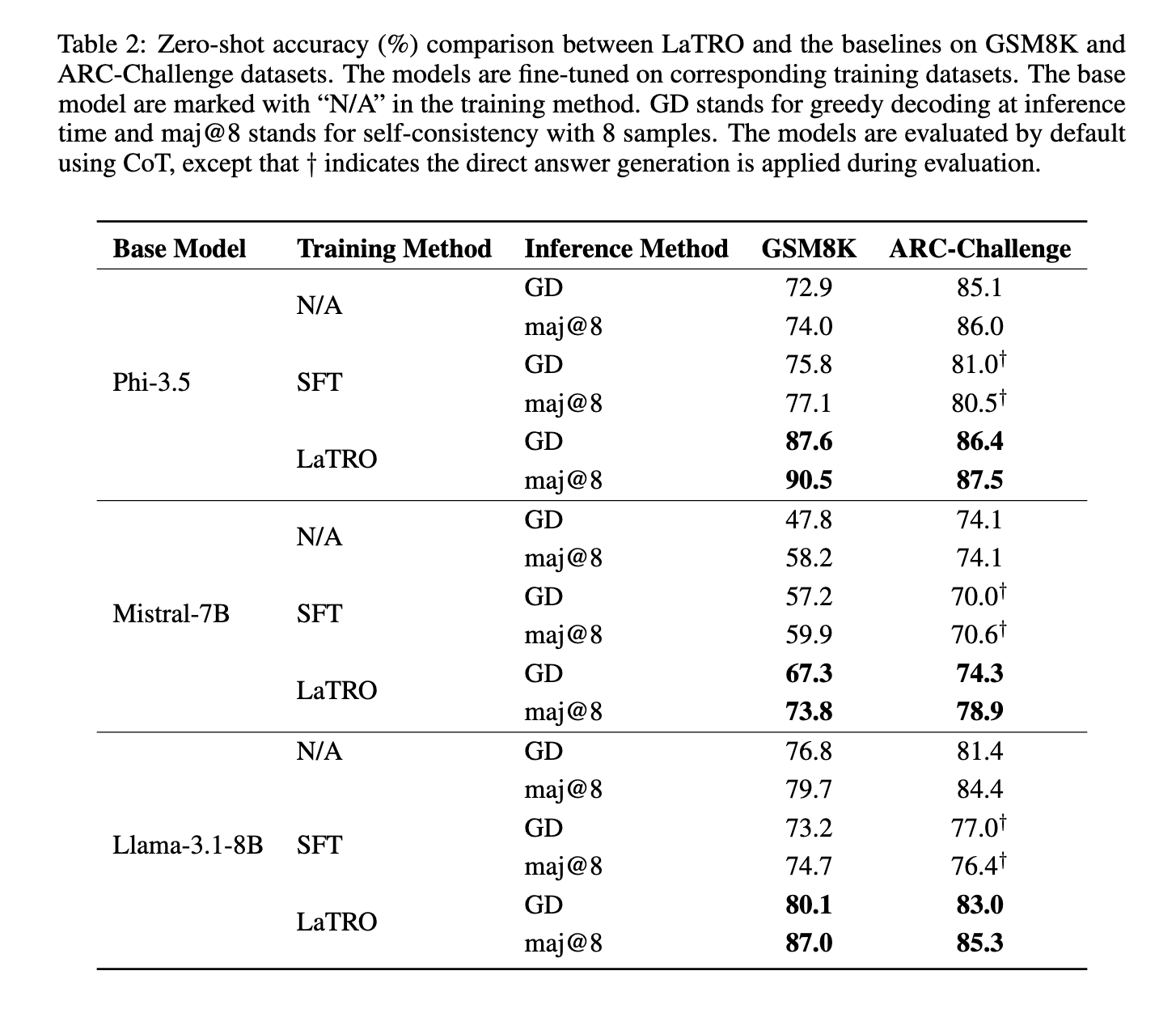
El rendimiento de LaTRO ha sido probado rigurosamente en varios conjuntos de datos, y los resultados subrayan su eficacia. Por ejemplo, en pruebas en el conjunto de datos GSM8K, que incluye desafíos de razonamiento basado en matemáticas, LaTRO demostró una mejora sustancial del 12,5% con respecto a los modelos base en precisión de disparo cero. Esta ganancia indica una marcada mejora en la capacidad de razonamiento del modelo sin requerir entrenamiento específico para la tarea. Además, LaTRO superó a los modelos de ajuste fino supervisados en un 9,6%, lo que demuestra su capacidad para ofrecer resultados más precisos manteniendo la eficiencia. En el conjunto de datos ARC-Challenge, que se centra en el razonamiento lógico, LaTRO volvió a superar tanto a los modelos básicos como a los mejorados, aumentando significativamente el rendimiento. Para Mistral-7B, una de las arquitecturas LLM utilizadas, la precisión del disparo cero en GSM8K mejoró del 47,8% en los modelos base al 67,3% en LaTRO con decodificación codiciosa. En las pruebas de autoconsistencia, donde se consideran múltiples caminos de razonamiento, LaTRO logró un aumento adicional de rendimiento, con una notable precisión del 90,5% para los modelos Phi-3.5 en GSM8K.
Además de los resultados cuantitativos, el mecanismo de autorrecompensa de LaTRO es evidente en sus mejoras cualitativas. El método enseña eficazmente a los LLM a evaluar rutas de razonamiento internamente, produciendo respuestas concisas y lógicamente coherentes. El análisis experimental revela que LaTRO permite a los LLM utilizar mejor su potencial de razonamiento latente, incluso en escenarios complejos, reduciendo así la dependencia de marcos de evaluación externos. Este avance tiene implicaciones para muchas aplicaciones, especialmente en campos donde la coherencia lógica y el razonamiento estructurado son esenciales.
En conclusión, LaTRO ofrece una solución innovadora y eficaz para mejorar el razonamiento LLM mediante una optimización autorrecompensada, estableciendo un nuevo estándar para la superación personal de los modelos. Este marco permite a los LLM previamente capacitados desbloquear su potencial latente en tareas de razonamiento centrándose en la mejora del razonamiento durante el tiempo de capacitación. Este avance de Salesforce AI Research destaca el potencial del razonamiento autónomo en los modelos de IA y demuestra que los LLM pueden evolucionar por sí mismos para convertirse en solucionadores de problemas más eficaces. LaTRO representa un importante salto adelante, ya que acerca la IA al logro de capacidades de razonamiento autónomo en varios dominios.
Mira el Página de papel y GitHub. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(SEMINARIO WEB GRATUITO sobre IA) Implementación del procesamiento inteligente de documentos con GenAI en servicios financieros y transacciones inmobiliarias
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.
🐝🐝 Próximo evento en vivo de LinkedIn, ‘Una plataforma, posibilidades multimodales’, donde el director ejecutivo de Encord, Eric Landau, y el director de ingeniería de productos, Justin Sharps, hablarán sobre cómo están reinventando el proceso de desarrollo de datos para ayudar a los equipos a construir rápidamente modelos de IA multimodales innovadores.